Денис Соломатин - mixOmics для гуманитариев
Здесь есть возможность читать онлайн «Денис Соломатин - mixOmics для гуманитариев» — ознакомительный отрывок электронной книги совершенно бесплатно, а после прочтения отрывка купить полную версию. В некоторых случаях можно слушать аудио, скачать через торрент в формате fb2 и присутствует краткое содержание. Год выпуска: 2021, ISBN: 2021, Жанр: Программы, Прочая научная литература, Прочая научная литература, на русском языке. Описание произведения, (предисловие) а так же отзывы посетителей доступны на портале библиотеки ЛибКат.

- Название:mixOmics для гуманитариев
- Автор:
- Жанр:
- Год:2021
- ISBN:978-5-532-96218-7
- Рейтинг книги:3 / 5. Голосов: 1
-
Избранное:Добавить в избранное
- Отзывы:
-
Ваша оценка:
mixOmics для гуманитариев: краткое содержание, описание и аннотация
Предлагаем к чтению аннотацию, описание, краткое содержание или предисловие (зависит от того, что написал сам автор книги «mixOmics для гуманитариев»). Если вы не нашли необходимую информацию о книге — напишите в комментариях, мы постараемся отыскать её.
mixOmics для гуманитариев — читать онлайн ознакомительный отрывок
Ниже представлен текст книги, разбитый по страницам. Система сохранения места последней прочитанной страницы, позволяет с удобством читать онлайн бесплатно книгу «mixOmics для гуманитариев», без необходимости каждый раз заново искать на чём Вы остановились. Поставьте закладку, и сможете в любой момент перейти на страницу, на которой закончили чтение.
