Seifedine Kadry - Big Data
Здесь есть возможность читать онлайн «Seifedine Kadry - Big Data» — ознакомительный отрывок электронной книги совершенно бесплатно, а после прочтения отрывка купить полную версию. В некоторых случаях можно слушать аудио, скачать через торрент в формате fb2 и присутствует краткое содержание. Жанр: unrecognised, на английском языке. Описание произведения, (предисловие) а так же отзывы посетителей доступны на портале библиотеки ЛибКат.

- Название:Big Data
- Автор:
- Жанр:
- Год:неизвестен
- ISBN:нет данных
- Рейтинг книги:3 / 5. Голосов: 1
-
Избранное:Добавить в избранное
- Отзывы:
-
Ваша оценка:
Big Data: краткое содержание, описание и аннотация
Предлагаем к чтению аннотацию, описание, краткое содержание или предисловие (зависит от того, что написал сам автор книги «Big Data»). Если вы не нашли необходимую информацию о книге — напишите в комментариях, мы постараемся отыскать её.
Big Data Accessibly organized,
includes illuminating case studies throughout the material, showing you how the included concepts have been applied in real-world settings. Some of those concepts include:
The common challenges facing big data technology and technologists, like data heterogeneity and incompleteness, data volume and velocity, storage limitations, and privacy concerns Relational and non-relational databases, like RDBMS, NoSQL, and NewSQL databases Virtualizing Big Data through encapsulation, partitioning, and isolating, as well as big data server virtualization Apache software, including Hadoop, Cassandra, Avro, Pig, Mahout, Oozie, and Hive The Big Data analytics lifecycle, including business case evaluation, data preparation, extraction, transformation, analysis, and visualization Perfect for data scientists, data engineers, and database managers,
also belongs on the bookshelves of business intelligence analysts who are required to make decisions based on large volumes of information. Executives and managers who lead teams responsible for keeping or understanding large datasets will also benefit from this book.
Big Data — читать онлайн ознакомительный отрывок
Ниже представлен текст книги, разбитый по страницам. Система сохранения места последней прочитанной страницы, позволяет с удобством читать онлайн бесплатно книгу «Big Data», без необходимости каждый раз заново искать на чём Вы остановились. Поставьте закладку, и сможете в любой момент перейти на страницу, на которой закончили чтение.
Интервал:
Закладка:
2.1.1.2 Load Balancing Cluster
Load‐balancing clusters are designed to distribute workloads across different cluster nodes to share the service load among the nodes. If a node in a load‐balancing cluster goes down, the load from that node is switched over to another node. This is achieved by having identical copies of data across all the nodes, so the remaining nodes can share the increase in load. The main objective of load balancing is to optimize the use of resources, minimize response time, maximize throughput, and avoid overload on any one of the resources. The resources are used efficiently in this kind of cluster algorithm as there is a good amount of control over the way in which the requests are routed. This kind of routing is essential when the cluster is composed of machines that are not equally efficient; in that case, low‐performance machines are assigned a lesser share of work. Instead of having a single, very expensive and very powerful server, load balancing can be used to share the load across several inexpensive, low performing systems for better scalability.
Round robin load balancing, weight‐based load balancing, random load balancing, and server affinity load balancing are examples of load balancing. Round robin load balancing chooses server from the top server in the list in sequential order until the last server in the list is chosen. Once the last server is chosen it resets back to the top. The weight‐based load balancing algorithm takes into account the previously assigned weight for each server. The weight field will be assigned a numerical value between 1 and 100, which determines the proportion of the load the server can bear with respect to other servers. If the servers bear equal weight, an equal proportion of the load is distributed among the servers. Random load balancing routes requests to servers at random. Random load balancing is suitable only for homogenous clusters, where the machines are similarly configured. A random routing of requests does not allow for differences among the machines in their processing power. Server affinity load balancing is the ability of the load balancer to remember the server where the client initiated the request and to route the subsequent requests to the same server.
