The Handbook of Speech Perception
Здесь есть возможность читать онлайн «The Handbook of Speech Perception» — ознакомительный отрывок электронной книги совершенно бесплатно, а после прочтения отрывка купить полную версию. В некоторых случаях можно слушать аудио, скачать через торрент в формате fb2 и присутствует краткое содержание. Жанр: unrecognised, на английском языке. Описание произведения, (предисловие) а так же отзывы посетителей доступны на портале библиотеки ЛибКат.

- Название:The Handbook of Speech Perception
- Автор:
- Жанр:
- Год:неизвестен
- ISBN:нет данных
- Рейтинг книги:4 / 5. Голосов: 1
-
Избранное:Добавить в избранное
- Отзывы:
-
Ваша оценка:
The Handbook of Speech Perception: краткое содержание, описание и аннотация
Предлагаем к чтению аннотацию, описание, краткое содержание или предисловие (зависит от того, что написал сам автор книги «The Handbook of Speech Perception»). Если вы не нашли необходимую информацию о книге — напишите в комментариях, мы постараемся отыскать её.
, Second Edition, is a comprehensive and up-to-date survey of technical and theoretical developments in perceptual research on human speech. Offering a variety of perspectives on the perception of spoken language, this volume provides original essays by leading researchers on the major issues and most recent findings in the field. Each chapter provides an informed and critical survey, including a summary of current research and debate, clear examples and research findings, and discussion of anticipated advances and potential research directions. The timely second edition of this valuable resource:
Discusses a uniquely broad range of both foundational and emerging issues in the field Surveys the major areas of the field of human speech perception Features newly commissioned essays on the relation between speech perception and reading, features in speech perception and lexical access, perceptual identification of individual talkers, and perceptual learning of accented speech Includes essential revisions of many chapters original to the first edition Offers critical introductions to recent research literature and leading field developments Encourages the development of multidisciplinary research on speech perception Provides readers with clear understanding of the aims, methods, challenges, and prospects for advances in the field
, Second Edition, is ideal for both specialists and non-specialists throughout the research community looking for a comprehensive view of the latest technical and theoretical accomplishments in the field.
The Handbook of Speech Perception — читать онлайн ознакомительный отрывок
Ниже представлен текст книги, разбитый по страницам. Система сохранения места последней прочитанной страницы, позволяет с удобством читать онлайн бесплатно книгу «The Handbook of Speech Perception», без необходимости каждый раз заново искать на чём Вы остановились. Поставьте закладку, и сможете в любой момент перейти на страницу, на которой закончили чтение.
Интервал:
Закладка:
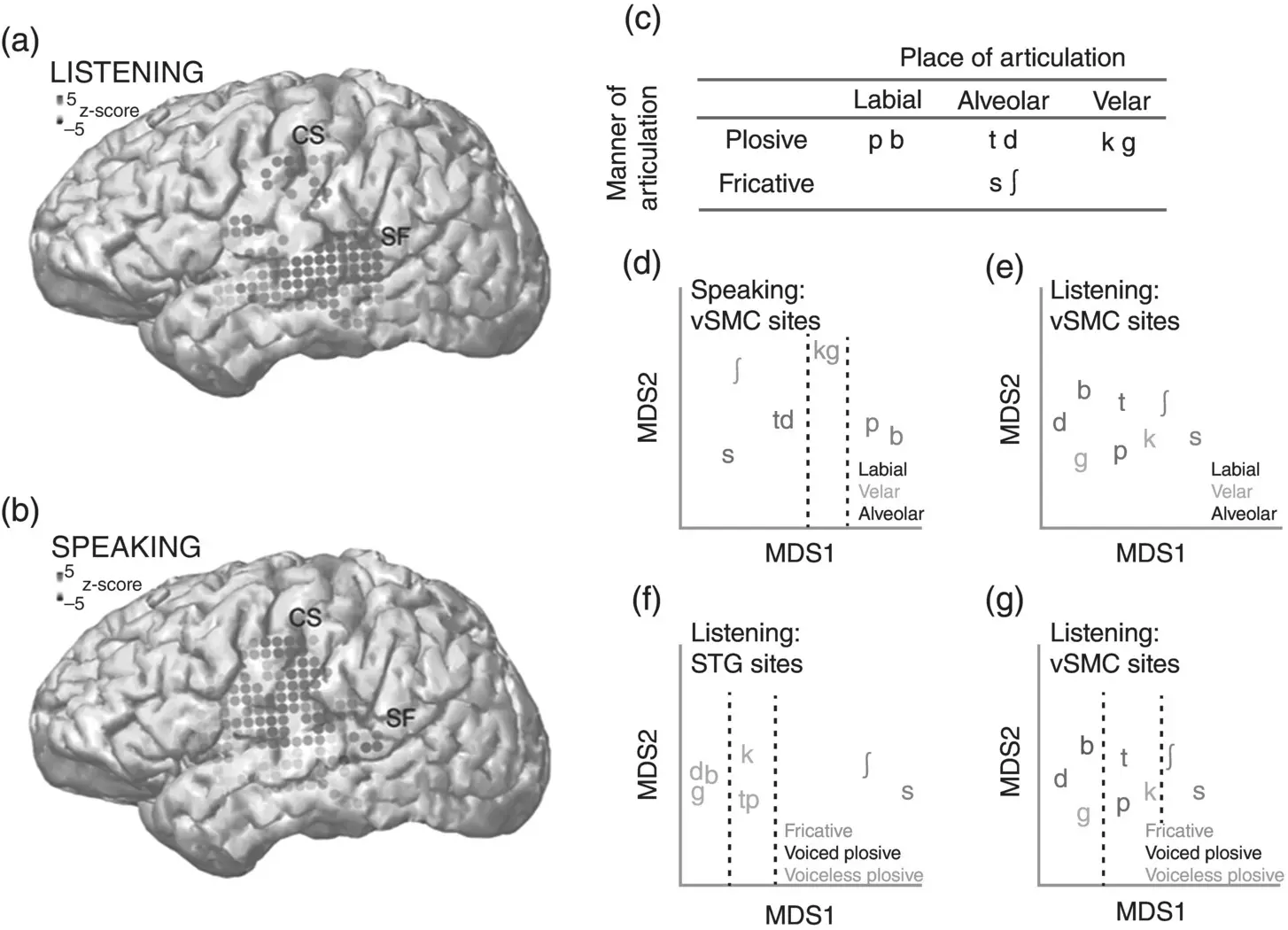
Figure 3.8 Feature‐based representations in the human sensorimotor cortex. (a) and (b) show the most significant electrodes (gray dots) for listening and speaking tasks. (c) presents a feature analysis of the consonant phonemes used in the experiments. The left phoneme in each pair is unvoiced and the right phoneme is voiced (e.g. /p/ is unvoiced and /b/ is voiced). (d–g) are discussed in the main text; each panel shows a low‐dimensional projection of the neural data where distance between phoneme representations is meaningful (i.e. phonemes that are close to each other are represented similarly in the neural data). The dotted lines show how groups of phonemes can be linearly separated (or not) according to place of articulation, manner of articulation, and voicing features.
Source: Cheung et al., 2016. Licensed under CC BY 4.0.
Systems‐level representations and temporal prediction
