Stephen R. Bolsover - Cell Biology
Здесь есть возможность читать онлайн «Stephen R. Bolsover - Cell Biology» — ознакомительный отрывок электронной книги совершенно бесплатно, а после прочтения отрывка купить полную версию. В некоторых случаях можно слушать аудио, скачать через торрент в формате fb2 и присутствует краткое содержание. Жанр: unrecognised, на английском языке. Описание произведения, (предисловие) а так же отзывы посетителей доступны на портале библиотеки ЛибКат.

- Название:Cell Biology
- Автор:
- Жанр:
- Год:неизвестен
- ISBN:нет данных
- Рейтинг книги:3 / 5. Голосов: 1
-
Избранное:Добавить в избранное
- Отзывы:
-
Ваша оценка:
Cell Biology: краткое содержание, описание и аннотация
Предлагаем к чтению аннотацию, описание, краткое содержание или предисловие (зависит от того, что написал сам автор книги «Cell Biology»). Если вы не нашли необходимую информацию о книге — напишите в комментариях, мы постараемся отыскать её.
Cell Biology: A Short Course
Cell Biology: A Short Course
Cell Biology: A Short Course
Cell Biology — читать онлайн ознакомительный отрывок
Ниже представлен текст книги, разбитый по страницам. Система сохранения места последней прочитанной страницы, позволяет с удобством читать онлайн бесплатно книгу «Cell Biology», без необходимости каждый раз заново искать на чём Вы остановились. Поставьте закладку, и сможете в любой момент перейти на страницу, на которой закончили чтение.
Интервал:
Закладка:
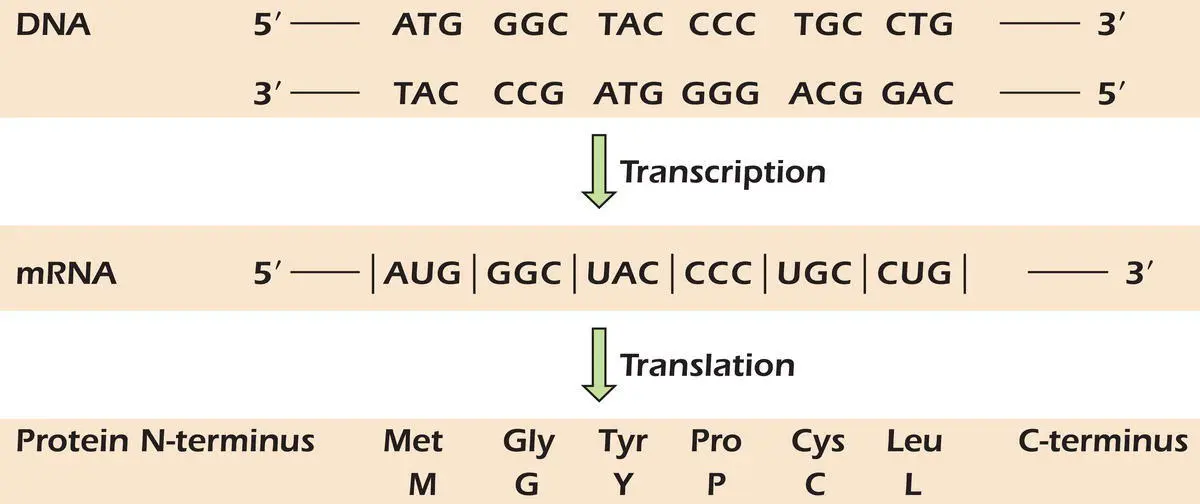
 Figure 3.8.DNA makes RNA makes protein: the central dogma of molecular biology.
Figure 3.8.DNA makes RNA makes protein: the central dogma of molecular biology.
The identification of the triplets encoding each amino acid began in 1961. This was made possible by using a cell‐free protein synthesis system prepared by breaking open E. coli cells. Synthetic RNA polymers, of known sequence, were added to the cell‐free system together with the 20 amino acids. When the RNA template contained only uridine residues (poly‐U) the polypeptide produced contained only phenylalanine – therefore codon UUU must specify phenylalanine. A poly(A) template produced a polypeptide of lysine and poly‐C one of proline: AAA and CCC must therefore specify lysine and proline, respectively. Synthetic RNA polymers containing all possible combinations of the bases G, A, U, and C, were added to the cell‐free system to determine the codons for the other amino acids. A template made of the repeating unit CU gave a polypeptide with the alternating sequence leucine–serine. Because the first amino acid in the chain was found to be leucine, CUC must code for leucine and UCU must code for serine. Although much of the genetic code was read in this way, the amino acids defined by some codons were particularly hard to determine. Only when specific transfer RNAmolecules (page 85) were used was it possible to demonstrate that GUU codes for valine. The genetic code was finally solved by the combined efforts of several research teams. The leaders of two of these, Marshall Nirenberg and Har Gobind Khorana, received the Nobel prize in 1968 for their part in cracking the code.