2.1.2 Cluster Structure
In a basic cluster structure, a group of computers are linked and work together as a single computer. Clusters are deployed to improve performance and availability. Based on how these computers are linked together, cluster structure is classified into two types:
Symmetric clusters
Asymmetric clusters
Symmetric cluster is a type of cluster structure in which each node functions as an individual computer capable of running applications. The symmetric cluster setup is simple and straightforward. A sub‐network is created with individual machines or machines can be added to an existing network and cluster‐specific software can be installed to it. Additional machines can be added as needed. Figure 2.3shows a symmetric cluster.
Asymmetric clusters are a type of cluster structure in which one machine acts as the head node, and it serves as the gateway between the user and the remaining nodes. Figure 2.4shows an asymmetric cluster.
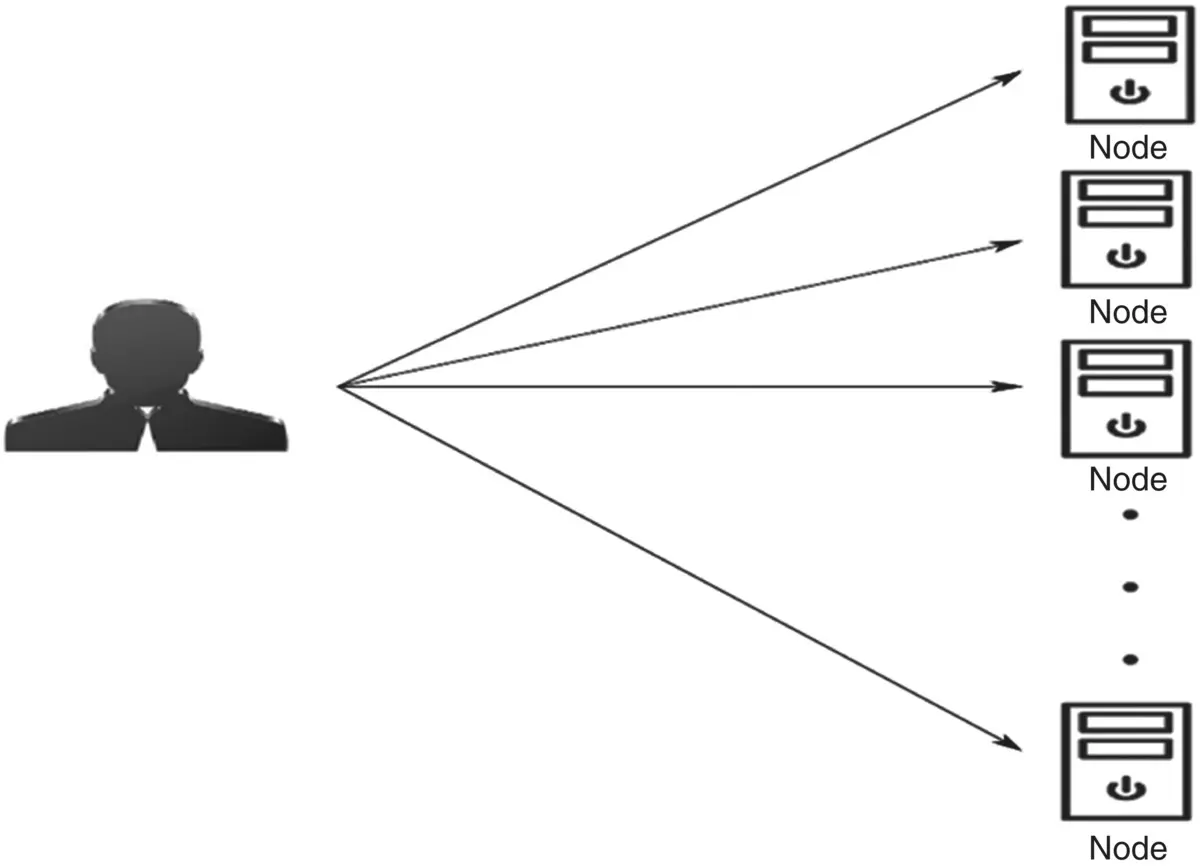
Figure 2.3 Symmetric clusters.
