Каниа Кан - Нейронные сети. Эволюция
Здесь есть возможность читать онлайн «Каниа Кан - Нейронные сети. Эволюция» — ознакомительный отрывок электронной книги совершенно бесплатно, а после прочтения отрывка купить полную версию. В некоторых случаях можно слушать аудио, скачать через торрент в формате fb2 и присутствует краткое содержание. Год выпуска: 2020, Жанр: Прочая научная литература, на русском языке. Описание произведения, (предисловие) а так же отзывы посетителей доступны на портале библиотеки ЛибКат.

- Название:Нейронные сети. Эволюция
- Автор:
- Жанр:
- Год:2020
- ISBN:нет данных
- Рейтинг книги:4 / 5. Голосов: 1
-
Избранное:Добавить в избранное
- Отзывы:
-
Ваша оценка:
Нейронные сети. Эволюция: краткое содержание, описание и аннотация
Предлагаем к чтению аннотацию, описание, краткое содержание или предисловие (зависит от того, что написал сам автор книги «Нейронные сети. Эволюция»). Если вы не нашли необходимую информацию о книге — напишите в комментариях, мы постараемся отыскать её.
Нейронные сети. Эволюция — читать онлайн ознакомительный отрывок
Ниже представлен текст книги, разбитый по страницам. Система сохранения места последней прочитанной страницы, позволяет с удобством читать онлайн бесплатно книгу «Нейронные сети. Эволюция», без необходимости каждый раз заново искать на чём Вы остановились. Поставьте закладку, и сможете в любой момент перейти на страницу, на которой закончили чтение.
Интервал:
Закладка:
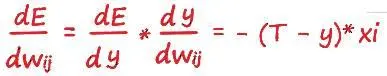
Всё получилось! Это и есть то выражение, которое мы искали. Это ключ к тренировке эволюционировавшего нейрона.
Как мы обновляем весовые коэффициенты
Найдя производную ошибки, вычислив тем самым наклон функции ошибки (подсветив фонариком, подходящий участок для спуска), нам необходимо обновить наш вес в сторону уменьшения ошибки (сделать шаг в сторону подсвеченного фонарем участка). Затем повторяем те же действия, но уже с новыми (обновлёнными) значениями.
Для понимания как мы будем обновлять наши коэффициенты (делать шаги в нужном направлении), прибегнем к помощи так уже нам хорошо знакомой – иллюстрации. Напомню, величина шага зависит от крутизны наклона прямой (tgφ). А значит величина, на которую мы обновляем наши веса, в соответствии со своим входом, и будет величиной производной по функции ошибки:
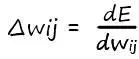
Вот теперь иллюстрируем:
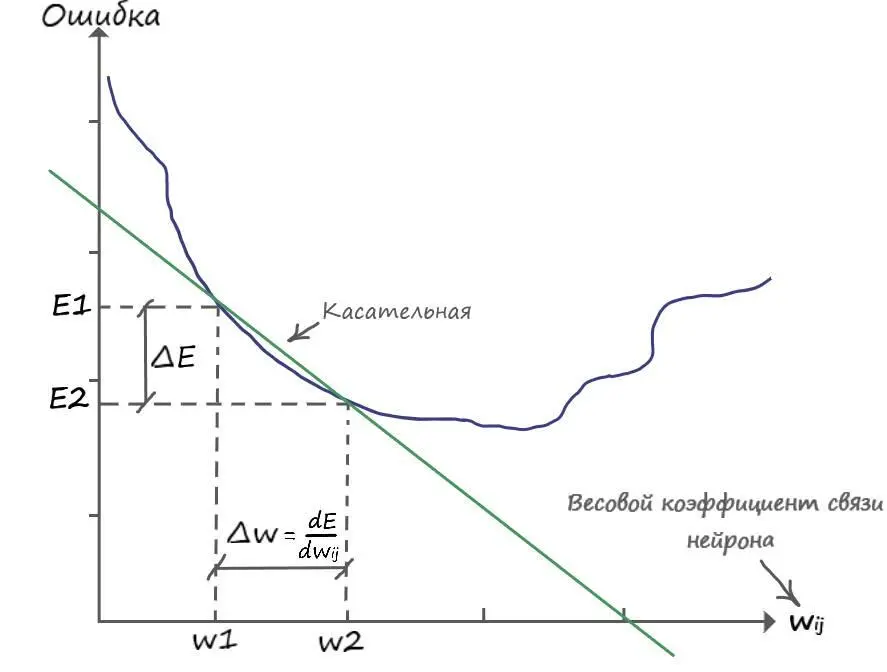
Из графика видно, что для того чтобы обновить вес в большую сторону, до значения ( w2), нужно к старому значению ( w1) прибавить дельту ( ∆w), откуда: ( w2 = =w1+∆w). Приравняв ( ∆w) к производной ошибки (величину которой уже знаем), мы спускаемся на эту величину в сторону уменьшения ошибки.
