Seifedine Kadry - Big Data
Здесь есть возможность читать онлайн «Seifedine Kadry - Big Data» — ознакомительный отрывок электронной книги совершенно бесплатно, а после прочтения отрывка купить полную версию. В некоторых случаях можно слушать аудио, скачать через торрент в формате fb2 и присутствует краткое содержание. Жанр: unrecognised, на английском языке. Описание произведения, (предисловие) а так же отзывы посетителей доступны на портале библиотеки ЛибКат.

- Название:Big Data
- Автор:
- Жанр:
- Год:неизвестен
- ISBN:нет данных
- Рейтинг книги:3 / 5. Голосов: 1
-
Избранное:Добавить в избранное
- Отзывы:
-
Ваша оценка:
Big Data: краткое содержание, описание и аннотация
Предлагаем к чтению аннотацию, описание, краткое содержание или предисловие (зависит от того, что написал сам автор книги «Big Data»). Если вы не нашли необходимую информацию о книге — напишите в комментариях, мы постараемся отыскать её.
Big Data Accessibly organized,
includes illuminating case studies throughout the material, showing you how the included concepts have been applied in real-world settings. Some of those concepts include:
The common challenges facing big data technology and technologists, like data heterogeneity and incompleteness, data volume and velocity, storage limitations, and privacy concerns Relational and non-relational databases, like RDBMS, NoSQL, and NewSQL databases Virtualizing Big Data through encapsulation, partitioning, and isolating, as well as big data server virtualization Apache software, including Hadoop, Cassandra, Avro, Pig, Mahout, Oozie, and Hive The Big Data analytics lifecycle, including business case evaluation, data preparation, extraction, transformation, analysis, and visualization Perfect for data scientists, data engineers, and database managers,
also belongs on the bookshelves of business intelligence analysts who are required to make decisions based on large volumes of information. Executives and managers who lead teams responsible for keeping or understanding large datasets will also benefit from this book.
Big Data — читать онлайн ознакомительный отрывок
Ниже представлен текст книги, разбитый по страницам. Система сохранения места последней прочитанной страницы, позволяет с удобством читать онлайн бесплатно книгу «Big Data», без необходимости каждый раз заново искать на чём Вы остановились. Поставьте закладку, и сможете в любой момент перейти на страницу, на которой закончили чтение.
Интервал:
Закладка:
1 Give some examples of big data. Facebook is generating approximately 500 terabytes of data per day, about 10 terabytes of sensor data are generated every 30 minutes by airlines, the New York Stock Exchange is generating approximately 1 terabyte of data per day. These are examples of big data.
2 How is big data analysis useful for organizations? Big data analytics is useful for the organizations to make better decisions, find new business opportunities, compete against business rivals, improve performance and efficiency, and reduce cost by using advanced data analytics techniques.
2 Big Data Storage Concepts
CHAPTER OBJECTIVE
The various storage concepts of big data, namely, clusters and file system are given a brief overview. The data replication, which has made big the data storage concept a fault tolerant system is explained with master‐slave and peer‐peer types of replications. Various storage types of on‐disk storage are briefed. Scalability techniques, namely, scaling up and scaling out, adopted by various database systems are overviewed.
In big data storage, architecture data reaches users through multiple organization data structures. The big data revolution provides significant improvements to the data storage architecture. New tools such as Hadoop, an open‐source framework for storing data on clusters of commodity hardware, are developed, which allows organizations to effectively store and analyze large volumes of data.
In Figure 2.1the data from the source flow through Hadoop, which acts as an online archive. Hadoop is highly suitable for unstructured and semi‐structured data. However, it is also suitable for some structured data, which are expensive to be stored and processed in traditional storage engines (e.g., call center records). The data stored in Hadoop is then fed into a data warehouse, which distributes the data to data marts and other systems in the downstream where the end users can query the data using query tools and analyze the data.
In modern BI architecture the raw data stored in Hadoop can be analyzed using MapReduce programs. MapReduce is the programming paradigm of Hadoop. It can be used to write applications to process the massive data stored in Hadoop.