Интервал:
Закладка:
Главные компоненты получены таким образом, чтобы их дисперсия была максимальной. С этой целью вычисляются собственные векторы и собственные значения матрицы дисперсии-ковариации, часто с помощью алгоритмов линейного разложения значения, когда количество переменных достаточно велико. Данные, как правило, центруют (опцией center = TRUE), а иногда и масштабируют (scale = TRUE) при вызове метода. Масштабирование рекомендуется применять в том случае, если дисперсия неоднородна по переменным.
Первая главная компонента (PC1) определяется линейной комбинацией исходных переменных, что объясняет наибольшее количество вариаций. Вторая главная компонента (PC2) затем определяется как линейное сочетание исходных переменных, на которые приходится наибольшее количество оставшегося объема вариаций ортогонального (несвязанного) с первым компонентом. Последующие компоненты определяются также для других размерностей PCA. Таким образом, пользователь должен сообщить, сколько информации объясняется первыми ПК, поскольку они используются для графического представления выходов PCA.
Сначала загружаем данные. Чтобы загрузить свои собственные данные можно воспользоваться следующей командой:
My_result.pca <���– pca(X) # 1 Запуск выбранного метода анализа
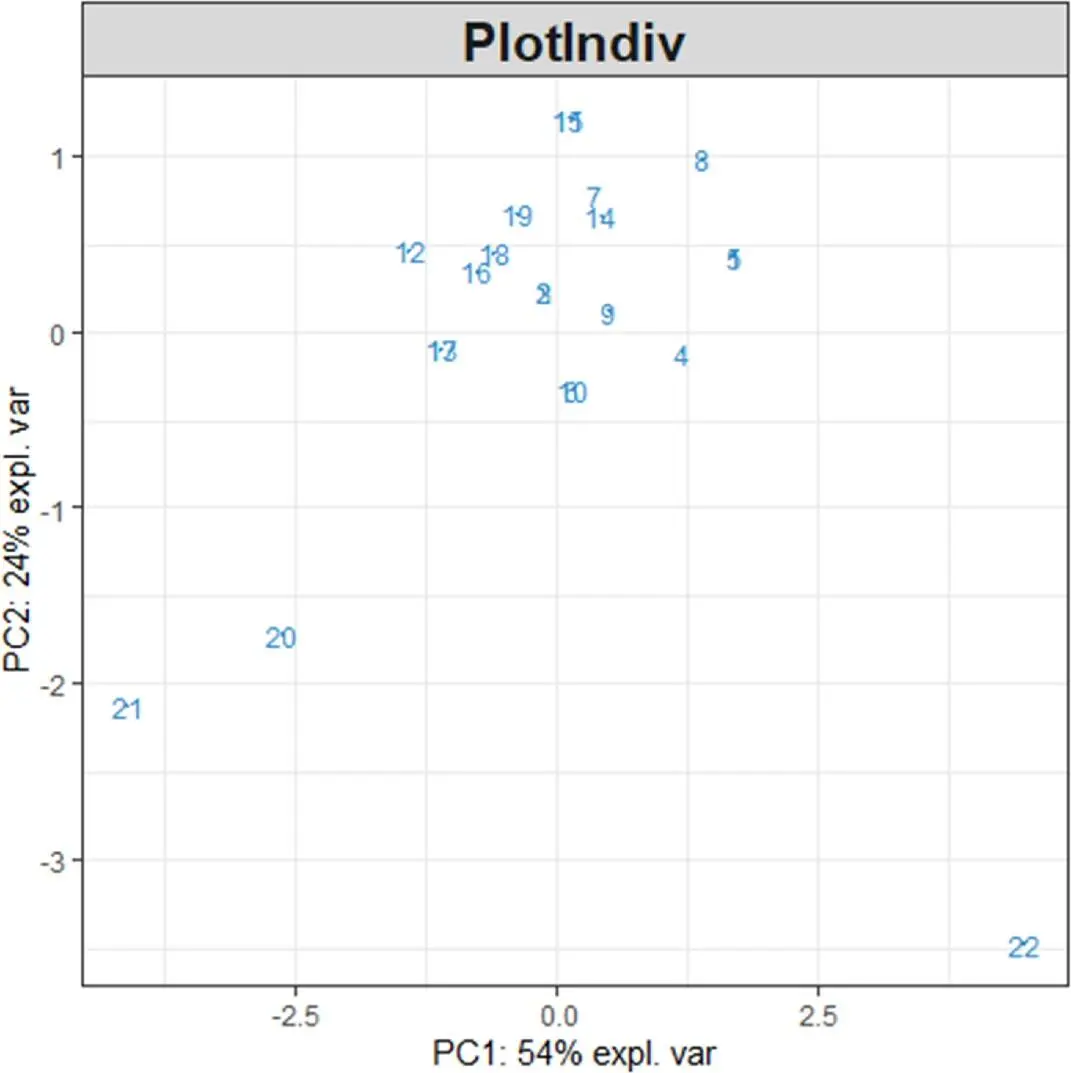