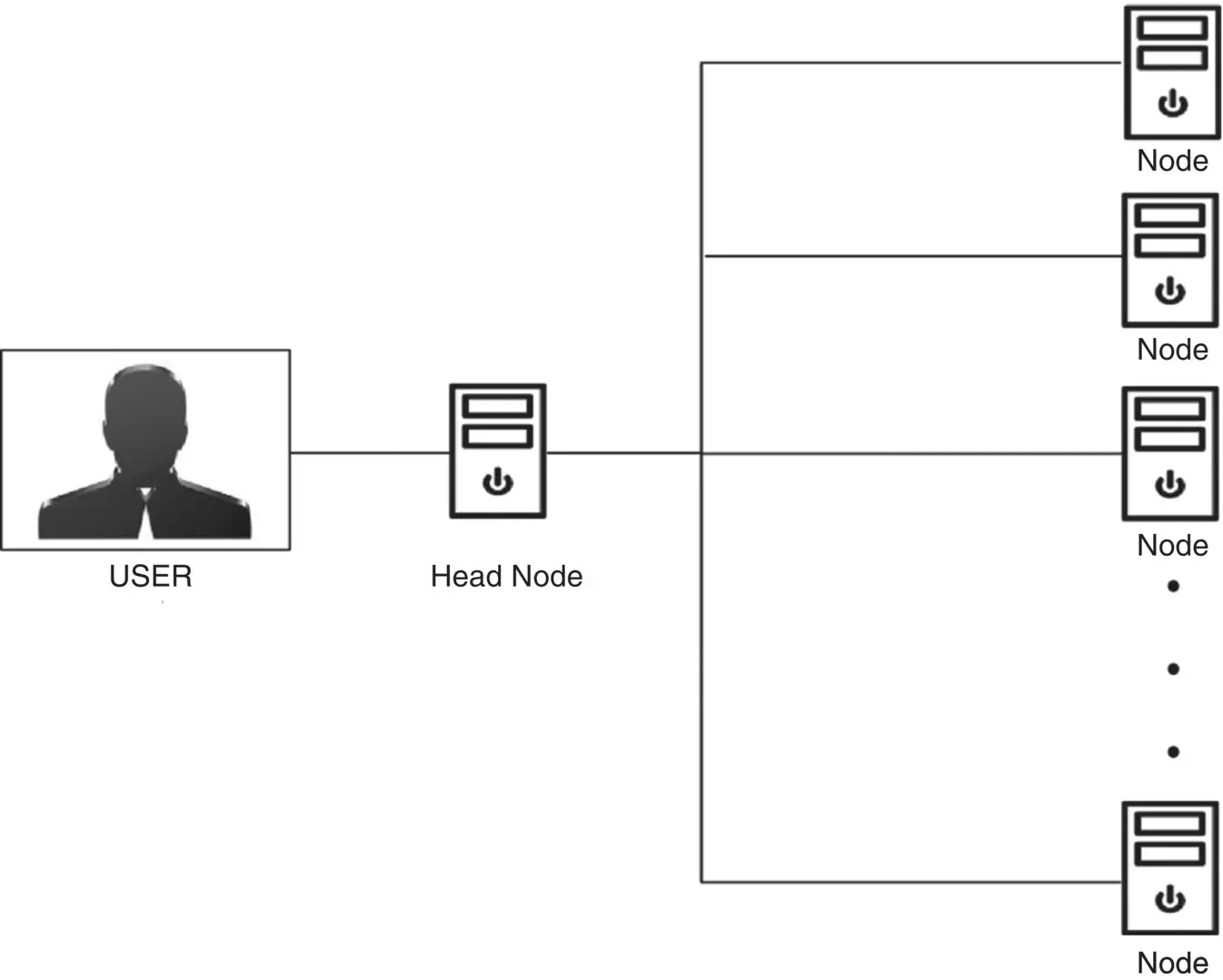
Figure 2.4 Asymmetric cluster.
