Daniel J. Denis - Applied Univariate, Bivariate, and Multivariate Statistics
Здесь есть возможность читать онлайн «Daniel J. Denis - Applied Univariate, Bivariate, and Multivariate Statistics» — ознакомительный отрывок электронной книги совершенно бесплатно, а после прочтения отрывка купить полную версию. В некоторых случаях можно слушать аудио, скачать через торрент в формате fb2 и присутствует краткое содержание. Жанр: unrecognised, на английском языке. Описание произведения, (предисловие) а так же отзывы посетителей доступны на портале библиотеки ЛибКат.

- Название:Applied Univariate, Bivariate, and Multivariate Statistics
- Автор:
- Жанр:
- Год:неизвестен
- ISBN:нет данных
- Рейтинг книги:5 / 5. Голосов: 1
-
Избранное:Добавить в избранное
- Отзывы:
-
Ваша оценка:
Applied Univariate, Bivariate, and Multivariate Statistics: краткое содержание, описание и аннотация
Предлагаем к чтению аннотацию, описание, краткое содержание или предисловие (зависит от того, что написал сам автор книги «Applied Univariate, Bivariate, and Multivariate Statistics»). Если вы не нашли необходимую информацию о книге — напишите в комментариях, мы постараемся отыскать её.
contains an accessible introduction to statistical modeling techniques commonly used in the social and behavioral sciences. The text offers a blend of statistical theory and methodology and reviews both the technical and theoretical aspects of good data analysis.
Featuring applied resources at various levels, the book includes statistical techniques using software packages such as R and SPSS®. To promote a more in-depth interpretation of statistical techniques across the sciences, the book surveys some of the technical arguments underlying formulas and equations. The thoroughly updated edition includes new chapters on nonparametric statistics and multidimensional scaling, and expanded coverage of time series models. The second edition has been designed to be more approachable by minimizing theoretical or technical jargon and maximizing conceptual understanding with easy-to-apply software examples. This important text:
Offers demonstrations of statistical techniques using software packages such as R and SPSS® Contains examples of hypothetical and real data with statistical analyses Provides historical and philosophical insights into many of the techniques used in modern social science Includes a companion website that includes further instructional details, additional data sets, solutions to selected exercises, and multiple programming options Written for students of social and applied sciences,
offers a text to statistical modeling techniques used in social and behavioral sciences.
Applied Univariate, Bivariate, and Multivariate Statistics — читать онлайн ознакомительный отрывок
Ниже представлен текст книги, разбитый по страницам. Система сохранения места последней прочитанной страницы, позволяет с удобством читать онлайн бесплатно книгу «Applied Univariate, Bivariate, and Multivariate Statistics», без необходимости каждый раз заново искать на чём Вы остановились. Поставьте закладку, и сможете в любой момент перейти на страницу, на которой закончили чтение.
Интервал:
Закладка:
Relativity is a benchmark used to evaluate much phenomena, from intelligence to scholastic achievement to prevalence of depression, and indeed much of human and nonhuman behavior. Understanding that events witnessed could be theorized to have come from known distributions (like the talent distribution of pilots) is a first step to thinking statistically. Most phenomena have distributions, either known or unknown. Statistics, in large part, is a study of such distributions.
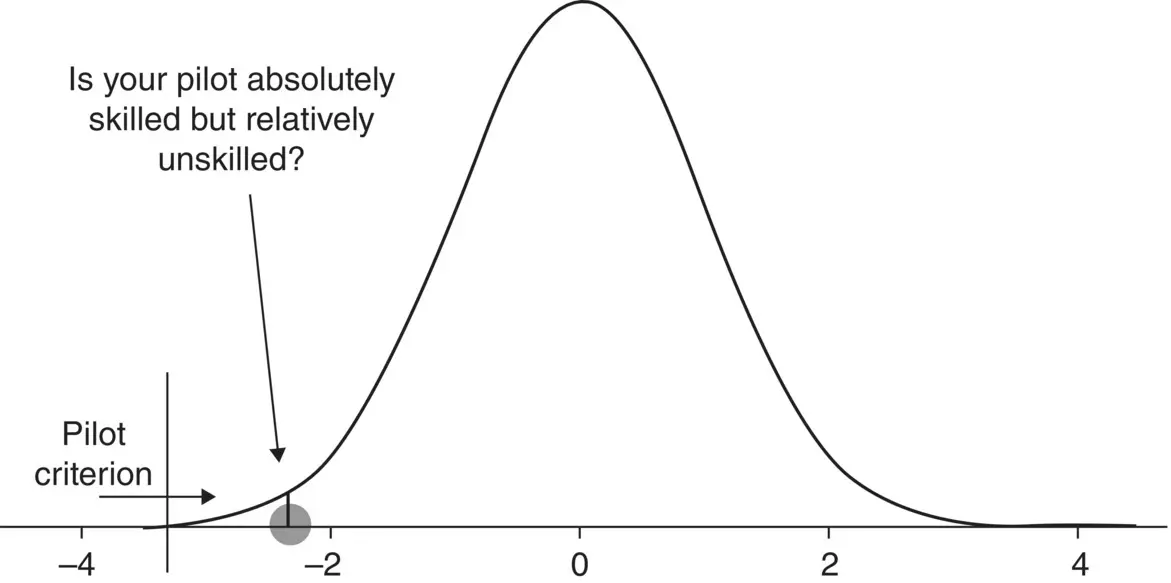
Figure 1.5The “pilot criterion” must be met for any pilot to be permitted to fly your plane. However, of those skilled enough to fly, your pilot may still lay at the lower end of the curve. That is, your pilot may be absolutely good, but relatively poor in terms of skill.