Так же замечаем, что ( E 2 – E 1 = -∆ E) и ( w 2 – w 1 = ∆ w), откуда делаем вывод:
∆ w = -∆ E /∆ w
Ничего не напоминает? Это почти то же, что и дельта линейного классификатора ( ∆А = E/х), подтверждение того что наша эволюция прошла с поэтапным улучшением математического моделирования. Таким же образом, как и с обновлением коэффициента ( А = А+∆А), линейного классификатора, обновляем весовые коэффициенты:
новый w ij = старый w ij -( – ∆ E /∆ w )
Знак минус, для того чтобы обновить вес в большую сторону, для уменьшения ошибки. На примере графика – от w1до w2.
В общем виде выражение записывается как:
новый w ij = старый w ij – dE/ dw ij
Еще одно подтверждение, постепенного, на основе старого аппарата, хода эволюции, в сторону улучшения классификации искусственного нейрона.
Теперь, зайдем с другой стороны функции ошибки:
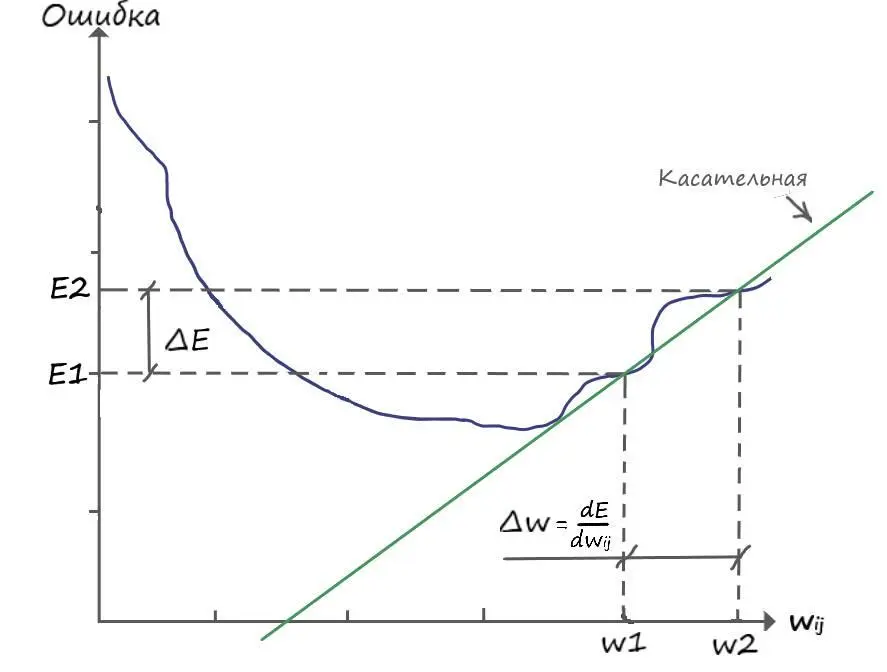
Снова замечаем, что ( E 2 – E 1 = ∆ E) и ( w 2 – w 1 = ∆ w), откуда делаем вывод:
∆ w = ∆ E /∆ w
В этом случае, для обновления весового коэффициента, в сторону снижения функции ошибки, а значит до значения находящееся левее ( w1), необходимо от значения ( w1) вычесть дельту ( ∆w):
новый w ij = старый w ij - ∆ E /∆ w
Получается, что независимо от того, какого знака производная ошибки от весового коэффициента по входу, вычитая из старого значения – значение этой производной, мы движемся в сторону уменьшения функции ошибки. Откуда можно сделать вывод, что последнее выражение, общее для всех возможных случаев обновления градиента.
Запишем еще раз, обновление весовых коэффициентов в общем виде:
новый w ij = старый w ij – dE/ dw ij
Но мы забыли еще об одной важной особенности… Сглаживания! Без сглаживания величины дельты обновления, наши шаги будут слишком большие. Мы подобно кенгуру, будем прыгать на большие расстояния и можем перескочить минимум ошибки! Используем прошлый опыт, чтоб устранить этот недочёт.
Вспоминаем старое выражение при нахождении сглаженного значения дельты линейного классификатора: ∆А = L*(Е/х). Где ( L) – скорость обучения, необходимая для того, чтобы мы делали спуск, постепенно, небольшими шашками.
Читать дальшеИнтервал:
Закладка:
Похожие книги на «Нейронные сети. Эволюция»
Представляем Вашему вниманию похожие книги на «Нейронные сети. Эволюция» списком для выбора. Мы отобрали схожую по названию и смыслу литературу в надежде предоставить читателям больше вариантов отыскать новые, интересные, ещё непрочитанные произведения.












Обсуждение, отзывы о книге «Нейронные сети. Эволюция» и просто собственные мнения читателей. Оставьте ваши комментарии, напишите, что Вы думаете о произведении, его смысле или главных героях. Укажите что конкретно понравилось, а что нет, и почему Вы так считаете.