2.2 Distribution Models
The main reason behind distributing data over a large cluster is to overcome the difficulty and to cut the cost of buying expensive servers. There are several distribution models with which an increase in data volume and large volumes of read or write requests can be handled, and the network can be made highly available. The downside of this type of architecture is the complexity it introduces with the increase in the number of computers added to the cluster. Replication and sharding are the two major techniques of data distribution. Figure 2.5shows the distribution models.
Replication—Replication is the process of placing the same set of data over multiple nodes. Replication can be performed using a peer‐to‐peer model or a master‐slave model.
Sharding—Sharding is the process of placing different sets of data on different nodes.
Sharding and Replication—Sharding and replication can either be used alone or together.
2.2.1 Sharding
Sharding is the process of partitioning very large data sets into smaller and easily manageable chunks called shards. The partitioned shards are stored by distributing them across multiple machines called nodes. No two shards of the same file are stored in the same node, each shard occupies separate nodes, and the shards spread across multiple nodes collectively constitute the data set.
Figure 2.6a shows that a 1 GB data block is split up into four chunks each of 256 MB. When the size of the data increases, a single node may be insufficient to store the data. With sharding more nodes are added to meet the demands of the massive data growth. Sharding reduces the number of transaction each node handles and increases throughput. It reduces the data each node needs to store.
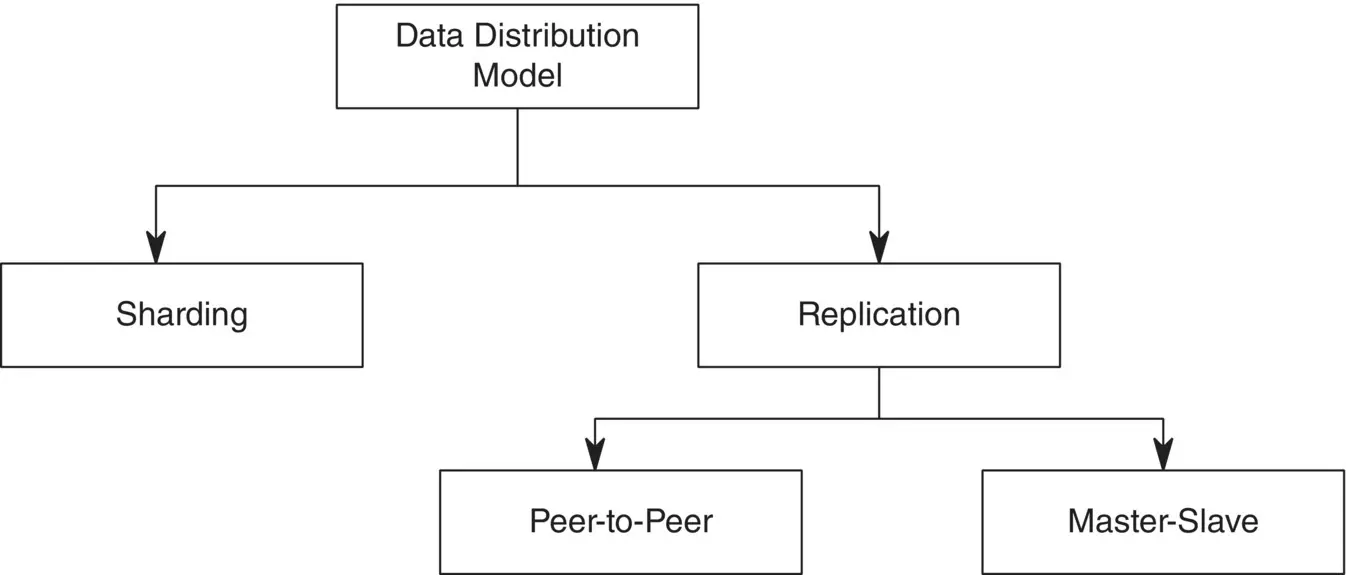
Figure 2.5 Distribution model.