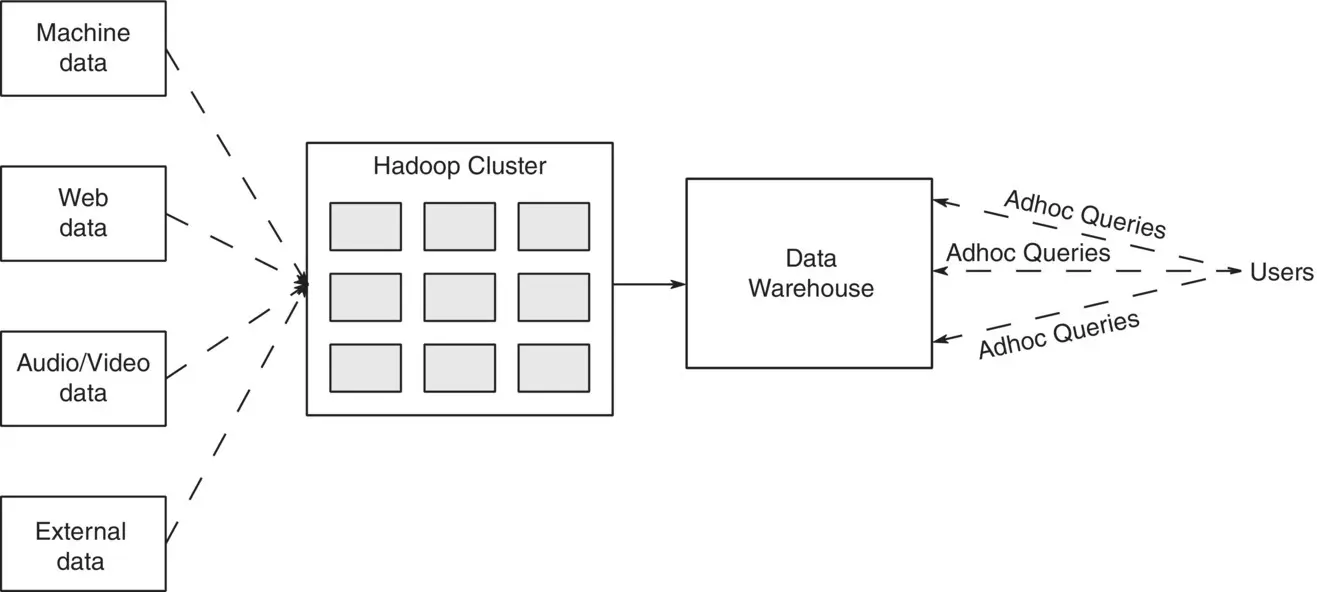
Figure 2.1 Big data storage architecture.
2.1 Cluster Computing
Cluster computing is a distributed or parallel computing system comprising multiple stand‐alone PCs connected together working as a single, integrated, highly available resource. Multiple computing resources are connected together in a cluster to constitute a single larger and more powerful virtual computer with each computing resource running an instance of the OS. The cluster components are connected together through local area networks (LANs). Cluster computing technology is used for high availability as well as load balancing with better system performance and reliability. The benefits of massively parallel processors and cluster computers are high availability, scalable performance, fault tolerance, and the use of cost‐effective commodity hardware. Scalability is achieved by removing nodes or adding additional nodes as per the demand without hindering the system operation. A cluster of systems connects together a group of systems to share critical computational tasks. The servers in a cluster are called nodes. Cluster computing can be client‐server architecture or a peer‐peer model. It provides high‐speed computational power for processing data‐intensive applications related to big data technologies. Cluster computing with distributed computation infrastructure provides fast and reliable data processing power to gigantic‐sized big data solutions with integrated and geographically separated autonomous resources. They make a cost‐effective solution to big data as they do allow multiple applications to share the computing resources. They are flexible to add more computing resources as required by the big data technology. The clusters are capable of changing the size dynamically, they shrink when any server shuts down or grow in size when additional servers are added to handle more load. They survive the failures with no or minimal impact. Clusters adopt a failover mechanism to eliminate the service interruptions. Failover is the process of switching to a redundant node upon the abnormal termination or failure of a previously active node. Failover is an automatic mechanism that does not require any human intervention, which differentiates it from the switch‐over operation.
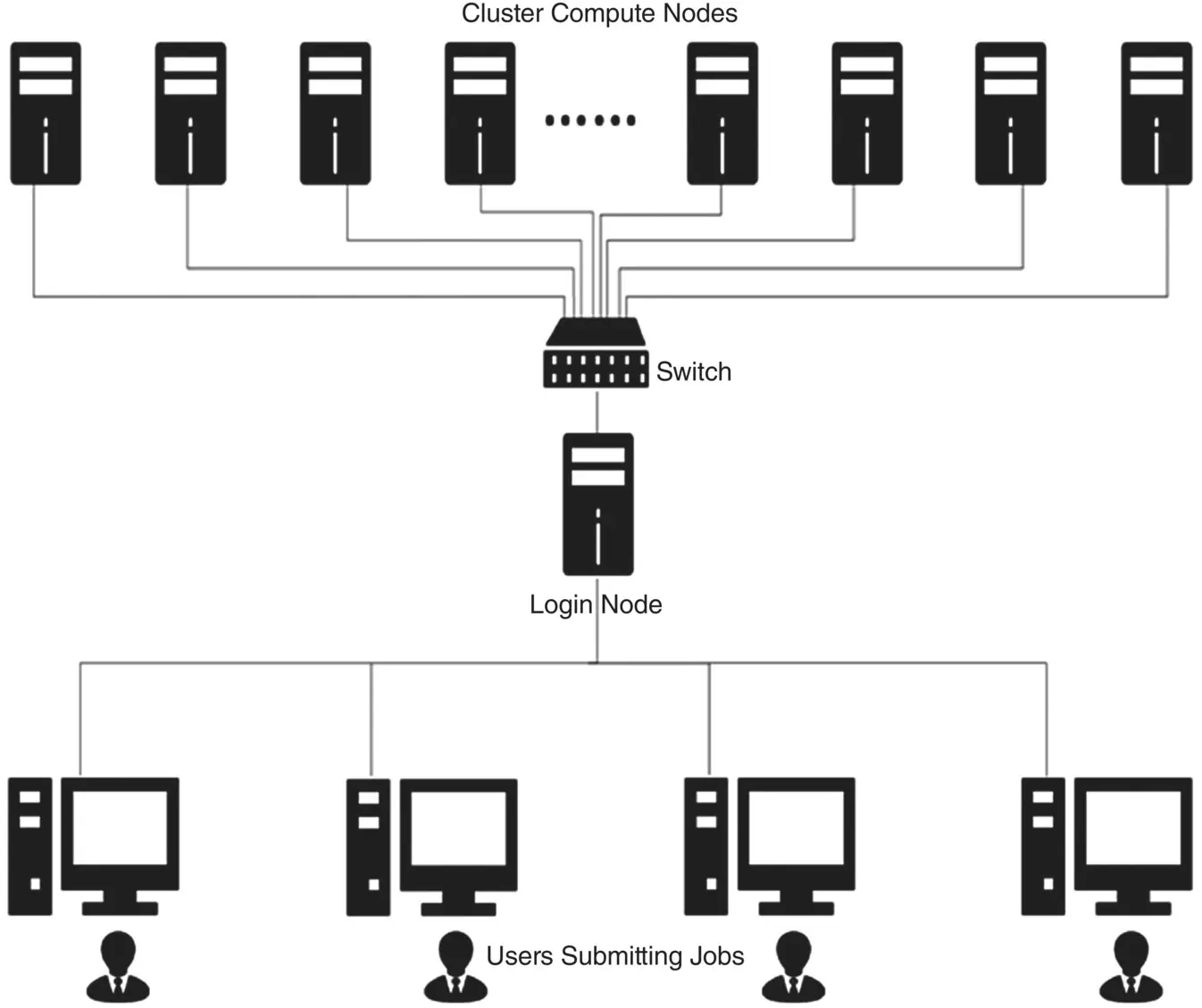
Figure 2.2 Cluster computing.
Figure 2.2shows the overview of cluster computing. Multiple stand‐alone PCs connected together through a dedicated switch. The login node acts as the gateway into the cluster. When the cluster has to be accessed by the users from a public network, the user has to login to the login node. This is to prevent unauthorized access by the users. Cluster computing has a master‐slave model and a peer‐to‐peer model. There are two major types of clusters, namely, high‐availability cluster and load‐balancing cluster. Cluster types are briefed in the following section.
2.1.1 Types of Cluster
