Виталий Скляр - Организация и математическое планирование эксперимента. Учебное пособие
Здесь есть возможность читать онлайн «Виталий Скляр - Организация и математическое планирование эксперимента. Учебное пособие» — ознакомительный отрывок электронной книги совершенно бесплатно, а после прочтения отрывка купить полную версию. В некоторых случаях можно слушать аудио, скачать через торрент в формате fb2 и присутствует краткое содержание. ISBN: , Издательство: Литагент Ридеро, Жанр: Прочая научная литература, на русском языке. Описание произведения, (предисловие) а так же отзывы посетителей доступны на портале библиотеки ЛибКат.

- Название:Организация и математическое планирование эксперимента. Учебное пособие
- Автор:
- Издательство:Литагент Ридеро
- Жанр:
- Год:неизвестен
- ISBN:9785448522840
- Рейтинг книги:4 / 5. Голосов: 1
-
Избранное:Добавить в избранное
- Отзывы:
-
Ваша оценка:
Организация и математическое планирование эксперимента. Учебное пособие: краткое содержание, описание и аннотация
Предлагаем к чтению аннотацию, описание, краткое содержание или предисловие (зависит от того, что написал сам автор книги «Организация и математическое планирование эксперимента. Учебное пособие»). Если вы не нашли необходимую информацию о книге — напишите в комментариях, мы постараемся отыскать её.
Организация и математическое планирование эксперимента. Учебное пособие — читать онлайн ознакомительный отрывок
Ниже представлен текст книги, разбитый по страницам. Система сохранения места последней прочитанной страницы, позволяет с удобством читать онлайн бесплатно книгу «Организация и математическое планирование эксперимента. Учебное пособие», без необходимости каждый раз заново искать на чём Вы остановились. Поставьте закладку, и сможете в любой момент перейти на страницу, на которой закончили чтение.
Интервал:
Закладка:
Допустим произведено n измерений случайной величины X и получены значения х 1, х 2 … х n. При этом если речь идет о дискретной случайной величине, то она примет определенные значения случайное число раз, обозначим это число m. Если речь идет о непрерывной случайной величине, то весь диапазон ее изменения разбивается на несколько интервалов и подсчитывается количество попаданий в каждый из интервалов. Вероятность того что дискретная величина примет какое-либо значение (или попадет в определенный интервал) в этом случае будет:

где m – число наблюдений, в которых дискретная случайная величина X оказалась равна x; n – общее количество наблюдений.
Сумма вероятностей всех возможных значений дискретной случайной величины (или попаданий во все интервалы для непрерывной) равна единице.
Для оценки распределения случайной величины используют функцию распределения и плотность распределения.
Функция распределения F (x) – это интегральная функция, которая показывает вероятность того, что случайная величина Х принимает значение не больше, чем х :
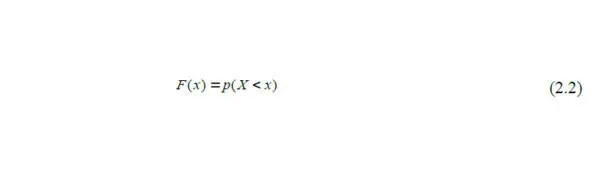
Функция распределения должна иметь возрастающий характер.
Плотность распределения f (x) – это дифференциальная функция – производная функции распределения, которая определяется как:
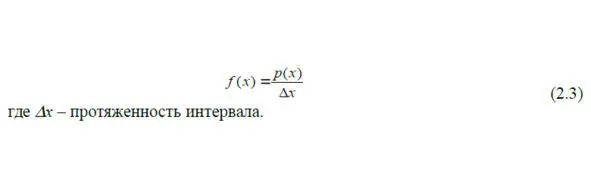
Для правильной обработки экспериментальных данных необходимо знать закон распределения, однако для его точного определения необходимо обработать большой объем экспериментальной информации.
Пример. На предприятии выпускается проволока различных диаметров. Отдел товарного контроля производит периодические замеры диаметра готовой проволоки. Результаты измерения (всего 50) проволоки диаметром 3,6 мм находятся в таблице 2.1. Значения диаметра проволоки отличаются друг от друга из-за того, что проволока производится в пределах допусков и диаметр может отличаться как в большую, так и в меньшую сторону и это не является нарушением технологии, также на результаты может влиять погрешность измерений.
Таблица 2.1 – Результаты замеров

Дальнейшую обработку данных ведем по следующей методике.
Для удобства необходимо отсортировать данные по порядку от большего к меньшему – таблица 2.2.
Для непрерывной случайной величины задают вероятность ее попадания в один из заданных интервалов области ее определения (поскольку вероятность того, что она примет какое-либо конкретное свое значение, стремится к нулю).
Таблица 2.2 – Упорядоченная таблица результатов замеров

Количество интервалов определяют по формуле
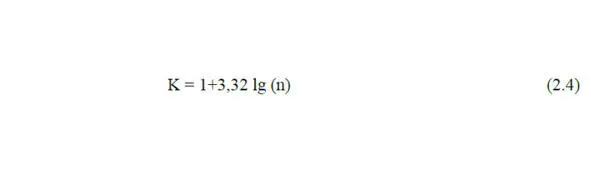
где n – количество измерений.
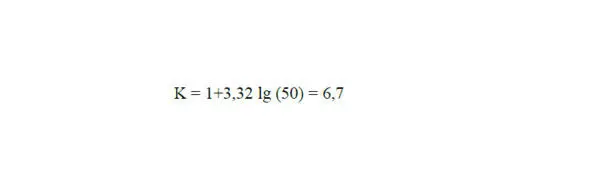
В качестве количества интервалов принимаем большее нечетное число – 7.
По таблице 2.2 определяем наибольшее и наименьшее значение х min= 3,4, х max= 3,8, диапазон изменений (размах) случайной величины L x= 3,8 – 3,4 = 0,4. Тогда продолжительность каждого из семи интервалов Δх = 0,4/7 = 0,057. Значение продолжительности интервала достаточно округлить на порядок больший, чем точность измерений случайной величины.
Таким образом, получим семь интервалов, границы которых приведены в таблице 2.3.
Теперь подсчитаем сколько раз случайная величина попала в каждый из интервалов, обозначим это значение – m, и частотную вероятность попадания в каждый интервал по формуле 2.1.
Например в интервал 3,4…3,457 попадает всего два значения из таблицы 2.2 – это 3,4 и 3,45, частотная вероятность в этом случае будет: р = 2/50 = 0,04, результаты для остальных интервалов приведены в таблице 2.3. Сумма всех вероятностей должна быть равна единице.
Читать дальшеИнтервал:
Закладка:
Похожие книги на «Организация и математическое планирование эксперимента. Учебное пособие»
Представляем Вашему вниманию похожие книги на «Организация и математическое планирование эксперимента. Учебное пособие» списком для выбора. Мы отобрали схожую по названию и смыслу литературу в надежде предоставить читателям больше вариантов отыскать новые, интересные, ещё непрочитанные произведения.











Обсуждение, отзывы о книге «Организация и математическое планирование эксперимента. Учебное пособие» и просто собственные мнения читателей. Оставьте ваши комментарии, напишите, что Вы думаете о произведении, его смысле или главных героях. Укажите что конкретно понравилось, а что нет, и почему Вы так считаете.