Бен Орлин - Математика с дурацкими рисунками. Идеи, которые формируют нашу реальность
Здесь есть возможность читать онлайн «Бен Орлин - Математика с дурацкими рисунками. Идеи, которые формируют нашу реальность» — ознакомительный отрывок электронной книги совершенно бесплатно, а после прочтения отрывка купить полную версию. В некоторых случаях можно слушать аудио, скачать через торрент в формате fb2 и присутствует краткое содержание. Город: Москва, Год выпуска: 2020, ISBN: 2020, Издательство: Альпина нон-фикшн, Жанр: Математика, sci_popular, на русском языке. Описание произведения, (предисловие) а так же отзывы посетителей доступны на портале библиотеки ЛибКат.

- Название:Математика с дурацкими рисунками. Идеи, которые формируют нашу реальность
- Автор:
- Издательство:Альпина нон-фикшн
- Жанр:
- Год:2020
- Город:Москва
- ISBN:978-5-0013-9357-3
- Рейтинг книги:4.5 / 5. Голосов: 2
-
Избранное:Добавить в избранное
- Отзывы:
-
Ваша оценка:
Математика с дурацкими рисунками. Идеи, которые формируют нашу реальность: краткое содержание, описание и аннотация
Предлагаем к чтению аннотацию, описание, краткое содержание или предисловие (зависит от того, что написал сам автор книги «Математика с дурацкими рисунками. Идеи, которые формируют нашу реальность»). Если вы не нашли необходимую информацию о книге — напишите в комментариях, мы постараемся отыскать её.
Орлин выступает не только как педагог, но и как художник-иллюстратор: его смешные человечки и закорючки покорили тысячи школьников, покорят и вас. Изящные каламбуры и забавные ассоциации, игры разума и цифровые загадки (к каждой из которых вы получите элегантную и ироничную разгадку) и, конечно, знаменитые фирменные рисунки (которые, вопреки заглавию, не такие уж дурацкие) позволяют Орлину легко и остроумно доносить самые сложные и глубокие математические идеи и убеждают в том, что даже математика может быть страшно интересной.
Математика с дурацкими рисунками. Идеи, которые формируют нашу реальность — читать онлайн ознакомительный отрывок
Ниже представлен текст книги, разбитый по страницам. Система сохранения места последней прочитанной страницы, позволяет с удобством читать онлайн бесплатно книгу «Математика с дурацкими рисунками. Идеи, которые формируют нашу реальность», без необходимости каждый раз заново искать на чём Вы остановились. Поставьте закладку, и сможете в любой момент перейти на страницу, на которой закончили чтение.
Интервал:
Закладка:
Че-е-е-е-ерт!
Как и все статистические проекты, это исследование потребовало кардинального упрощения. Первый шаг авторов заключался в том, что они разъяли весь набор данных (пять миллионов книг, около 500 миллиардов слов) на так называемые 1-граммы. Они поясняют этот термин: «`1-грамма` — это набор символов, не прерываемых пробелом: слова („банан“, „скуби-дайвинг“), но, кроме того, числа (3,14 159) и опечатки („чересчурр“)».
Предложения, абзацы, тезисы — все это исчезает. Остаются лишь мельчайшие фрагменты текста.

