The Handbook of Speech Perception
Здесь есть возможность читать онлайн «The Handbook of Speech Perception» — ознакомительный отрывок электронной книги совершенно бесплатно, а после прочтения отрывка купить полную версию. В некоторых случаях можно слушать аудио, скачать через торрент в формате fb2 и присутствует краткое содержание. Жанр: unrecognised, на английском языке. Описание произведения, (предисловие) а так же отзывы посетителей доступны на портале библиотеки ЛибКат.

- Название:The Handbook of Speech Perception
- Автор:
- Жанр:
- Год:неизвестен
- ISBN:нет данных
- Рейтинг книги:4 / 5. Голосов: 1
-
Избранное:Добавить в избранное
- Отзывы:
-
Ваша оценка:
The Handbook of Speech Perception: краткое содержание, описание и аннотация
Предлагаем к чтению аннотацию, описание, краткое содержание или предисловие (зависит от того, что написал сам автор книги «The Handbook of Speech Perception»). Если вы не нашли необходимую информацию о книге — напишите в комментариях, мы постараемся отыскать её.
, Second Edition, is a comprehensive and up-to-date survey of technical and theoretical developments in perceptual research on human speech. Offering a variety of perspectives on the perception of spoken language, this volume provides original essays by leading researchers on the major issues and most recent findings in the field. Each chapter provides an informed and critical survey, including a summary of current research and debate, clear examples and research findings, and discussion of anticipated advances and potential research directions. The timely second edition of this valuable resource:
Discusses a uniquely broad range of both foundational and emerging issues in the field Surveys the major areas of the field of human speech perception Features newly commissioned essays on the relation between speech perception and reading, features in speech perception and lexical access, perceptual identification of individual talkers, and perceptual learning of accented speech Includes essential revisions of many chapters original to the first edition Offers critical introductions to recent research literature and leading field developments Encourages the development of multidisciplinary research on speech perception Provides readers with clear understanding of the aims, methods, challenges, and prospects for advances in the field
, Second Edition, is ideal for both specialists and non-specialists throughout the research community looking for a comprehensive view of the latest technical and theoretical accomplishments in the field.
The Handbook of Speech Perception — читать онлайн ознакомительный отрывок
Ниже представлен текст книги, разбитый по страницам. Система сохранения места последней прочитанной страницы, позволяет с удобством читать онлайн бесплатно книгу «The Handbook of Speech Perception», без необходимости каждый раз заново искать на чём Вы остановились. Поставьте закладку, и сможете в любой момент перейти на страницу, на которой закончили чтение.
Интервал:
Закладка:
In addition to filling in missing phonemes, the idea of temporal prediction can be invoked as an explanation of how the auditory system accomplishes one of its most difficult feats: selective attention. Selective attention is often called the cocktail party problem, because many people have experienced the use of selective attention in a busy, noisy party to isolate one speaker’s voice from the cacophonous mixture of many. Mesgarani and Chang (2012) simulated this cocktail party experience (unfortunately without the cocktails) by simultaneously playing two speech recordings to their subjects, one in each ear. The subjects were asked to attend to the recording presented to a specific ear and ECoG was used to record neural responses from the STG. Using the same stimulus‐reconstruction technique as Leonard et al. (2016), Mesgarani and Chang (2012) took turns reconstructing the speech that was played to each ear. Despite the fact that acoustic energy entered both ears and presumably propagated up the subcortical pathway, Mesgarani and Chang (2012) found that, once the neural processing of the speech streams had reached the STG, only the attended speech stream could be reconstructed; to the STG, it was as if the unattended stream did not exist.
We know from a second cocktail party experiment (which again did not include any actual cocktails) that selective attention is sensitive to how familiar the hearer is with each speaker. In their behavioral study, Johnsrude et al. (2013) recruited a group of subjects that included multiple spouses. If you were a subject in the study, your partner’s voice was sometimes the target (i.e. attended speech); your partner’s voice was sometimes the distractor (i.e. unattended speech); and sometimes both target and distractor voices belonged to other subjects’ spouses. Johnsrude et al. (2013) found that not only were subjects better at recalling semantic details of the attended speech when the target speaker was their partner, but they also performed better when their spouse played the role of distractor, compared to when both target and distractor roles were played by strangers. In effect, Johnsrude et al. (2013) amusingly showed that people are better at ignoring their own spouses than they are at ignoring strangers. Given that hearers can fill in missing information when it can be predicted from context (Leonard et al., 2016), it makes sense that subjects should comprehend the speech of someone familiar, whom they are better at predicting, than the speech of a stranger. Given that native speakers are better than nonnative speakers at suppressing the sound of their own voices (Parker Jones et al., 2013), it also makes sense that subjects should be better able to suppress the voice of their spouse – again assuming that their spouse’s voice is more predictable to them than a stranger’s. Taken together, these findings suggest that the mechanism behind selective attention is, again, prediction. So, while Mesgarani and Chang (2012) may be unable to reconstruct the speech of a distractor voice from ECoG recordings in the STG, it may be that higher brain regions will nonetheless contain a representation of the distractor voice for the purpose of suppressing it. An as yet unproven hypothesis is that the increased neural activity in frontal areas, observed during noisy listening conditions (Davis & Johnsrude, 2003), may be busy representing background noise or distractor voices, so that these sources may be filtered out of the mixed input signal. One way to test this may be to replicate Mesgarani and Chang’s (2012) cocktail party study, but with the focus on reconstructing speech from ECoG recordings taken from the auxiliary speech comprehension areas described by Davis and Johnsrude (2003) rather than from the STG.