plotIndiv(My_result.pca) # 2 Визуальное представление образцов
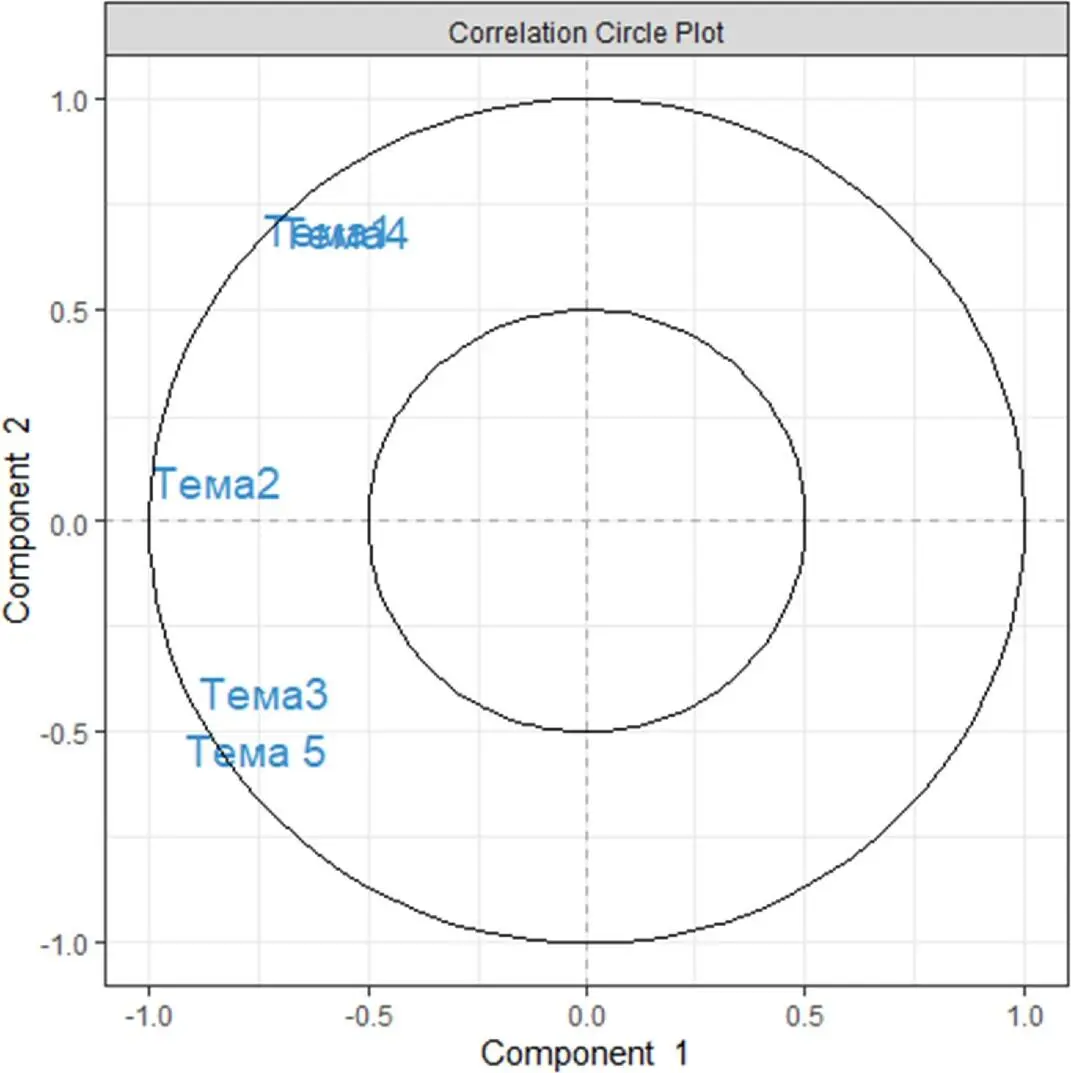
plotVar(My_result.pca) # 3 Визуальное представление переменных
Если запустить PCA этим минимальным кодом, то будут использоваться следующие значения по умолчанию:
1. ncomp = 2: лишь первые две главные компоненты рассчитываются и используются при построении диаграмм;
2. center = TRUE: данные отцентрованы (среднее значение равно 0);
3. scale = FALSE: данные не масштабируются. Если установить scale = TRUE, то алгоритм стандартизирует каждую переменную (дисперсия станет равной 1).
Другие параметры также могут быть настроены дополнительно, с полным списком настроек можно ознакомиться вызвав ?pca.
В примере, показанном выше, две пары тем не являются значительно отличающимися визуально, поэтому конкретные образцы должны быть дополнительно исследованы, тогда участок корреляционного круга, содержащий много переменных, можно будет легко интерпретировать. Ниже будет показано, как улучшить полученные диаграммы, чтобы облегчить интерпретацию результатов.
Диаграммы можно настроить с помощью многочисленных опций в plotIndiv и plotVar. Даже если PCA не принимает во внимание какую-либо информацию об известном членстве в группе каждой выборки, можно включить такую информацию в выборку для визуализации любого «естественного» кластера данных, который может быть обусловлен педагогической спецификой и условиями отбора группы.