Amino Acid Names Are Abbreviated
To save time we usually write an amino acid as either a three‐letter abbreviation, for example, glycine is written as Gly and leucine as Leu, or as a one‐letter code, for example, glycine is G and leucine is L. Figure 3.9shows the full name and the three‐ and one‐letter abbreviations used for each of the 20 amino acids found in proteins.
The Code Is Degenerate but Unambiguous
To introduce the terms degenerate and ambiguous, consider the English language. English shows considerable degeneracy, meaning that the same concept can be indicated using a number of different words – think, for example, of lockup, cell, pen, pound, brig, and dungeon . English also shows ambiguity, so that it is only by context that one can tell whether cell means a lockup or a living aqueous droplet enclosed by a membrane . Like the English language the genetic code shows degeneracy but, unlike language, the genetic code is unambiguous.
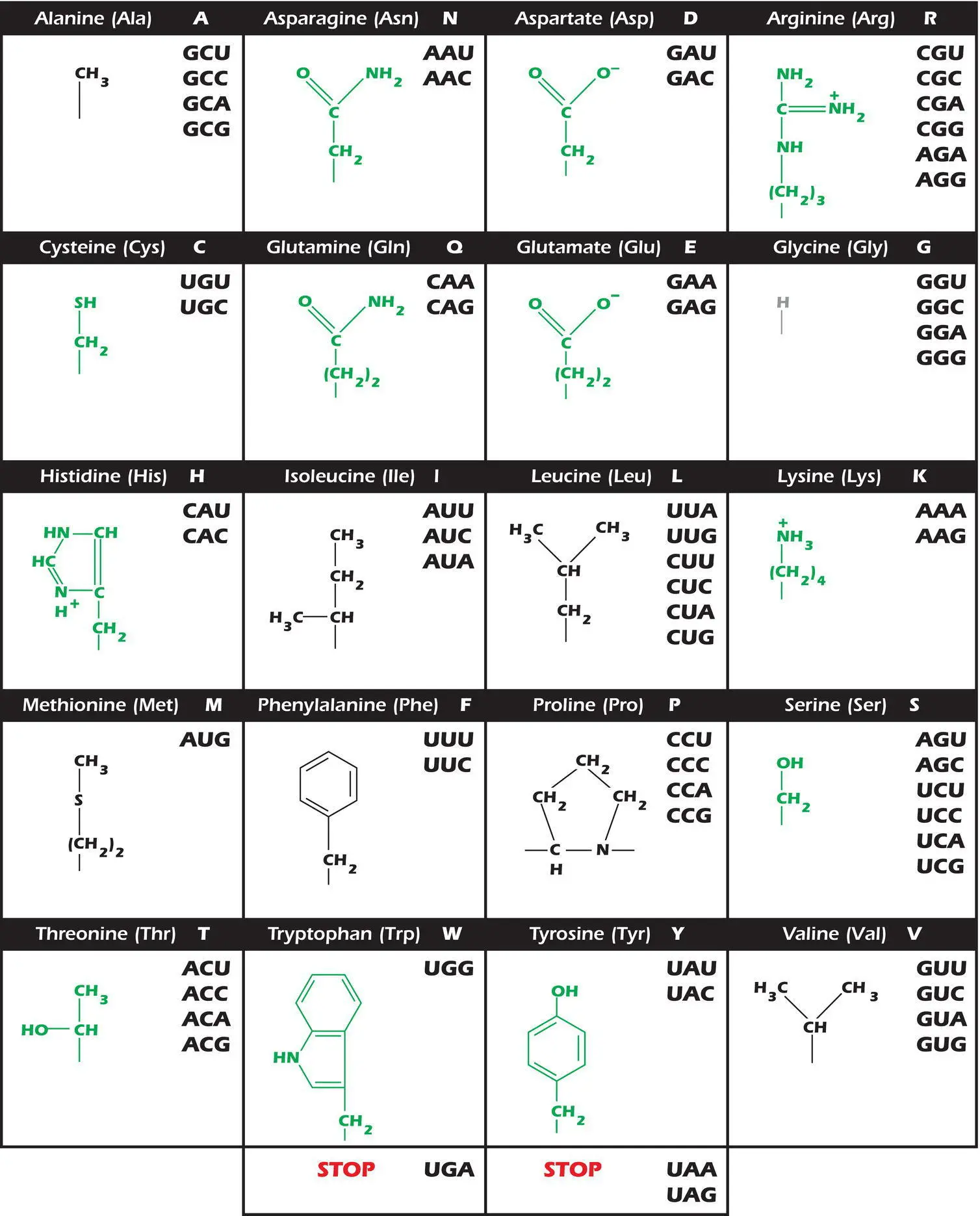
Figure 3.9.The genetic code. Amino acid side chains are shown in alphabetical order together with the three‐ and one‐letter amino acid abbreviations. Hydrophilic side chains are shown in green, hydrophobic side chains are black, and the minimal side chain of glycine is shown in gray. The significance of this distinction is discussed in Chapter 7. To the right of each amino acid we show the corresponding mRNA codons.