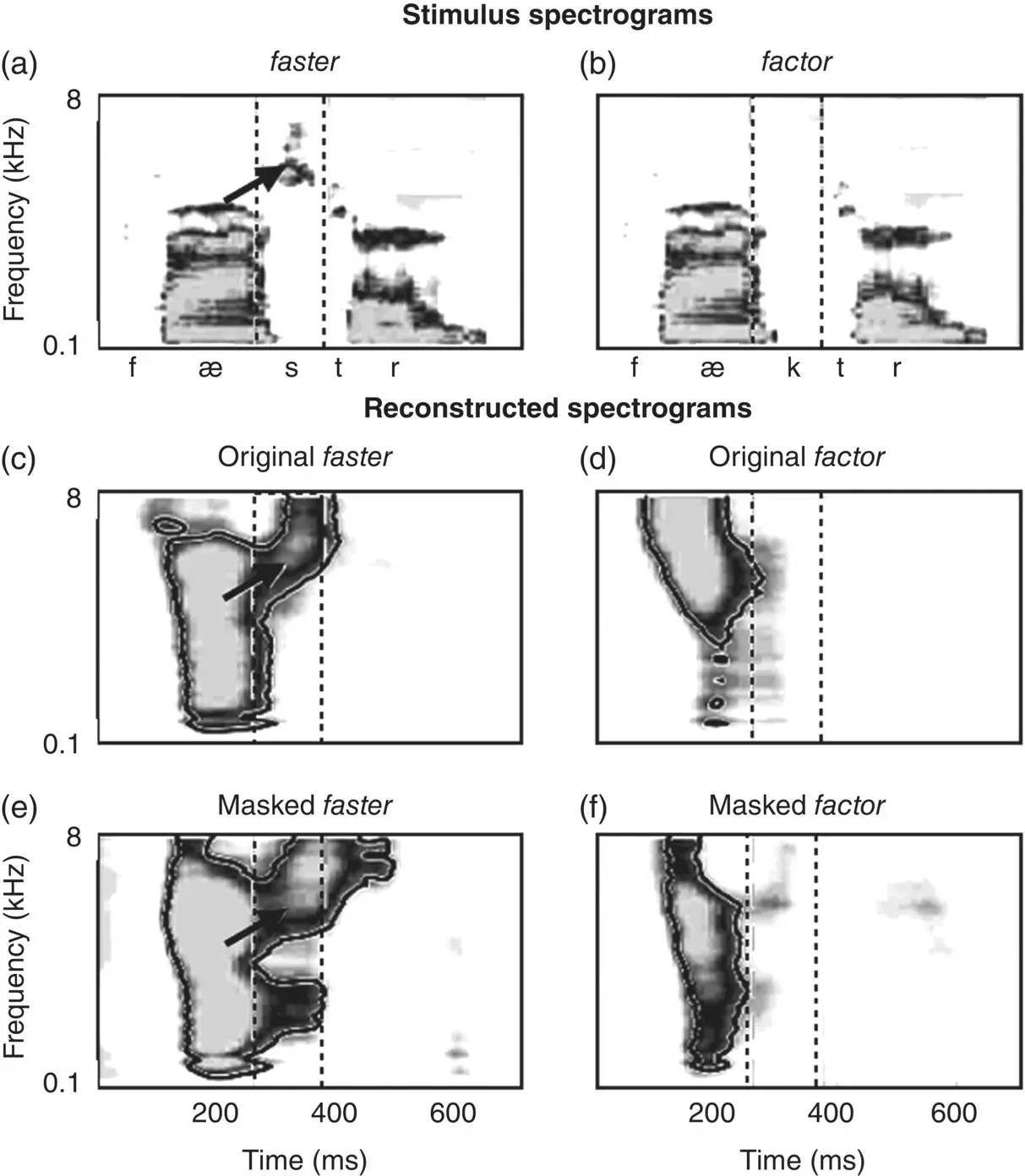
Figure 3.9 The human brain reinstates missing auditory representations. (a) and (b) show spectrograms for two words, faster /fæstr/ and factor /fæktr/. The segments of the spectrograms for /s/ and /k/ are indicated by dashed lines. The arrow in (a) points to aperiodic energy in higher‐frequency bands associated with fricative sounds like [s], which is absent in (b). (c) and (d) show neural reconstructions when subjects heard (a) and (b). (e) and (f) show neural reconstructions when subjects heard the masked stimulus /fæ#tr/. In (e), subjects heard On the highway he drives his car much /fæ#tr/ , which caused them to interpret the masked segment as /s/. In (f), the context suggested that the masked segment should be /k/.