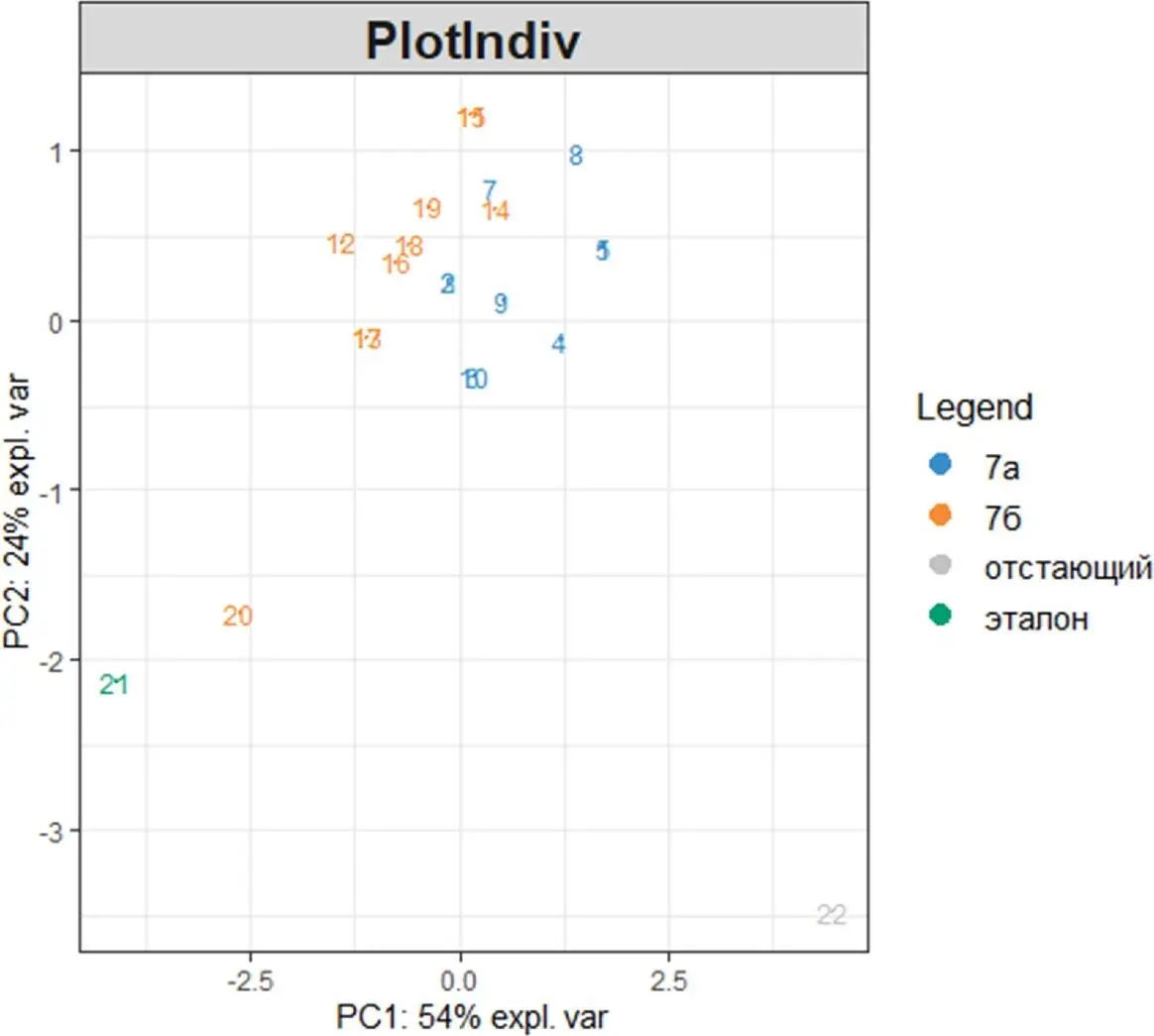
Так, например, следующая команда включает информацию о классе в группах выборки аргументом группирования:
plotIndiv(My_result.pca, group = My_table$Класс,
legend = TRUE)
Кроме того, два фактора могут отображаться с использованием как цветов (аргумент group), так и символов (аргумент pch). Например, отобразим класс и оценки, полученные по второй теме, изменив при этом название и легенду диаграммы:
plotIndiv(My_result.pca, ind.names = FALSE,
group = My_table$'Класс',
pch = as.factor(My_table$'Тема2'),
legend = TRUE, title = 'Успеваемость по второй теме',
legend.title = 'Класс', legend.title.pch = 'Оценка')
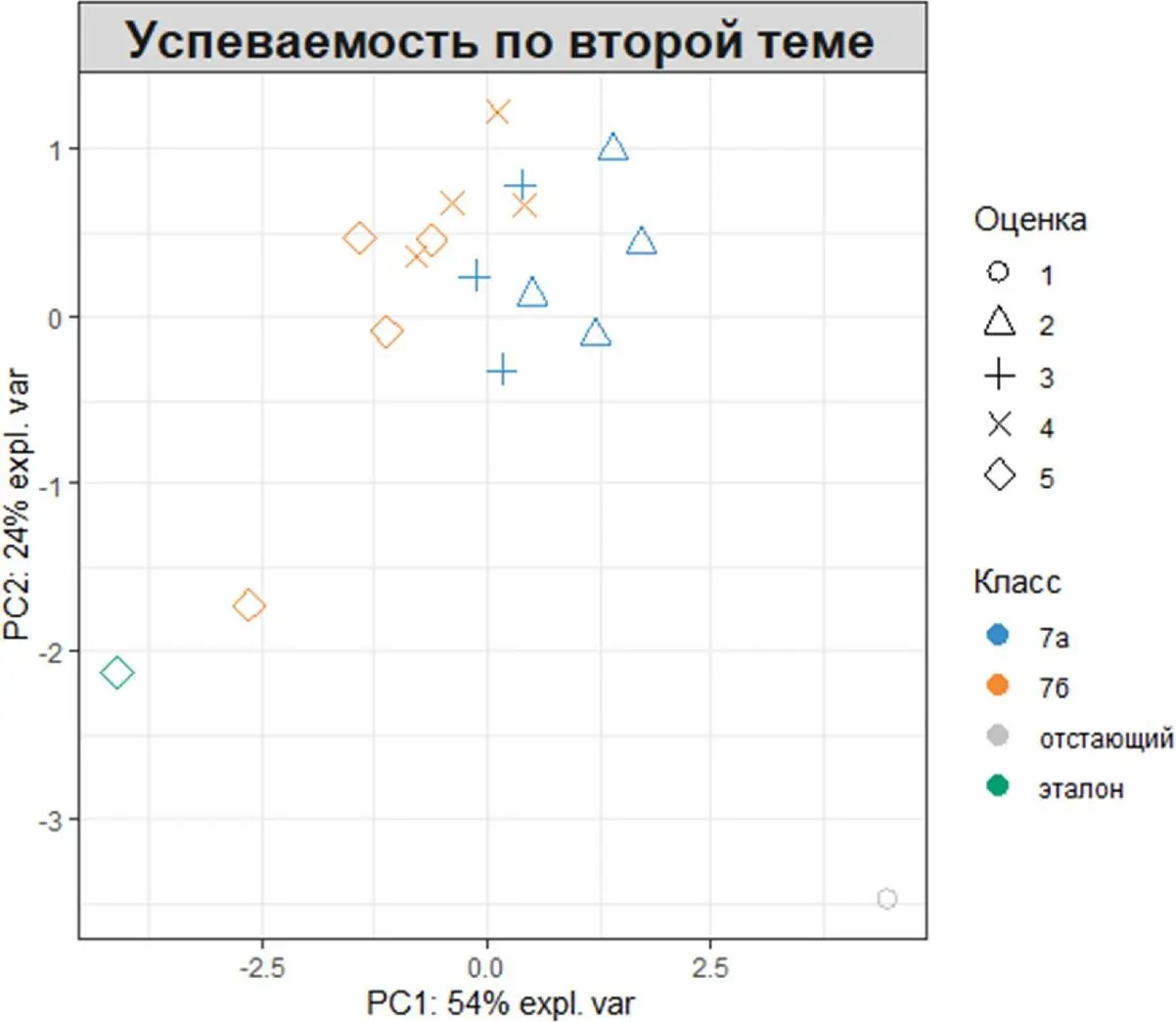
Путем добавления информации, связанной с классом и оценкой появляется возможность увидеть кластер наблюдений успеваемости близких к эталонному образцу (зелёный ромб в левом нижнем углу), в то время как образцы с низкой успеваемостью (синие треугольники) оказались сгруппированы отдельно, но явно обнаруживается эффект разделения обучающихся на классы.
Чтобы отобразить результаты на других компонентах, можно изменить аргумент comp при условии, что было запрошено достаточно компонент для расчета. Приведём второй пример PCA с тремя компонентами, в котором третий компонент по оси PC3 четко разграничивает обучающихся по классам:
My_result.pca2 <���– pca(X, ncomp = 3)
plotIndiv(My_result.pca2,
comp = c(1,3),
legend = TRUE,
group = My_table$'Класс',
legend.title = 'Класс',
title = 'Анализ успеваемости, PCA 1-3')
Читать дальшеИнтервал:
Закладка:
Похожие книги на «mixOmics для гуманитариев»
Представляем Вашему вниманию похожие книги на «mixOmics для гуманитариев» списком для выбора. Мы отобрали схожую по названию и смыслу литературу в надежде предоставить читателям больше вариантов отыскать новые, интересные, ещё непрочитанные произведения.











Обсуждение, отзывы о книге «mixOmics для гуманитариев» и просто собственные мнения читателей. Оставьте ваши комментарии, напишите, что Вы думаете о произведении, его смысле или главных героях. Укажите что конкретно понравилось, а что нет, и почему Вы так считаете.