Our journey through the auditory system has focused on specific regions and on the auditory representation of speech in these regions. However, representations in the brain are not limited to isolated islands of cells, but also rely upon constellations of regions that relay information within a network. In this section, we touch briefly on the topic of systems‐level representations of speech perception and on the related topic of temporal prediction, which is at the heart of why we have brains in the first place.
Auditory feedback networks
One way to appreciate the dynamic interconnectedness of the auditory brain is to consider the phenomenon of auditory suppression. Auditory suppression manifests, for example, in the comparison of STG responses when we listen to another person speak and when we speak ourselves, and thus hear the sounds we produce. Electrophysiological studies have shown that auditory neurons are suppressed in monkeys during self‐vocalization (Müller‐Preuss & Ploog, 1981; Eliades & Wang, 2008; Flinker et al., 2010). This finding is consistent with fMRI and ECoG results in humans, showing that activity in the STG is suppressed during speech production compared to speech comprehension (Eliades & Wang, 2008; Flinker et al., 2010). The reason for this auditory suppression is thought to be an internal signal ( efference copy ) received from another part of the brain, such as the motor or premotor cortex, which has inside information about external stimuli when those external stimuli are self‐produced (Holst & Mittelstaedt, 1950). The brain’s use of this kind of inside information is not, incidentally, limited to the auditory system. Anyone who has failed to tickle themselves has experienced another kind of sensory suppression, again thought to be based on internally generated expectations (Blakemore, Wolpert, & Frith, 2000).
Auditory suppression in the STG is also a function of language proficiency. As an example, Parker Jones et al. (2013) explored the interactions between premotor cortex and two temporal areas (aSTG and pSTG) when native and nonnative English speakers performed speech‐production tasks such as reading and picture naming in an MRI scanner. The fMRI data were then subjected to a kind of connectivity analysis, which can tell us which regions influenced which other regions of the brain. Technically, the observed signals were deconvolved to model the effect of the hemodynamic response, and the underlying neural dynamics were inferred by inverting a generative model based on a set of differential equations (Friston, Harrison, & Penny, 2003; Daunizeau, David, & Stephan, 2011). A positive connection between two regions, A and B, means that, when the response in A is strong, the response in B will increase (i.e. B will have a positive derivative). Likewise, a negative connection means that, when the response in A is strong, the response in B will decrease (B will have a negative derivative). Between the PMC and temporal auditory areas, Parker Jones et al. (2013) observed significant negative connections, implying that brain activity in the PMC caused a decrease in auditory temporal activity consistent with auditory suppression. However, auditory suppression was observed in only the native English speakers. In nonnative speakers, there was no significant auditory suppression, but there was a positive effect between pSTG and PMC consistent with the idea of error feedback. The results suggest that PMC sends signal‐canceling, top‐down predictions to aSTG and pSTG. These top‐down predictions are stronger if you are a native speaker and more confident about what speech sounds you produce. In nonnative speakers, the top‐down predictions canceled less of the auditory input, and a bottom‐up learning signal (“error”) was fed back from the pSTG to the PMC. Interestingly, as the nonnative speakers became more proficient, the learning signals were observed to decrease, so that the most highly proficient nonnative speakers were indistinguishable from native speakers in terms of error feedback.