Source: Leonard et al., 2016. Licensed under CC BY 4.0.
In the next and final section, we turn from sounds to semantics and to the representation of meaning in the brain.
Semantic representations
Following a long tradition in linguistics that goes back to Saussure (1989), speech may be thought of as a pairing of sound and meaning. In this chapter, our plan has been to follow the so‐called chain of speech (linking articulation, acoustics, and audition) deep into the brain systems involved in comprehending speech (cochlea, subcortical pathways, primary auditory cortex, and beyond). We have asked how the brain represents speech at each stage and even how speech representations are dynamically linked in a network of brain regions, but we have not talked yet about meaning. This was largely dictated by necessity: much more is known about how the brain represents sound than meaning. Indeed, it can even be difficult to pin down what meaning means. In this section, we will focus on a rather narrow kind of meaning, which linguists refer to as semantics and which should be kept distinct from another kind of meaning called pragmatics . Broadly speaking, semantics refers to literal meaning (e.g. ‘It is cold in here’ as a comment on the temperature of the room), whereas pragmatics refers to meaning in context (‘It is cold in here’ as an indirect request that someone close the window). It may be true that much of what is interesting about human communication is contextual (we are social animals after all), but we shall have our hands full trying to come to grips with even a little bit of how the brain represents the literal meaning of words ( lexical semantics ). Moreover, the presentation we give here views lexical semantics from a relatively new perspective grounded in the recent neuroscience and machine‐learning literatures, rather than in the linguistic (and philosophical) tradition of formal semantics (e.g. Aloni & Dekker, 2016). This is important because many established results in formal semantics have yet to be explained neurobiologically. For future neurobiologists of meaning, there will be many important discoveries to be made.
Embodied meaning
Despite the difficulty of comprehending the totality of what an example of speech might mean to your brain, there are some relatively easy places to begin. One kind of meaning a word might have, for instance, will relate to the ways in which you experience that word. Take the word ‘strawberry.’ Part of the meaning of this word is the shape and vibrant color of strawberries that you have seen. Another is how it smells and feels in your mouth when you eat it. To a first approximation, we can think of the meaning of the word ‘strawberry’ as the set of associated images, colors, smells, tastes, and other sensations that it can evoke. This is a very useful operational definition of “meaning” because it is to an extent possible to decode brain responses in sensory and motor areas and test whether these areas are indeed activated by words in the ways that we might expect, given the word’s meanings. To take a concrete example of how this approach can be used to distinguish the meaning of two words, consider the words ‘kick’ and ‘lick’: they differ by only one phoneme, /k/ versus /l/. Semantically, however, the words differ substantially, including, for example, by the part of the body that they are associated with: the foot for ‘kick’ and the tongue for ‘lick.’ Since, as we know, the sensorimotor cortex contains a map of the body, the so‐called homunculus (Penfield & Boldrey, 1937), with the foot and tongue areas at opposite ends, the embodied view of meaning would predict that hearing the word ‘kick’ should activate the foot area, which is located near the very top of the head, along the central sulcus on the medial surface of the brain, whereas the word ‘lick’ should active the tongue area, on the lateral surface almost all the way down the central sulcus to the Sylvian fissure. And indeed, these predictions have been verified now over a series of experiments (Pulvermüller, 2005): when you hear a word like ‘kick’ or ‘lick,’ not only does your brain represent the sounds of these words through the progression of acoustic, phonetic, and phonological representations in a hierarchy of auditory‐processing centers that has been discussed in this chapter, but your brain also represents the meaning of these words across a network of associations that certainly engage your sensory and motor cortices, and, as we shall see, many other cortical regions too.
Читать дальшеИнтервал:
Закладка:
Похожие книги на «The Handbook of Speech Perception»
Представляем Вашему вниманию похожие книги на «The Handbook of Speech Perception» списком для выбора. Мы отобрали схожую по названию и смыслу литературу в надежде предоставить читателям больше вариантов отыскать новые, интересные, ещё непрочитанные произведения.







![О Генри - Справочник Гименея [The Handbook of Hymen]](/books/407356/o-genri-spravochnik-gimeneya-the-handbook-of-hymen-thumb.webp)




Обсуждение, отзывы о книге «The Handbook of Speech Perception» и просто собственные мнения читателей. Оставьте ваши комментарии, напишите, что Вы думаете о произведении, его смысле или главных героях. Укажите что конкретно понравилось, а что нет, и почему Вы так считаете.