Надежда Ефремова - Тестовый контроль в образовании
Здесь есть возможность читать онлайн «Надежда Ефремова - Тестовый контроль в образовании» весь текст электронной книги совершенно бесплатно (целиком полную версию без сокращений). В некоторых случаях можно слушать аудио, скачать через торрент в формате fb2 и присутствует краткое содержание. Город: Москва, Год выпуска: 2007, ISBN: 2007, Издательство: Array Литагент «Логос», Жанр: Прочая научная литература, на русском языке. Описание произведения, (предисловие) а так же отзывы посетителей доступны на портале библиотеки ЛибКат.

- Название:Тестовый контроль в образовании
- Автор:
- Издательство:Array Литагент «Логос»
- Жанр:
- Год:2007
- Город:Москва
- ISBN:5–98704–138–4
- Рейтинг книги:5 / 5. Голосов: 1
-
Избранное:Добавить в избранное
- Отзывы:
-
Ваша оценка:
Тестовый контроль в образовании: краткое содержание, описание и аннотация
Предлагаем к чтению аннотацию, описание, краткое содержание или предисловие (зависит от того, что написал сам автор книги «Тестовый контроль в образовании»). Если вы не нашли необходимую информацию о книге — напишите в комментариях, мы постараемся отыскать её.
Предназначена студентам и аспирантам, а также преподавателям педагогических вузов.
Тестовый контроль в образовании — читать онлайн бесплатно полную книгу (весь текст) целиком
Ниже представлен текст книги, разбитый по страницам. Система сохранения места последней прочитанной страницы, позволяет с удобством читать онлайн бесплатно книгу «Тестовый контроль в образовании», без необходимости каждый раз заново искать на чём Вы остановились. Поставьте закладку, и сможете в любой момент перейти на страницу, на которой закончили чтение.
Интервал:
Закладка:
На практике исследователю необходимо задать себе вопрос, является ли неодинаковое число наблюдений в различных совокупностях в первоначальной выборке отражением истинного распределения или это только (случайный) результат процедуры выбора. В первом случае используются априорные вероятности пропорционально объемам совокупностей в выборке; во втором – априорные вероятности одинаковы для каждой совокупности. Спецификация различных априорных вероятностей может сильно влиять на точность классификации. Для увеличения точности классификаций используются апостериорные вероятности – это вероятности, вычисленные с использованием знания значений других переменных для образцов из частной совокупности. В последнее время созданы программные пакеты, автоматически вычисляющие апостериорные вероятности для различных видов наблюдений. Общим результатом является матрица классификации.
При повторной итерации апостериорная классификация того, что случилось в прошлом, не очень трудна. Нетрудно получить очень хорошую классификацию тех образцов, по которым была оценена функция классификации. Для получения сведений, насколько хорошо работает процедура классификации на самом деле, следует классифицировать (априорно) различные наблюдения, которые не использовались при оценке функции классификации, гибко использовать условия отбора для включения их в число наблюдений или, напротив, исключения. Матрица классификации может быть вычислена по старым образцам столь же успешно, как и по новым. Но только классификация новых наблюдений позволяет определить качество функции классификации, классификация старых наблюдений позволяет лишь провести успешную диагностику наличия выбросов или области, где функция классификации кажется менее адекватной.
Дискриминантный, дисперсионный и факторный анализ являются полезными инструментами для выделения переменных, позволяющих относить наблюдаемые объекты в одну или несколько реально наблюдаемых групп, а также для классификации наблюдений по группам и детального анализа состояния и качества объектов, проведения мониторинговых исследований.
Математический аппарат, используемый для обработки результатов ЕГЭ
(из проекта Типового положения о РЦОИ Псковской области)
1. Среднее арифметическое (простое):
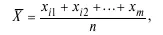
где n – число наблюдений; x i1, x i2, ..., x m – значения переменных.
2. Среднее арифметическое (взвешенное):
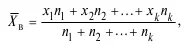
где x i1, x i2, ..., x n – значения переменных; n 1,n 2, ..., n k – веса переменных.
3. Мода:
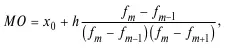
где x 0– нижняя граница модального интервала; h – величина интервала; f m –1– частота интервала, предшествующего модальному; f m + 1– частота интервала, следующего за модальным.
4. Среднее абсолютное (линейное) отклонение:
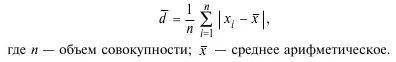
5. Эмпирическая дисперсия:
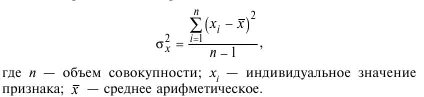
6. Стандартное (среднеквадратическое) отклонение:
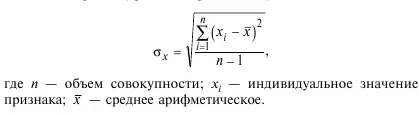
7. Коэффициент вариации Пирсона:
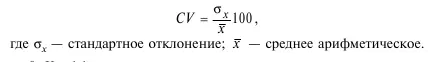
8. Коэффициент ассимиляции:
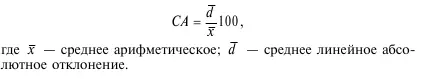
9. Размах (range):
Rx = x max − x min ,
где x max– наибольшее значение наблюдаемого признака; x minнаименьшее значение наблюдаемого признака.
10. Коэффициент корреляции Пирсона:
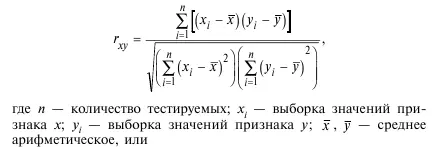
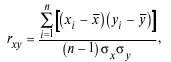
где σ x – стандартное отклонение по х; σ y – стандартное отклонение по у.
11. Коэффициент ранговой корреляции Спирмена:
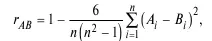
где n – число случаев; A i− B i – разность между индивидуальными рангами по х и у.
Читать дальшеИнтервал:
Закладка:
Похожие книги на «Тестовый контроль в образовании»
Представляем Вашему вниманию похожие книги на «Тестовый контроль в образовании» списком для выбора. Мы отобрали схожую по названию и смыслу литературу в надежде предоставить читателям больше вариантов отыскать новые, интересные, ещё непрочитанные произведения.












Обсуждение, отзывы о книге «Тестовый контроль в образовании» и просто собственные мнения читателей. Оставьте ваши комментарии, напишите, что Вы думаете о произведении, его смысле или главных героях. Укажите что конкретно понравилось, а что нет, и почему Вы так считаете.