1.9 EXPERIMENTAL VERSUS STATISTICAL CONTROL
Perhaps most pervasive in the social science literature is the implicit belief held by many that methods such as regressionand analysis of covarianceallow one to “control” variables that would otherwise not be controllable in the nonexperimental design. As is emphasized throughout this book, statistical methods, whatever the kind, do not provide methods of controlling variables, or “holding variables constant” as it were. Not in the real way. To get these kinds of effects, you usually need a strong and rigorous bullet‐proof experimental design.
It is true, however, that statistical methods do afford a method, in some sense, for presuming (or guessing) what might have beenhad controls been put into place. For instance, if we analyze the correlation between weight and height, it may make sense to hold a factor such as age “constant.” That is, we may wish to partial outage. However, partialling out the variability due to age in the bivariate correlation is not equivalent to actually controllingfor age. The truth of the matter is that our statistical control is telling us nothing about what would actually be the case had we been able to truly control age, or any other factor. As will be elaborated on in Chapter 8on multiple regression, statistical control is not a sufficient “proxy” whatsoever for experimental control. Students and researchers must keep this distinction in mind before they throw variables into a statistical model and employ words like “control” (or other powerand actionwords) when interpreting effects. If you want to truly control variables, to actually hold them constant, you usually have to do experiments. Estimating parameters in a statistical model, confident that you have “controlled” for covariates, is simply not enough.
1.10 STATISTICAL VERSUS PHYSICAL EFFECTS
In the establishment of evidence, either experimental or nonexperimental, it is helpful to consider the distinction between statisticalversus physicaleffects. To illustrate, consider a medical scientist who wishes to test the hypothesis that the more medication applied to a wound, the faster the wound heals. The statistical question of interest is— Does amount of medication predict the rate at which a wound heals?A useful statistical model might be a linear regression where amount of medication is the predictor and rate of healing is the response. Of course, one does not “need” a regression analysis to “know” whether something is occurring. The investigator can simply observe whether the wound heals or not, and whether applying more or less medication speeds up or slows down the healing process. The statistical tool in this case is simply used to modelthe relationship, not determinewhether or not it exists. The variable in question is a physical, biological, “real” phenomenon. It exists independent of the statistical model, simply because we can see it. The estimation of a statistical model is not necessarily the same as the hypothesized underlying physical process it is seeking to represent.
In some areas of social science, however, the very observance of an effect cannot be realized without recourse to the statistics used to model the relationship. For instance, if I correlate self‐esteem to intelligence, am I modeling a relationship that I know exists separate from the statistical model, or, is the statistical model the only recourse I have to say that the relationship exists in the first place? Because of mediatingand moderatingrelationships in social statistics, an additional variable or two could drastically modify existing coefficients in a model to the point where predictors that had an effect before such inclusion no longer do after. As we will emphasize in our chapters on regression:
When you change the model, you change parameter estimates, you change effects. You are never, ever, testing individual effects in the model. You are always testing the model, and hence the interpretation of parameter estimates must be within the context of the model.
This is one of the general problems of purely correlational research with nonphysical or “nonorganic” variables. It may be more an exercise in variance partitioningthan it is in analyzing “true” substantive effects, since the effects in question may be simply statistical artifacts. They may have little other bases. Granted, even working with physical or biological variables this can be a problem, but it does not rear its head nearly as much. To reiterate, when we model a physical relationship, we have recourse to that physical relationship independent of the statistical model, because we have evidence that the physical relationship exists independent of the model. If we lost our modeling software, we could still “see” the phenomenon. In many models of social phenomena, however, the addition of one or two covariates in the model can make the relationship of most interest “disappear” and because of the nature of measured variables, we may no longer have physical recourse to justify the original relationship at all, external to the statistical model. This is why social models can be very “neurotic,” frustrating, and context‐dependent. Self‐esteem may predict achievement in one model, but in another, it does not. Many areas of psychological, political, and economic research, for instance, implicitly operate on such grounds. The existence of phenomena is literally “built” on the existence of the statistical model and often does not necessarily exist separate from it, or at least not in an easily observed manner such as the healing of a wound. Social scientists working in such areas, if nothing else, must be aware of this. Estimating a statistical model may or may not correspond to actual physical effects it is seeking to account for.
1.11 UNDERSTANDING WHAT “APPLIED STATISTICS” MEANS
In this day and age of extraordinary computing power, the likes of which will probably seem laughable in even a decade from the date of publication of this book, with a few clicks of the mouse and a software manual, one can obtain a principal components analysis, factor analysis, discriminant analysis, multiple regression, and a host of other relatively theoretically advanced statistical techniques in a matter of seconds. The advance of computers and especially easy‐to‐use software programs has made performing statistical analyses seemingly quite easy because even a novice can obtain output from a statistical procedure relatively quickly. One consequence of this however is that there seems to have arisen a misunderstanding in some circles that “applied statistics” somehow equates with the idea of “statistics without mathematics” or even worse, “statistics via software.”
Читать дальшеИнтервал:
Закладка:
Похожие книги на «Applied Univariate, Bivariate, and Multivariate Statistics»
Представляем Вашему вниманию похожие книги на «Applied Univariate, Bivariate, and Multivariate Statistics» списком для выбора. Мы отобрали схожую по названию и смыслу литературу в надежде предоставить читателям больше вариантов отыскать новые, интересные, ещё непрочитанные произведения.












Обсуждение, отзывы о книге «Applied Univariate, Bivariate, and Multivariate Statistics» и просто собственные мнения читателей. Оставьте ваши комментарии, напишите, что Вы думаете о произведении, его смысле или главных героях. Укажите что конкретно понравилось, а что нет, и почему Вы так считаете.