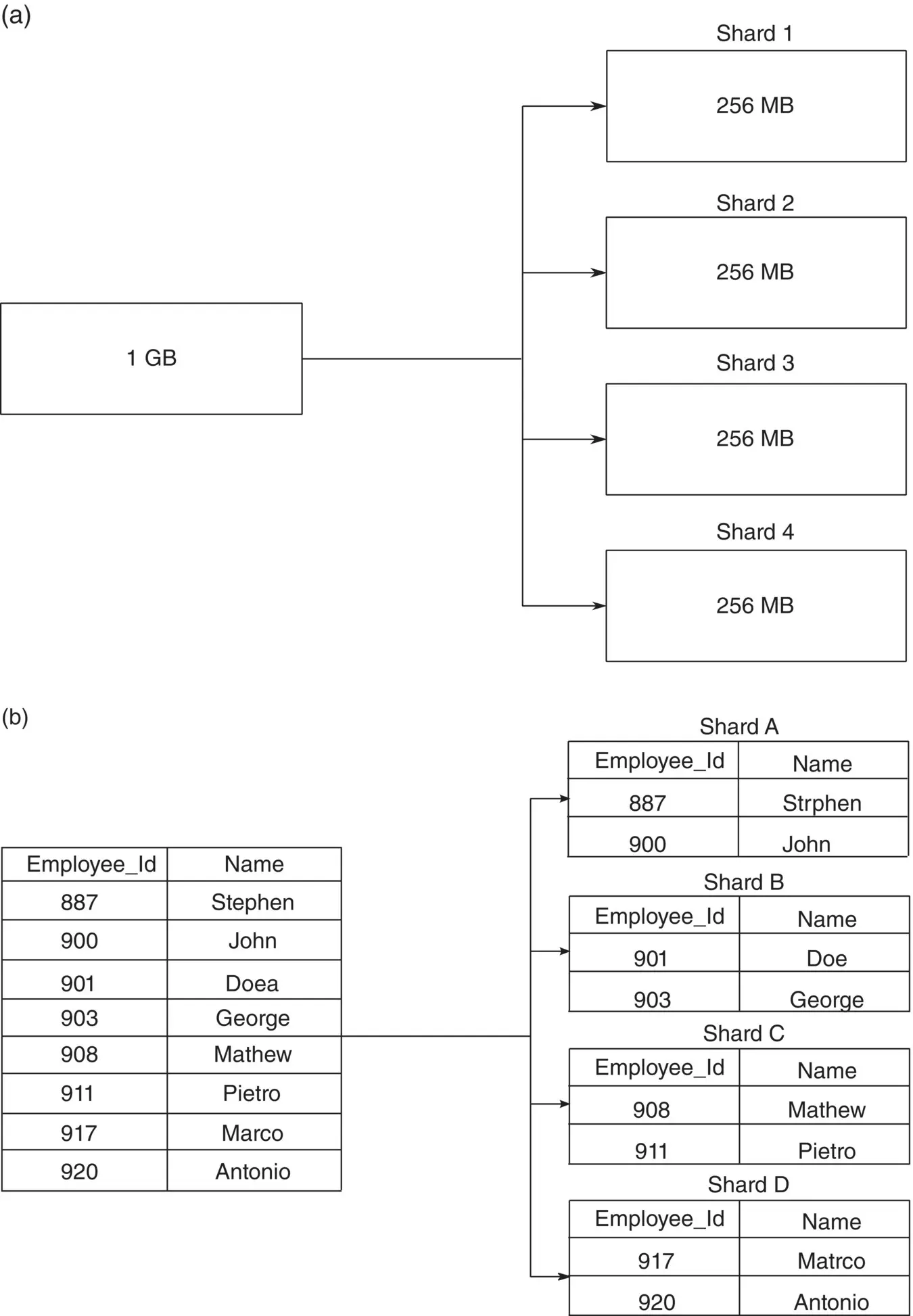
Figure 2.6 (a) Sharding. (b) Sharding example.