Дабы исследовать данные глубже, авторы составили перечень 1-грамм, встречающихся с частотой не менее чем один раз на миллиард. Если оценить начало, середину и конец XX столетия, мы увидим, что словарный запас англоязычных авторов растет.
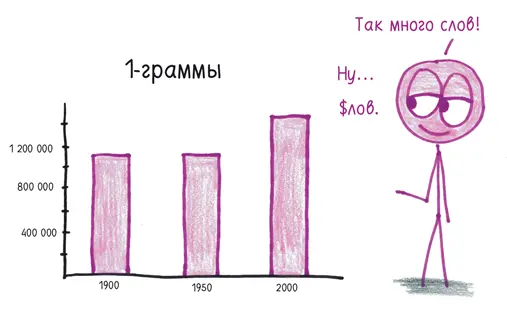
Выяснилось, что реальные слова на 1900 год составили меньше половины 1-грамм (по большей части это оказались числа, опечатки, аббревиатуры и т. д.), в то время как на 2000 год больше двух третей 1-грамм были именно слова. Проведя ручной подсчет в избранных фрагментах корпуса, авторы установили общее количество английских слов на каждый год.
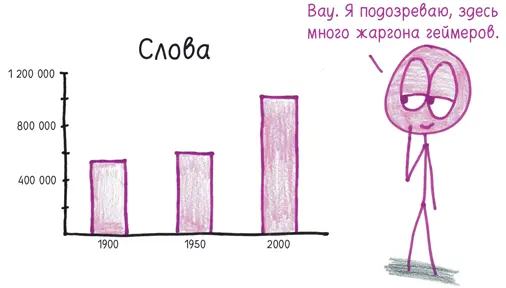
Затем, сопоставив массив 1-грамм с двумя популярными толковыми словарями, они обнаружили, что лексикографы с трудом успевают следить за разрастанием массива слов и держать руку на пульсе. В частности, словари упускают большую часть редких 1-грамм.
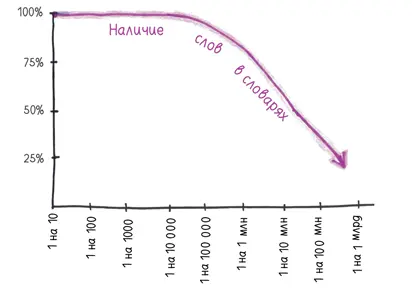
В тех текстах, которые читаю я, эти слова, не входящие в словари, почти не встречаются. Причина в том, что эти слова… ну… исключительные. Язык заселен тьмой никому не известных конструктов, встречающихся с частотой один раз на сто миллионов. В целом, по оценке авторов, «52 % всего английского лексикона (большинство слов, встречающихся в англоязычных книгах) состоят из лексической „темной материи“, упущенной в стандартных словарных статьях». Лексикографы просеивают тысячи тонн словесной руды, пропуская драгоценные камни наподобие «slenthem» (яванский металлофон).
Изучение лексикона было всего лишь разминкой для этих исследователей. Авторы продолжили изучать эволюцию грамматики, перепады популярности словоупотребления, признаки цензуры и переменчивые закономерности исторической памяти. Все это изложено лишь на дюжине страниц; в основном в статье представлены результаты отслеживания частотности тщательно выбранных 1-грамм.
У читателей отвисли челюсти. Редакция журнала Science , понимая масштабы происходящего, выложила статью в открытый доступ. «Новое окно в культуру», — провозгласила газета The New York Times [203].
Литературоведы склонны изучать привилегированный канон, тонкий слой элитных авторов, требующих глубокого, сосредоточенного анализа. Морррисон. Джойс. Кот, который улегся на клавиатуру Джойса и набрал «Поминки по Финнегану». Но исследователи выбрали иную модель: обширнейший корпус, в котором внимания заслуживает весь массив книг, от знаменитых до малоизвестных. Статистике удалось свергнуть олигархов и установить демократию.
Теперь нет причин, по которым оба подхода не могут идти рука об руку. Внимательное чтение и статистика. Канон и корпус. Тем не менее такие фразы, как «высокоточное измерение» [204], указывают на конфликт. Может ли смысл литературы быть измерен с высокой точностью? Насколько он в принципе поддается измерению? Или эти новые мощные инструменты уводят нас прочь от неведомых глубин искусства и мы просто забиваем гвозди микроскопом?
3. Эта фраза написана женщиной
Я склонен думать, что проза андрогинна. Мои тексты андрогинны, как морская губка, тексты Вирджинии Вулф — как галактика или божественное откровение. Но сама Вирджиния в книге «Своя комната» высказывает другую точку зрения [205]. К 1800 году, утверждает она, преобладающий литературный стиль стал приютом мужских, а не женских мыслей. В темпе и структуре самой прозы было нечто гендерное.
Эта идея крутилась у меня в голове несколько месяцев, пока я не набрел на онлайн-проект под названием «Под волшебным соусом» [206]. Помимо прочих алгоритмических подвигов, программа может прочесть выдержки из ваших текстов и с помощью таинственного анализа идентифицировать ваш пол.
Читать дальшеИнтервал:
Закладка:
Похожие книги на «Математика с дурацкими рисунками. Идеи, которые формируют нашу реальность»
Представляем Вашему вниманию похожие книги на «Математика с дурацкими рисунками. Идеи, которые формируют нашу реальность» списком для выбора. Мы отобрали схожую по названию и смыслу литературу в надежде предоставить читателям больше вариантов отыскать новые, интересные, ещё непрочитанные произведения.



![Приямвада Натараджан - Карта Вселенной [Главные идеи, которые объясняют устройство космоса]](/books/406358/priyamvada-nataradzhan-karta-vselennoj-glavnye-idei-thumb.webp)








Обсуждение, отзывы о книге «Математика с дурацкими рисунками. Идеи, которые формируют нашу реальность» и просто собственные мнения читателей. Оставьте ваши комментарии, напишите, что Вы думаете о произведении, его смысле или главных героях. Укажите что конкретно понравилось, а что нет, и почему Вы так считаете.