Lillian Pierson - Data Science For Dummies
Здесь есть возможность читать онлайн «Lillian Pierson - Data Science For Dummies» — ознакомительный отрывок электронной книги совершенно бесплатно, а после прочтения отрывка купить полную версию. В некоторых случаях можно слушать аудио, скачать через торрент в формате fb2 и присутствует краткое содержание. Жанр: unrecognised, на английском языке. Описание произведения, (предисловие) а так же отзывы посетителей доступны на портале библиотеки ЛибКат.

- Название:Data Science For Dummies
- Автор:
- Жанр:
- Год:неизвестен
- ISBN:нет данных
- Рейтинг книги:4 / 5. Голосов: 1
-
Избранное:Добавить в избранное
- Отзывы:
-
Ваша оценка:
Data Science For Dummies: краткое содержание, описание и аннотация
Предлагаем к чтению аннотацию, описание, краткое содержание или предисловие (зависит от того, что написал сам автор книги «Data Science For Dummies»). Если вы не нашли необходимую информацию о книге — напишите в комментариях, мы постараемся отыскать её.
Data Science For Dummies Data Science For Dummies How natural language processing works Strategies around data science How to make decisions using probabilities Ways to display your data using a visualization model How to incorporate various programming languages into your strategy Whether you’re a professional or a student,
will get you caught up on all the latest data trends. Find out how to ask the pressing questions you need your data to answer by picking up your copy today.
Data Science For Dummies — читать онлайн ознакомительный отрывок
Ниже представлен текст книги, разбитый по страницам. Система сохранения места последней прочитанной страницы, позволяет с удобством читать онлайн бесплатно книгу «Data Science For Dummies», без необходимости каждый раз заново искать на чём Вы остановились. Поставьте закладку, и сможете в любой момент перейти на страницу, на которой закончили чтение.
Интервал:
Закладка:
Structured data can be stored, processed, and manipulated in a traditional relational database management system (RDBMS) — an example of this would be a PostgreSQL database that uses a tabular schema of rows and columns, making it easier to identify specific values within data that’s stored within the database. This data, which can be generated by humans or machines, is derived from all sorts of sources — from click-streams and web-based forms to point-of-sale transactions and sensors. Unstructured data comes completely unstructured — it’s commonly generated from human activities and doesn’t fit into a structured database format. Such data can be derived from blog posts, emails, and Word documents. Semistructured data doesn’t fit into a structured database system, but is nonetheless structured, by tags that are useful for creating a form of order and hierarchy in the data. Semistructured data is commonly found in databases and file systems. It can be stored as log files, XML files, or JSON data files.
 Become familiar with the term data lake — this term is used by practitioners in the big data industry to refer to a nonhierarchical data storage system that’s used to hold huge volumes of multistructured, raw data within a flat storage architecture — in other words, a collection of records that come in uniform format and that are not cross-referenced in any way. HDFS can be used as a data lake storage repository, but you can also use the Amazon Web Services (AWS) S3 platform — or a similar cloud storage solution — to meet the same requirements on the cloud. (The Amazon Web Services S3 platform is one of the more popular cloud architectures available for storing big data.)
Become familiar with the term data lake — this term is used by practitioners in the big data industry to refer to a nonhierarchical data storage system that’s used to hold huge volumes of multistructured, raw data within a flat storage architecture — in other words, a collection of records that come in uniform format and that are not cross-referenced in any way. HDFS can be used as a data lake storage repository, but you can also use the Amazon Web Services (AWS) S3 platform — or a similar cloud storage solution — to meet the same requirements on the cloud. (The Amazon Web Services S3 platform is one of the more popular cloud architectures available for storing big data.)
 Although both data lake and data warehouse are used for storing data, the terms refer to different types of systems. Data lake was defined above and a data warehouse is a centralized data repository that you can use to store and access only structured data. A more traditional data warehouse system commonly employed in business intelligence solutions is a data mart — a storage system (for structured data) that you can use to store one particular focus area of data, belonging to only one line of business in the company.
Although both data lake and data warehouse are used for storing data, the terms refer to different types of systems. Data lake was defined above and a data warehouse is a centralized data repository that you can use to store and access only structured data. A more traditional data warehouse system commonly employed in business intelligence solutions is a data mart — a storage system (for structured data) that you can use to store one particular focus area of data, belonging to only one line of business in the company.
Identifying Important Data Sources
Vast volumes of data are continually generated by humans, machines, and sensors everywhere. Typical sources include data from social media, financial transactions, health records, click-streams, log files, and the Internet of things — a web of digital connections that joins together the ever-expanding array of electronic devices that consumers use in their everyday lives. Figure 2-1 shows a variety of popular big data sources.