Figure 2.6b shows an example as how a data block is split up into shards across multiple nodes. A data set with employee details is split up into four small blocks: shard A, shard B, shard C, shard D and stored across four different nodes: node A, node B, node C, and node D. Sharding improves the fault tolerance of the system as the failure of a node affects only the block of the data stored in that particular node.
2.2.2 Data Replication
Replication is the process of creating copies of the same set of data across multiple servers. When a node crashes, the data stored in that node will be lost. Also, when a node is down for maintenance, the node will not be available until the maintenance process is over. To overcome these issues, the data block is copied across multiple nodes. This process is called data replication, and the copy of a block is called replica. Figure 2.7shows data replication.
Replication makes the system fault tolerant since the data is not lost when an individual node fails as the data is redundant across the nodes. Replication increases the data availability as the same copy of data is available across multiple nodes. Figure 2.8illustrates that the same data is replicated across node A, node B, and node C. Data replication is achieved through the master‐slave and peer‐peer models.
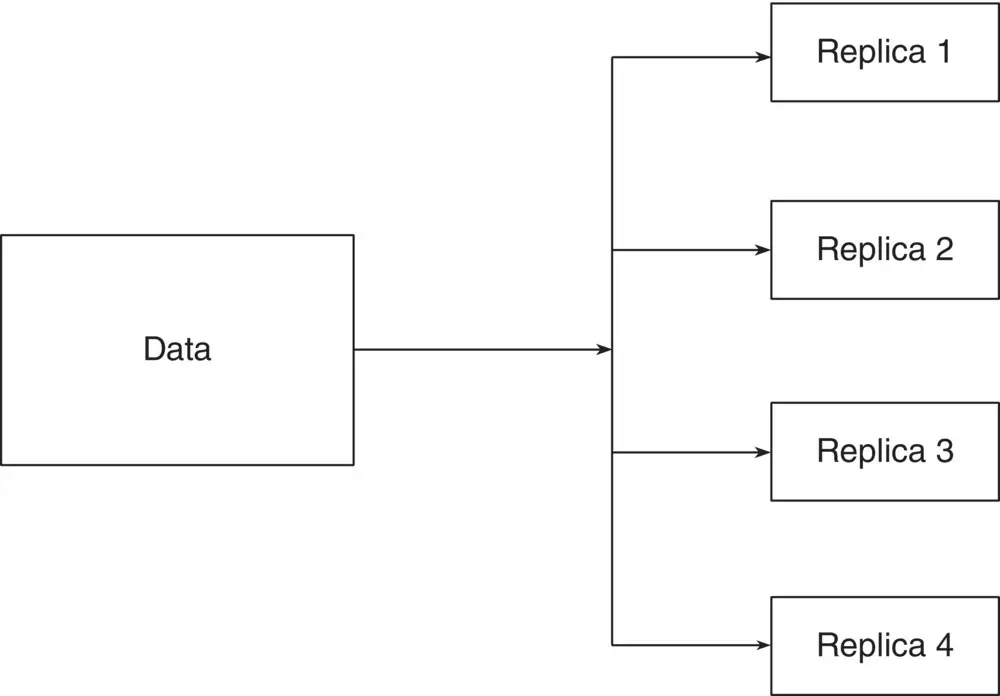
Figure 2.7 Replication.
