Tormod Næs - Multiblock Data Fusion in Statistics and Machine Learning
Здесь есть возможность читать онлайн «Tormod Næs - Multiblock Data Fusion in Statistics and Machine Learning» — ознакомительный отрывок электронной книги совершенно бесплатно, а после прочтения отрывка купить полную версию. В некоторых случаях можно слушать аудио, скачать через торрент в формате fb2 и присутствует краткое содержание. Жанр: unrecognised, на английском языке. Описание произведения, (предисловие) а так же отзывы посетителей доступны на портале библиотеки ЛибКат.

- Название:Multiblock Data Fusion in Statistics and Machine Learning
- Автор:
- Жанр:
- Год:неизвестен
- ISBN:нет данных
- Рейтинг книги:3 / 5. Голосов: 1
-
Избранное:Добавить в избранное
- Отзывы:
-
Ваша оценка:
Multiblock Data Fusion in Statistics and Machine Learning: краткое содержание, описание и аннотация
Предлагаем к чтению аннотацию, описание, краткое содержание или предисловие (зависит от того, что написал сам автор книги «Multiblock Data Fusion in Statistics and Machine Learning»). Если вы не нашли необходимую информацию о книге — напишите в комментариях, мы постараемся отыскать её.
Explore the advantages and shortcomings of various forms of multiblock analysis, and the relationships between them, with this expert guide Multiblock Data Fusion in Statistics and Machine Learning: Applications in the Natural and Life Sciences
Multiblock Data Fusion in Statistics and Machine Learning: Applications in the Natural and Life Sciences
Multiblock Data Fusion in Statistics and Machine Learning — читать онлайн ознакомительный отрывок
Ниже представлен текст книги, разбитый по страницам. Система сохранения места последней прочитанной страницы, позволяет с удобством читать онлайн бесплатно книгу «Multiblock Data Fusion in Statistics and Machine Learning», без необходимости каждый раз заново искать на чём Вы остановились. Поставьте закладку, и сможете в любой момент перейти на страницу, на которой закончили чтение.
Интервал:
Закладка:
1.5 Goals of Analyses
Many goals of multiblock data analysis can be envisaged. In current practice, these goals are usually implicit. By making these goals explicit it will become necessary to also make explicit the global optimisation criterion or, when such a criterion is difficult to formulate, to carefully think about the whole data analysis procedure and which method to choose. Several general goals will be discussed briefly.
Exploratory analysis:One of the most obvious goals of multiblock data analysis is exploration which is a part of unsupervised analysis. By plotting the weights, scores, and loadings, summaries of the data are obtained which can be interpreted and maybe further analysed using visualisation tools.Predictive models:Another obvious goal is to try to predict the variation in one data block using several other data blocks; this is a part of supervised analysis. The idea is then that using multiple predictive blocks gives a better prediction for future samples.Finding topologies:In the case of complex data, data blocks can be placed in different relationships. The arrangement of blocks as dependent or independent may be a purpose of the analysis. We call such an arrangement a topology. In that case, it would be useful to have a strategy for deciding on the topology that fits the data best.Common versus distinct variation:There can be common and distinct variation in the multiple data blocks (see Section 1.8). This separation into types of variation greatly simplifies subsequent interpretation of the results.Treatment effects:The effect of a treatment can be measured in different blocks of data. The interest is usually what the main effect of a treatment is on measurements in the different blocks of data.Individual differences:Apart from group differences, also individual differences are useful. This can be for personalised medicine or nutritional interventions or consumer behaviour. Multiblock data analysis may help to find such differences and thereby facilitate population stratification and sub-typing.Mixed goals:In real-life applications, a mixture of goals is usually present. It may be that a treatment has been given which expresses itself differently in the common and distinct variation. Moreover, interest may be in the main effects of treatments but also on individual treatment effect differences.
1.6 Some History
The history of multiblock data analysis methods goes back a long time. One of the starting points was principal component analysis (PCA, Pearson (1901)). Another early method in statistics was canonical correlation analysis (Hotelling, 1936a) which led to development of many related methods. In the social sciences, path-models were developed, such as LISREL and PLS (Jöreskog and Wold, 1982) which are also used in consumer science and marketing research. In psychometrics, inter-battery factor analysis (Tucker, 1958) was developed and later simultaneous component analysis methods (Ten Berge et al ., 1992) which have also sparked many alternatives. In parallel in chemometrics, methods such as consensus PCA and hierarchical PCA were developed (Westerhuis et al ., 1998). Ideas on the latter two methods already started in the 1970s at conferences. In the French data analysis school, multiple correspondence analysis was developed (Benzécri, 1980) and many other methods. In multiway data analysis (which can be regarded as a subset of multiblock data analysis methods) the earliest developments started with the work of Cattell (1944), Carroll and Chang (1970) and Harshman (1970). For a history of the latter, see Smilde et al . (2004). Figure 1.8 tries to systematically show many multiblock data analysis methods and how they relate to basic statistical methodology and subspace projection methods from various fields of applied data analysis.