The 64 codons of the genetic code are shown in Figure 3.9together with the side chains of the amino acids for which each codes. Amino acids with hydrophilic side chains are shown in green while those with hydrophobic side chains are in black. Glycine, which has a hydrogen for a side chain, is shown in gray. The importance of these distinctions will be discussed in Chapter 7. Methionine is encoded by a single codon: AUG. Tryptophan is also encoded by a single codon, but the other 18 amino acids are encoded by more than one codon and so the code is degenerate.Although there are 64 possible codons, there are only 20 amino acids. Sixty‐one codons specify an amino acid and the remaining three act as stop signalsfor protein synthesis ( Figure 3.9). No triplet codes for more than one amino acid and so the code is unambiguous.Notice that when two or more codons specify the same amino acid, they usually only differ in the third base of the triplet. Thus single base substitutionsin the third base can often leave the amino acid sequence unaltered. Perhaps degeneracy evolved in the triplet system to avoid a situation in which 20 codons each meant one amino acid and 44 specified none. If this were the case, then most mutations would stop protein synthesis dead.
Start and Stop Codons and the Reading Frame
The order of the codons in DNA and the amino acid sequence of a protein are colinear. The start signalfor protein synthesis is the codon AUG, specifying the incorporation of methionine. Because the genetic code is read in blocks of three, there are three potential reading framesin any mRNA. Figure 3.10shows that only one of these results in the synthesis of the correct protein. When we look at a sequence of bases, it is not obvious which of the reading frames should be used to code for the protein. As we shall see later (page 89), the ribosome scans along the mRNA until it encounters an AUG. This both defines the first amino acid of the protein and the reading frame used from that point on. A mutation that inserts or deletes a nucleotide will change the normal reading frame and is called a frameshift mutation( Figure 3.11).
The codons UAA, UAG, and UGA are stop signals for protein synthesis. A base change that causes an amino acid codon to become a stop codonis known as a nonsense mutation( Figure 3.11). If, for example, the codon for tryptophan UGG changes to UGA, then a premature stop signal will have been introduced into the messenger RNA template. A shortened protein, usually without function, is produced.
The Code Is Nearly Universal
The code shown in Figure 3.9is the one used by organisms as diverse as E. coli and humans for their nuclear‐encoded proteins. It was originally thought that the code would be universal. However, several mitochondrial genes use UGA to mean tryptophan rather than stop . The nuclear code for some unicellular eukaryotes uses UAA and UAG to code for glutamine rather than stop .

Figure 3.10.Reading frames. The genetic code is read in blocks of three.

Figure 3.11.Mutations that alter the sequence of bases.
Missense Mutations
A mutation that changes the codon from one amino acid to that for another by substitution of one base for another is a missense mutation( Figure 3.11). As shown in Figure 3.9, the second base of each codon shows the most consistency with the chemical nature of the amino acid it encodes. Amino acids with hydrophobic side chains, shown in black in Figure 3.9, have a U or a C – a pyrimidine – in the second position. With two exceptions, serine and threonine, amino acids with hydrophilic side chains, shown in green in Figure 3.9, have a G or an A – a purine – in the second position. This has implications for mutations of the second base. Substitution of a purine for a pyrimidine is very likely to change the chemical nature of the amino acid side chain significantly and can therefore seriously affect the protein. Sickle cell anemia is an example of such a mutation. At position 6 in the β‐globin chain of hemoglobin, the mutation in DNA changes a glutamate residue encoded by GAG to a valine residue encoded by GTG (GUG in RNA). The shorthand notation for this mutation is E6V, meaning that the glutamate (E) at position 6 of the protein becomes a valine (V). This change in amino acid alters the overall charge of the chain and the hemoglobin tends to precipitate in the red blood cells of those affected. The cells adopt a sickle shape and therefore tend to block blood vessels, causing sickle cell anemia with painful cramp‐like symptoms and progressive damage to vital organs.
Читать дальшеИнтервал:
Закладка:
Похожие книги на «Cell Biology»
Представляем Вашему вниманию похожие книги на «Cell Biology» списком для выбора. Мы отобрали схожую по названию и смыслу литературу в надежде предоставить читателям больше вариантов отыскать новые, интересные, ещё непрочитанные произведения.












Обсуждение, отзывы о книге «Cell Biology» и просто собственные мнения читателей. Оставьте ваши комментарии, напишите, что Вы думаете о произведении, его смысле или главных героях. Укажите что конкретно понравилось, а что нет, и почему Вы так считаете.