Всё о метрологии
Здесь есть возможность читать онлайн «Всё о метрологии» весь текст электронной книги совершенно бесплатно (целиком полную версию без сокращений). В некоторых случаях можно слушать аудио, скачать через торрент в формате fb2 и присутствует краткое содержание. Жанр: Прочая научная литература, на русском языке. Описание произведения, (предисловие) а так же отзывы посетителей доступны на портале библиотеки ЛибКат.
- Название:Всё о метрологии
- Автор:
- Жанр:
- Год:неизвестен
- ISBN:нет данных
- Рейтинг книги:4 / 5. Голосов: 1
-
Избранное:Добавить в избранное
- Отзывы:
-
Ваша оценка:
Всё о метрологии: краткое содержание, описание и аннотация
Предлагаем к чтению аннотацию, описание, краткое содержание или предисловие (зависит от того, что написал сам автор книги «Всё о метрологии»). Если вы не нашли необходимую информацию о книге — напишите в комментариях, мы постараемся отыскать её.
Всё о метрологии — читать онлайн бесплатно полную книгу (весь текст) целиком
Ниже представлен текст книги, разбитый по страницам. Система сохранения места последней прочитанной страницы, позволяет с удобством читать онлайн бесплатно книгу «Всё о метрологии», без необходимости каждый раз заново искать на чём Вы остановились. Поставьте закладку, и сможете в любой момент перейти на страницу, на которой закончили чтение.
Интервал:
Закладка:
Предположим, что θ( t i )=0, т.е. систематические погрешности тем или иным способом исключены из результатов наблюдений, и будем рассматривать только случайные погрешности, средние значения которых равны нулю в каждом сечении. Предположим далее, что случайные погрешности в различных сечениях не зависят друг от друга, т.е. знание случайной погрешности в одном сечении как ординаты одной реализации не дает нам никакой дополнительной информации о значении, принимаемом этой реализацией в любом другом сечении. Тогда случайную погрешность можно рассматривать как случайную величину, а ее значения при каждом из многократных наблюдений одной и той же физической величины — как ее эмпирические проявления, т.е. как результаты независимых наблюдений над ней.
В этих условиях случайная погрешность измерений δ определяется как разность между исправленным результатом Х измерения и истинным значением Q измеряемой величины:
δ = X - Q (3)
причем исправленным будем называть результат измерений, из которого исключены систематические погрешности.
При проведении измерений целью является оценка истинного значения измеряемой величины, которое до опыта неизвестно. Результат измерения включает в себя помимо истинного значения еще и случайную погрешность, следовательно, сам является случайной величиной. В этих условиях фактическое значение случайной погрешности, полученное при поверке, еще не характеризует точности измерений, поэтому не ясно, какое же значение принять за окончательный результат измерения и как охарактеризовать его точность.
Ответ на эти вопросы можно получить, используя при метрологической обработке результатов измерения методы математической статистики, имеющей дело именно со случайными величинами.
4.2. Описание случайных погрешностей с помощью функций распределения
Рассмотрим результат наблюдений Х за постоянной физической величиной Q как случайную величину, принимающую различные значения Z , в различных наблюдениях за ней. Значения X i будем называть результатами отдельных наблюдений.
Наиболее универсальный способ описания случайных величин заключается в отыскании их интегральных или дифференциальных функций распределения [1].
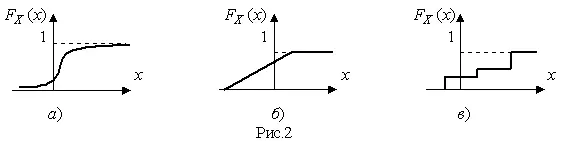
Под интегральной функцией распределения результатов наблюдений понимается зависимость вероятности того, что результат наблюдения X i в i -м опыте окажется меньшим некоторого текущего значения х , от самой величины х :
F x ( x ) = P ( X i ≤ x ) (4)
Здесь и в дальнейшем большие буквы используются для обозначения случайных величин, а маленькие — значений, принимаемых случайными величинами. Поскольку функция распределения вероятности представляет собой вероятность, то она удовлетворяет следующим свойствам:
• 0 ≤ F x ( x ) ≤ 1 при x ∈ (–∞, +∞),
• F x (–∞) = 0, F x (+∞) = 1,
• F x ( x ) — неубывающая функция x ,
• P( x 1< X < x 2) = F X ( x 2) – F X ( x 1).
На рис.2 показаны примеры функций распределения вероятности.
Более наглядным является описание свойств результатов наблюдений и случайных погрешностей с помощью дифференциальной функции распределения, иначе называемой плотностью распределения вероятностей :
f ( x ) = dF X ( x )/ dx (5)
Физический смысл f(x) состоит в том, что произведение f(x)dx представляет вероятность попадания случайной величины Х в интервал от х до х + dx , т.е.
f ( x ) dx = P ( x ≤ X ≤ x+dx ) (6)
Свойства плотности распределения вероятности:
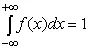 — вероятность достоверного события равна 1;
— вероятность достоверного события равна 1;
иными словами, площадь, заключенная между кривой дифференциальной функции распределения и осью абсцисс, равна единице;
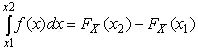 — вероятность попадания случайной величины в интервал от x 1до x 2.
— вероятность попадания случайной величины в интервал от x 1до x 2.
От дифференциальной функции распределения легко перейти к интегральной путем интегрирования:
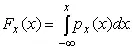 (7)
(7)
Размерность плотности распределения вероятностей, как это следует из формулы (7), обратна размерности измеряемой величины, поскольку сама вероятность — величина безразмерная.
Читать дальшеИнтервал:
Закладка:
Похожие книги на «Всё о метрологии»
Представляем Вашему вниманию похожие книги на «Всё о метрологии» списком для выбора. Мы отобрали схожую по названию и смыслу литературу в надежде предоставить читателям больше вариантов отыскать новые, интересные, ещё непрочитанные произведения.








Обсуждение, отзывы о книге «Всё о метрологии» и просто собственные мнения читателей. Оставьте ваши комментарии, напишите, что Вы думаете о произведении, его смысле или главных героях. Укажите что конкретно понравилось, а что нет, и почему Вы так считаете.