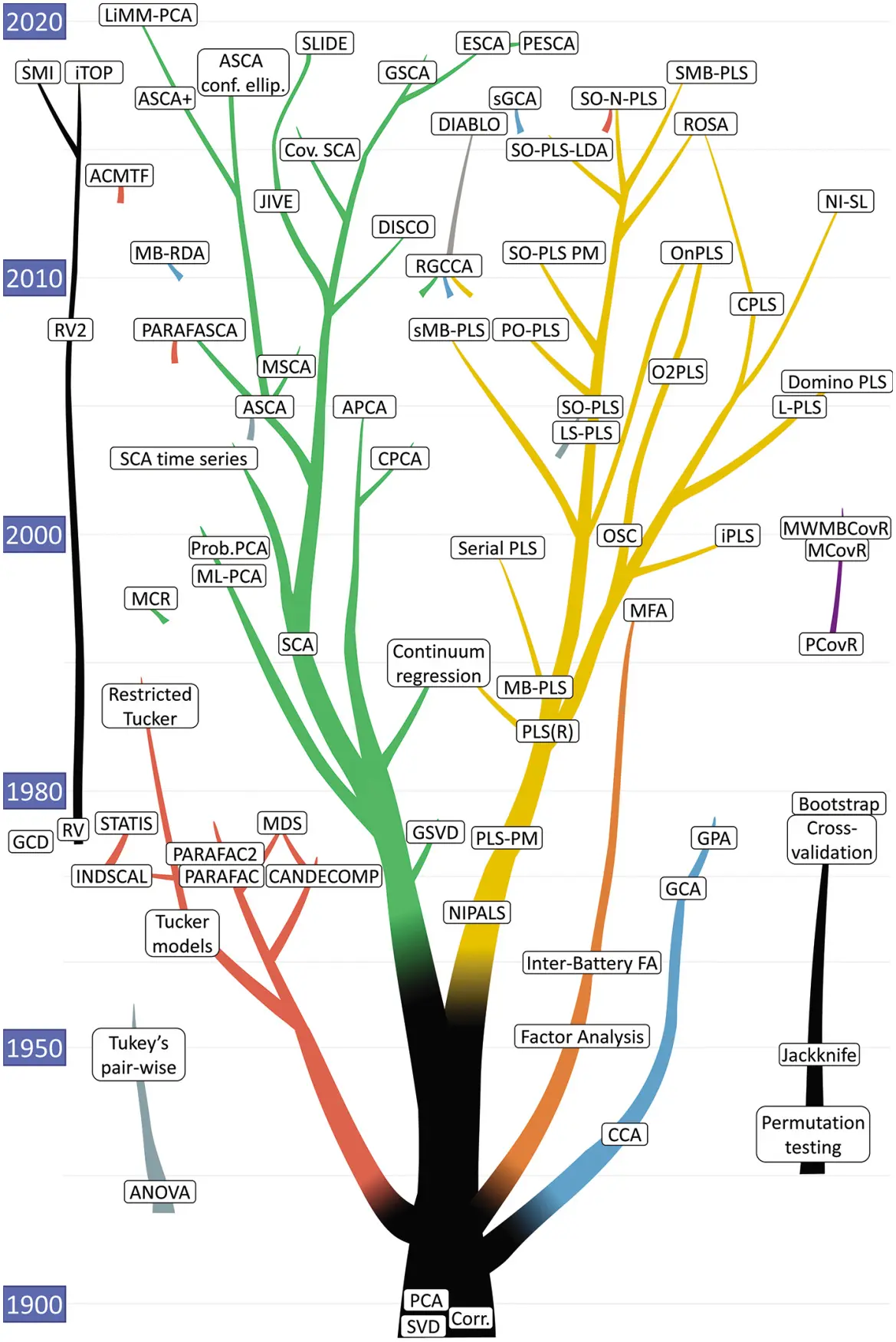
Figure 1.8 Phylogeny of some multiblock methods and relations to basic data analysis methods used in this book.
1.7 Fundamental Choices
In any sort of multiblock data analysis, choices have to be made such as which method to use and what kind of pre-processing to apply. Two fundamental questions which always should be considered (and dealt with) are highlighted below.
Variation explained:Do we only want to explain variation between blocks or also within blocks?Fairness:Should all blocks play a role in the final solution or can we allow some of the blocks to be dominant in this respect?
The first concept – variation explained – pertains to the choice that we can model the variation within the blocks and/or the variation between the blocks. Each multiblock data analysis method makes a different choice in this respect and thus it is up to the user to decide what aspect is the most important: between- or within-variation. A more detailed account is given in Section 2.4.
