Денис Соломатин - Основы статистической обработки педагогической информации
Здесь есть возможность читать онлайн «Денис Соломатин - Основы статистической обработки педагогической информации» — ознакомительный отрывок электронной книги совершенно бесплатно, а после прочтения отрывка купить полную версию. В некоторых случаях можно слушать аудио, скачать через торрент в формате fb2 и присутствует краткое содержание. Год выпуска: 2020, ISBN: 2020, Жанр: Программирование, management, Детская образовательная литература, на русском языке. Описание произведения, (предисловие) а так же отзывы посетителей доступны на портале библиотеки ЛибКат.

- Название:Основы статистической обработки педагогической информации
- Автор:
- Жанр:
- Год:2020
- ISBN:978-5-532-04389-3
- Рейтинг книги:5 / 5. Голосов: 1
-
Избранное:Добавить в избранное
- Отзывы:
-
Ваша оценка:
Основы статистической обработки педагогической информации: краткое содержание, описание и аннотация
Предлагаем к чтению аннотацию, описание, краткое содержание или предисловие (зависит от того, что написал сам автор книги «Основы статистической обработки педагогической информации»). Если вы не нашли необходимую информацию о книге — напишите в комментариях, мы постараемся отыскать её.
Основы статистической обработки педагогической информации — читать онлайн ознакомительный отрывок
Ниже представлен текст книги, разбитый по страницам. Система сохранения места последней прочитанной страницы, позволяет с удобством читать онлайн бесплатно книгу «Основы статистической обработки педагогической информации», без необходимости каждый раз заново искать на чём Вы остановились. Поставьте закладку, и сможете в любой момент перейти на страницу, на которой закончили чтение.
Интервал:
Закладка:
Когда начнете выполнять код R, возможны некоторые затруднения. Не волнуйтесь, это случается со всеми. Автор книги тоже писал код R, в течение многих лет, который работает не сразу. Начните с тщательного сравнения кода, который используете, с кодом из книги. R чрезвычайно придирчив. Убедитесь, что каждая открывающаяся скобка «(«соответствует закрывающейся «)», а каждая кавычка «"» имеет парную «"». Иногда запускаете код, но ничего не происходит. Проверьте содержимое левого нижнего угла консоли: если там «+», это означает, что R ничего не делает, просто набрали не полное выражение, и он ждет завершения ввода. В этом случае можно начать с начала, нажав клавишу ESC, чтобы прервать обработку текущей команды.
Частая ошибка при создании графиков ggplot2 это расположение «+» в неправильном месте, он должен находиться в конце строки, а не в начале. Убедитесь, что не сделали этого случайно. Если всё ещё в тупике, попробуйте обратиться к справочной информации. Для получения развернутой справки о любой функции R достаточно ввести команду ?имя_функции в консоли, или выделить имя интересующей функции и нажать клавишу F1 в RStudio. Не волнуйтесь, если справки не кажется, бывает полезным вместо этого перейти к примерам и найти код, который соответствует тому, что пытаетесь сделать. Если и это не помогает, то внимательно перечитайте сообщение об ошибке. Иногда ответ содержится именно там. Просто для начинающих пользователей R, ответ может находиться в сообщении об ошибке, но не приходит его понимания. Еще одним отличным инструментом является Yandex, попробуйте поискать сообщение об ошибке в интернете, так как возможно, у кого-то была аналогичная проблема, и её решение описали на специализированных онлайн-форумах.
Как было показано выше, один из способов добавить дополнительные измерения на графике, это художественные вариации эстетических параметров. Но есть ещё один способ, особенно полезный для категориальных переменные, – это разбивка графика на фрагменты, подзадачи, каждая из которых заключается в отображении некоторого подмножества анализируемых данных.
Чтобы собрать свой график из нескольких фрагментов от одной одной переменной, используйте facet_wrap(). Первым аргументом функции facet_wrap() должна быть именем структуры данных в R, которое начинается с символа «~», за которым следует имя переменной. Переменная, передаваемая в функцию facet_wrap(), должна быть дискретной. Например, следующая команда:
ggplot(data = mpg) +
geom_point(mapping = aes(x = displ, y = hwy)) +
facet_wrap(~ class, nrow = 1)
разобьет общее изображение данных известной уже нам базы на фрагментарные части, расположив их одной строкой, так как указано nrow = 1:
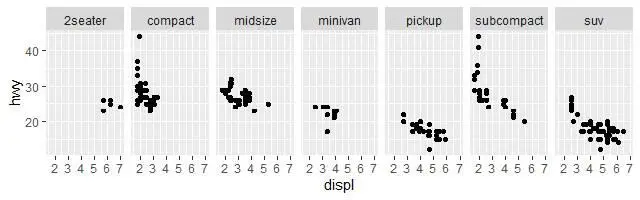
Чтобы расположить группы данных фрагментами на сетке, можно использовать комбинацию из двух переменных, добавив функцию facet_grid() к вызову графопостроителя. Первый аргумент в этом случае на этот раз будет содержать два имени переменных, разделенных знаком «~»:
ggplot(data = mpg) +
geom_point(mapping = aes(x = displ, y = hwy)) +
facet_grid(drv ~ cyl)
Если необходимо расположить группы только по одной переменной, в одну строку, либо в столбец, то достаточно поставить «.» вместо имени второй переменной. Так, например окончание +facet_grid(cyl ~ .) предпишет расположить графики вертикально, сгруппировав автомобили по числу цилиндров.
Упражнения
1. Что произойдет, если будете группировать данные по непрерывной переменной?
2. Что означают пустые ячейки на графике с facet_grid(drv~cyl)?
3. Каковы преимущества использования группирования данных частями по сравнению с цветовым выделением точек на одном графике? Каковы их недостатки? Как соблюдать баланс достоинств и недостатков этих подходов на больших объемах данных?
4. Прочитайте справку по ?facet_wrap. Что регулируется параметрами nrow, ncol? Какие ещё параметры управляют компоновкой? Почему функция facet_grid() не имеет аргументов nrow и ncol?
5. При использовании facet_grid() рекомендуется в столбцах располагать переменные с большим количеством уникальных значений. Почему?
Вернёмся к данным о результатах обучения. Во введении использовалась таблица с оценками успеваемости, которую можно воспроизвести следующей командой консоли:
My_table <���– structure(list(Класс = c("7а", "7а", "7а", "7а", "7а", "7а", "7а", "7а", "7а",
"7а", "7б", "7б", "7б", "7б", "7б", "7б", "7б", "7б", "7б", "7б", "эталон", "отстающий"),
`Фимилия Имя` = c("Иванов Иван", "Петров Петр", "Сидоров Сидор", "Егоров Егор",
Читать дальшеИнтервал:
Закладка:
Похожие книги на «Основы статистической обработки педагогической информации»
Представляем Вашему вниманию похожие книги на «Основы статистической обработки педагогической информации» списком для выбора. Мы отобрали схожую по названию и смыслу литературу в надежде предоставить читателям больше вариантов отыскать новые, интересные, ещё непрочитанные произведения.












Обсуждение, отзывы о книге «Основы статистической обработки педагогической информации» и просто собственные мнения читателей. Оставьте ваши комментарии, напишите, что Вы думаете о произведении, его смысле или главных героях. Укажите что конкретно понравилось, а что нет, и почему Вы так считаете.