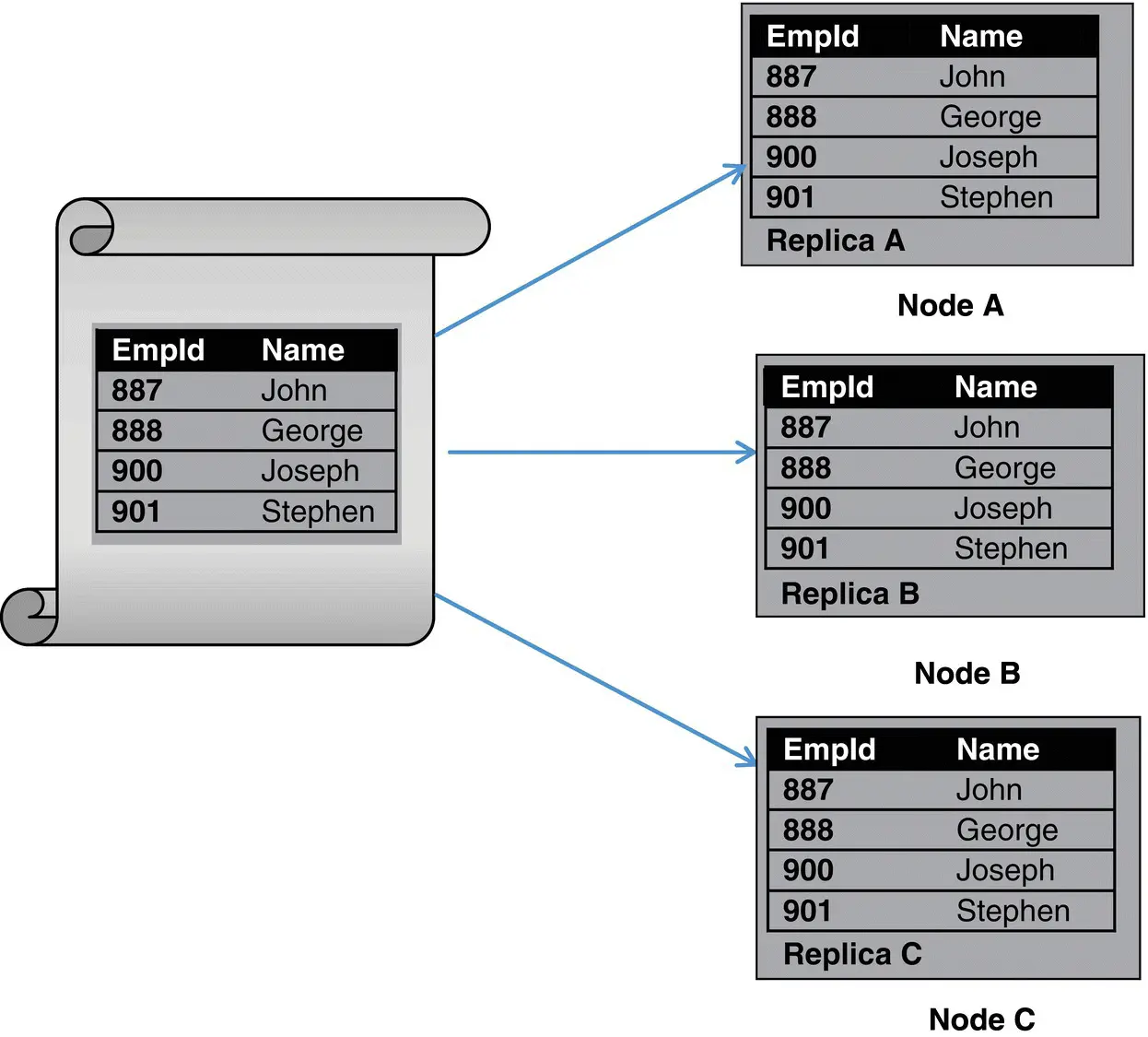
Figure 2.8 Data replication.
Читать дальшеИнтервал:
Закладка:
Похожие книги на «Big Data»
Представляем Вашему вниманию похожие книги на «Big Data» списком для выбора. Мы отобрали схожую по названию и смыслу литературу в надежде предоставить читателям больше вариантов отыскать новые, интересные, ещё непрочитанные произведения.



![Алексей Благирев - Big data простым языком [litres]](/books/416853/aleksej-blagirev-big-data-prostym-yazykom-litres-thumb.webp)








Обсуждение, отзывы о книге «Big Data» и просто собственные мнения читателей. Оставьте ваши комментарии, напишите, что Вы думаете о произведении, его смысле или главных героях. Укажите что конкретно понравилось, а что нет, и почему Вы так считаете.