Clusters may be configured for various purposes such as web‐based services or computational‐intensive workloads. Based on their purpose, the clusters may be classified into two major types:
High availability
Load balancing
When the availability of the system is of high importance in case of failure of the nodes, high‐availability clusters are used. When the computational workload has to be shared among the cluster nodes, load‐balancing clusters are used to improvise the overall performance. Thus, computer clusters are configured based on the business purpose needs.
2.1.1.1 High Availability Cluster
High availability clusters are designed to minimize downtime and provide uninterrupted service when nodes fail. Nodes in a highly available cluster must have access to a shared storage. Such systems are often used for failover and backup purposes. Without clustering the nodes if the server running an application goes down, the application will not be available until the server is up again. In a highly available cluster, if a node becomes inoperative, continuous service is provided by failing over service from the inoperative cluster node to another, without administrative intervention. Such clusters must maintain data integrity while failing over the service from one cluster node to another. High availability systems consist of several nodes that communicate with each other and share information. High availability makes the system highly fault tolerant with many redundant nodes, which sustain faults and failures. Such systems also ensure high reliability and scalability. The higher the redundancy, the higher the availability. A highly available system eliminates single point of failures.
Highly available systems are essential for an organization that has to protect its business against loss of transactional data or incomplete data and overcome the risk of system outage. These risks, under certain circumstances, are bound to cause millions of dollars of losses to the business. Certain applications such as online platforms may face sudden increase in traffic. To manage these traffic spikes a robust solution such as cluster computing is required. Billing, banking, and e‐commerce demand a system that is highly available with zero loss of transactional data.
Читать дальшеИнтервал:
Закладка:
Похожие книги на «Big Data»
Представляем Вашему вниманию похожие книги на «Big Data» списком для выбора. Мы отобрали схожую по названию и смыслу литературу в надежде предоставить читателям больше вариантов отыскать новые, интересные, ещё непрочитанные произведения.



![Алексей Благирев - Big data простым языком [litres]](/books/416853/aleksej-blagirev-big-data-prostym-yazykom-litres-thumb.webp)








Обсуждение, отзывы о книге «Big Data» и просто собственные мнения читателей. Оставьте ваши комментарии, напишите, что Вы думаете о произведении, его смысле или главных героях. Укажите что конкретно понравилось, а что нет, и почему Вы так считаете.