The example of auditory suppression argues for a systems‐level view of speech comprehension that includes both auditory and premotor regions of the brain. Theoretically, we might think of these regions as being arranged in a functional hierarchy, with PMC located above both aSTG and pSTG. Top‐down predictions may thus be said to descend from PMC to aSTG and pSTG, while bottom‐up errors percolate in the opposite direction, from pSTG to PMC. We note that the framework used to interpret the auditory suppression results, predictive coding , subtly inverts the view that perceptual systems in the brain passively extract knowledge from the environment; instead, it proposes that these systems are actively trying to predict their sense experiences (Ballard, Hinton, & Sejnowski, 1983; Mumford, 1992; Kawato, Hayakawa, & Inui, 1993; Dayan et al., 1995; Rao & Ballard, 1999; Friston & Kiebel, 2009). In a foundational sense, predictive coding frames the brain as a forecasting machine, which has evolved to minimize surprises and to anticipate, and not merely react to, events in the world (Wolpert, Ghahramani, & Flanagan, 2001). This is not necessarily to say that what it means to be a person is to be a prediction machine, but rather to conjecture that perceptual systems in our brains, at least sometimes, predict sense experiences.
Temporal prediction
The importance of prediction as a theme and as a hypothetical explanation for neural function also goes beyond explicit modeling in neural networks. We can invoke the idea of temporal prediction even when we do not know about the underlying connectivity patterns. Speech, for example, does not consist of a static set of phonemes; rather, speech is a continuous sequence of events, such that hearing part of the sequence gives you information about other parts that you have yet to hear. In phonology the sequential dependency of phonemes is called phonotactics and can be viewed as a kind of prediction. That is, if the sequence /st/ is more common than /sd/, because /st/ occurs in syllabic onsets, then it can be said that /s/ predicts /t/ (more than /s/ predicts /d/). This use of phonotactics for prediction is made explicit in machine learning, where predictive models (e.g. bigram and trigram models historically, or, more recently, recurrent neural networks) have played an important role in the development and commercial use of speech‐recognition technologies (Jurafsky & Martin, 2014; Graves & Jaitly, 2014).
In neuroscience, the theme of prediction comes up in masking and perceptual restoration experiments. One remarkable ECoG study, by Leonard et al. (2016), played subjects recordings of words in which key phonemes were masked by noise. For example, a subject might have heard /fæ#tr/, where the /#/ symbol represents a brief noise burst masking the underlying phoneme. In this example, the intended word is ambiguous: it could have been /fæstr/ ‘faster’ or /fæktr/ ‘factor’. So, by controlling the context in which the stimulus was presented, Leonard et al. (2016) were able to manipulate subjects to hear one word or the other. In the sentence ‘On the highway he drives his car much /fæ#tr/,’ we expect the listener to perceive the word ‘faster’ /fæstr/. In another sentence, that expectation was modified so that subjects perceived the same noisy segment of speech as ‘factor’ /fæktr/. Leonard et al. (2016) then used a technique called stimulus reconstruction , by which it is possible to infer rather good speech spectrograms from intracranial recordings (Mesgarani et al., 2008; Pasley et al., 2012). Spectrograms reconstructed from masked stimuli showed that the STG had filled in the missing auditory representations ( Figure 3.9). For example, when the context was modulated so that subjects perceived the ambiguous stimulus as ‘faster’/fæstr/, the reconstructed spectrogram was shown to contain an imagined fricative(s) ( Figure 3.9, panel E). When subjects perceived the word as ‘factor’/fæktr/, the reconstructed spectrogram contained an imagined stop [k] ( Figure 3.9, panel F). In this way, Leonard et al. (2016) demonstrated that auditory representations of speech are sensitive to their temporal context.
Читать дальшеИнтервал:
Закладка:
Похожие книги на «The Handbook of Speech Perception»
Представляем Вашему вниманию похожие книги на «The Handbook of Speech Perception» списком для выбора. Мы отобрали схожую по названию и смыслу литературу в надежде предоставить читателям больше вариантов отыскать новые, интересные, ещё непрочитанные произведения.







![О Генри - Справочник Гименея [The Handbook of Hymen]](/books/407356/o-genri-spravochnik-gimeneya-the-handbook-of-hymen-thumb.webp)




Обсуждение, отзывы о книге «The Handbook of Speech Perception» и просто собственные мнения читателей. Оставьте ваши комментарии, напишите, что Вы думаете о произведении, его смысле или главных героях. Укажите что конкретно понравилось, а что нет, и почему Вы так считаете.