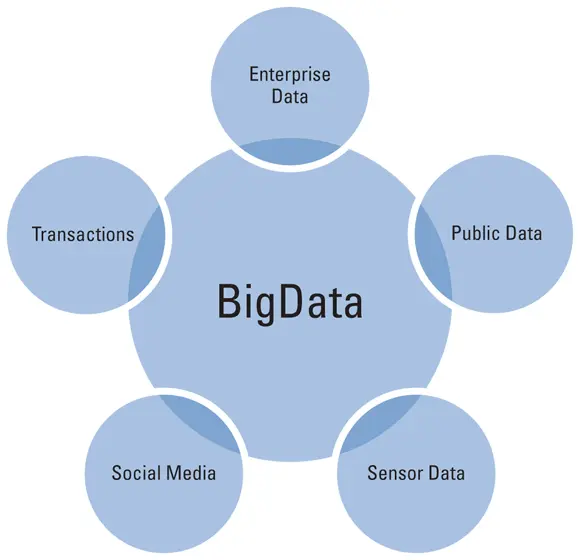
FIGURE 2-1:Popular sources of big data.
Grasping the Differences among Data Approaches
Data science, machine learning engineering, and data engineering cover different functions within the big data paradigm — an approach wherein huge velocities, varieties, and volumes of structured, unstructured, and semistructured data are being captured, processed, stored, and analyzed using a set of techniques and technologies that are completely novel compared to those that were used in decades past.
All these functions are useful for deriving knowledge and actionable insights from raw data. All are essential elements for any comprehensive decision-support system, and all are extremely helpful when formulating robust strategies for future business growth. Although the terms data science and data engineering are often used interchangeably, they’re distinct domains of expertise. Over the past five years, the role of machine learning engineer has risen up to bridge a gap that exists between data science and data engineering. In the following sections, I introduce concepts that are fundamental to data science and data engineering, as well as the hybrid machine learning engineering role, and then I show you the differences in how these roles function in an organization’s data team.
Defining data science
If science is a systematic method by which people study and explain domain-specific phenomena that occur in the natural world, you can think of data science as the scientific domain that’s dedicated to knowledge discovery via data analysis.
 With respect to data science, the term domain-specific refers to the industry sector or subject matter domain that data science methods are being used to explore.
With respect to data science, the term domain-specific refers to the industry sector or subject matter domain that data science methods are being used to explore.
Data scientists use mathematical techniques and algorithmic approaches to derive solutions to complex business and scientific problems. Data science practitioners use its predictive methods to derive insights that are otherwise unattainable. In business and in science, data science methods can provide more robust decision-making capabilities:
In business, the purpose of data science is to empower businesses and organizations with the data insights they need in order to optimize organizational processes for maximum efficiency and revenue generation.
In science, data science methods are used to derive results and develop protocols for achieving the specific scientific goal at hand.
Data science is a vast and multidisciplinary field. To call yourself a true data scientist, you need to have expertise in math and statistics, computer programming, and your own domain-specific subject matter.
Using data science skills, you can do cool things like the following:
Use machine learning to optimize energy usage and lower corporate carbon footprints.
Optimize tactical strategies to achieve goals in business and science.
Predict for unknown contaminant levels from sparse environmental datasets.
Design automated theft- and fraud-prevention systems to detect anomalies and trigger alarms based on algorithmic results.
Craft site-recommendation engines for use in land acquisitions and real estate development.
Implement and interpret predictive analytics and forecasting techniques for net increases in business value.
Data scientists must have extensive and diverse quantitative expertise to be able to solve these types of problems.
Machine learning is the practice of applying algorithms to learn from — and make automated predictions from — data.
Defining machine learning engineering
A machine learning engineer is essentially a software engineer who is skilled enough in data science to deploy advanced data science models within the applications they build, thus bringing machine learning models into production in a live environment like a Software as a Service (SaaS) product or even just a web page. Contrary to what you may have guessed, the role of machine learning engineer is a hybrid between a data scientist and a software engineer, not a data engineer. A machine learning engineer is, at their core, a well-rounded software engineer who also has a solid foundation in machine learning and artificial intelligence. This person doesn’t need to know as much data science as a data scientist but should know much more about computer science and software development than a typical data scientist.
Читать дальшеИнтервал:
Закладка:
Похожие книги на «Data Science For Dummies»
Представляем Вашему вниманию похожие книги на «Data Science For Dummies» списком для выбора. Мы отобрали схожую по названию и смыслу литературу в надежде предоставить читателям больше вариантов отыскать новые, интересные, ещё непрочитанные произведения.
![Роман Зыков - Роман с Data Science. Как монетизировать большие данные [litres]](/books/438007/roman-zykov-roman-s-data-science-kak-monetizirova-thumb.webp)











Обсуждение, отзывы о книге «Data Science For Dummies» и просто собственные мнения читателей. Оставьте ваши комментарии, напишите, что Вы думаете о произведении, его смысле или главных героях. Укажите что конкретно понравилось, а что нет, и почему Вы так считаете.