The concept of fairness relates to the notion that each block should participate in the final solution to a certain degree. Multiblock data analysis methods also differ in this respect: some methods are fair and some are ‘block selectors’ (Smilde et al ., 2003; Tenenhaus et al ., 2017). To some extent, fairness can be influenced by block-scaling (see Section 2.6), but some methods are invariant to this type of scaling. The method ROSA (see Section 7.5) builds on the principle of fairness: each block is allowed to enter the solution in competition with the other blocks: if it is important then it will be included. The fairness concept has some relation to the concept of invariance discussed in Chapter 7.
1.8 Common and Distinct Components
A crucial concept that plays a role in almost all methods in this book is the idea of common and distinct subspaces and components (Smilde et al ., 2017). A schematic illustration of these concepts is shown in Figure 1.9 and a more detailed exposure of these concepts is given in Chapter 2.
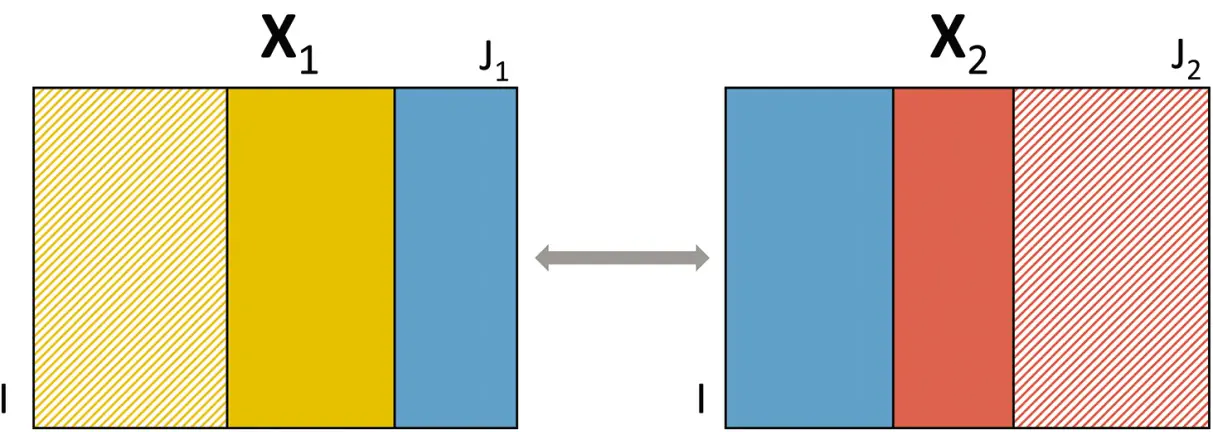
Figure 1.9 The idea of common and distinct components. Legend: blue is common variation; dark yellow and dark red are distinct variation and shaded areas are noise (unsystematic variation).
Suppose there are two data blocks X1 and X2 sharing the same samples, i.e., different variables are measured on the same set of samples (see Chapter 3). Then these two blocks can have variation in common (the blue part). This common variation spans a subspace and the common components are then a basis for this subspace.
There is also a part in each block that contains still systematic variation (the dark yellow and dark red parts). These have nothing in common and are, therefore, called distinct parts. These also represent subspaces and the distinct components (two sets; one set for each block) are the bases for these subspaces. What is left in the matrices is unsystematic variation or noise (shaded parts).
The division of each data block in common, distinct, and unsystematic variation should not be read in terms of the individual variables being in common or being distinct but in terms of subspaces. Hence, a part of the variation of a variable in block 1 may be in common with variation of some variables in block 2 whereas the other part of that variable may be distinct, see Elaboration 1.8.
ELABORATION 1.8
Common and distinct in spectroscopy
Suppose that the same set of samples is measured in the UV-Vis regime (block X1) and with near-infrared (NIR, block X2). Also assume that this set of samples contains three chemical components (A,B,C): A absorbs both in UV-Vis and NIR; B only absorbs in the UV-Vis regime and C absorbs only in NIR. Then the common part is the absorption of A in both data blocks; the distinct parts are B in block 1 and C in block 2. However, at a particular wavelength in the NIR region there may be a contribution from both A and C. Hence, this wavelength, i.e., variable, has a common and a distinct part. The same can happen in block 1.
Читать дальшеИнтервал:
Закладка:
Похожие книги на «Multiblock Data Fusion in Statistics and Machine Learning»
Представляем Вашему вниманию похожие книги на «Multiblock Data Fusion in Statistics and Machine Learning» списком для выбора. Мы отобрали схожую по названию и смыслу литературу в надежде предоставить читателям больше вариантов отыскать новые, интересные, ещё непрочитанные произведения.












Обсуждение, отзывы о книге «Multiblock Data Fusion in Statistics and Machine Learning» и просто собственные мнения читателей. Оставьте ваши комментарии, напишите, что Вы думаете о произведении, его смысле или главных героях. Укажите что конкретно понравилось, а что нет, и почему Вы так считаете.