Энтони Уильямс - Параллельное программирование на С++ в действии. Практика разработки многопоточных программ
Здесь есть возможность читать онлайн «Энтони Уильямс - Параллельное программирование на С++ в действии. Практика разработки многопоточных программ» весь текст электронной книги совершенно бесплатно (целиком полную версию без сокращений). В некоторых случаях можно слушать аудио, скачать через торрент в формате fb2 и присутствует краткое содержание. Город: Москва, Год выпуска: 2012, ISBN: 2012, Издательство: ДМК Пресс, Жанр: Программирование, на русском языке. Описание произведения, (предисловие) а так же отзывы посетителей доступны на портале библиотеки ЛибКат.

- Название:Параллельное программирование на С++ в действии. Практика разработки многопоточных программ
- Автор:
- Издательство:ДМК Пресс
- Жанр:
- Год:2012
- Город:Москва
- ISBN:978-5-94074-448-1
- Рейтинг книги:4 / 5. Голосов: 1
-
Избранное:Добавить в избранное
- Отзывы:
-
Ваша оценка:
Параллельное программирование на С++ в действии. Практика разработки многопоточных программ: краткое содержание, описание и аннотация
Предлагаем к чтению аннотацию, описание, краткое содержание или предисловие (зависит от того, что написал сам автор книги «Параллельное программирование на С++ в действии. Практика разработки многопоточных программ»). Если вы не нашли необходимую информацию о книге — напишите в комментариях, мы постараемся отыскать её.
Книга «Параллельное программирование на С++ в действии» не предполагает предварительных знаний в этой области. Вдумчиво читая ее, вы научитесь писать надежные и элегантные многопоточные программы на С++11. Вы узнаете о том, что такое потоковая модель памяти, и о том, какие средства поддержки многопоточности, в том числе запуска и синхронизации потоков, имеются в стандартной библиотеке. Попутно вы познакомитесь с различными нетривиальными проблемами программирования в условиях параллелизма.
Параллельное программирование на С++ в действии. Практика разработки многопоточных программ — читать онлайн бесплатно полную книгу (весь текст) целиком
Ниже представлен текст книги, разбитый по страницам. Система сохранения места последней прочитанной страницы, позволяет с удобством читать онлайн бесплатно книгу «Параллельное программирование на С++ в действии. Практика разработки многопоточных программ», без необходимости каждый раз заново искать на чём Вы остановились. Поставьте закладку, и сможете в любой момент перейти на страницу, на которой закончили чтение.
Интервал:
Закладка:
Чтобы продемонстрировать, до какой степени могут быть «ослаблены» операции в этой модели, достаточно всего двух потоков (см. листинг 5.5).
Листинг 5.5.К ослабленным операциям предъявляются очень слабые требования
#include
#include
#include
std::atomic x,y;
std::atomic z;
void write_x_then_y() {
x.store(true, std::memory_order_relaxed); ← (1)
y.store(true, std::memory_order_relaxed); ← (2)
}
void read_y_then_x() {
while (!y.load(std::memory_order_relaxed));← (3)
if (x.load(std::memory_order_relaxed)) ← (4)
++z;
}
int main() {
x = false;
y = false;
z = 0;
std::thread а(write_x_then_y);
std::thread b(read_y_then_x);
a.join();
b.join();
assert (z.load() != 0); ← (5)
}
На этот раз утверждение (5) может сработать, потому что операция загрузки x (4)может прочитать false, даже если загрузка y (3)прочитает true, а сохранение x (1)происходит-раньше сохранения y (2). xи y— разные переменные, поэтому нет никаких гарантий относительно порядка видимости результатов операций над каждой из них.
Ослабленные операции над разными переменными можно как угодно переупорядочивать при условии, что они подчиняются ограничивающим отношениям происходит-раньше (например, действующим внутри одного потока). Никаких отношений синхронизируется-с не возникает. Отношения происходит-раньше, имеющиеся в листинге 5.5, изображены на рис. 5.4, вместе с возможным результатом. Несмотря на то, что существует отношение происходит-раньше отдельно между операциями сохранения и операциями загрузки, не существует ни одного такого отношения между любым сохранением и любой загрузкой, поэтому операция загрузки может увидеть операции сохранения не в том порядке, в котором они происходили.
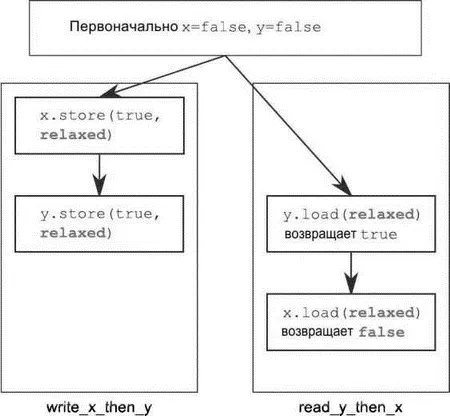
Рис. 5.4.Ослабленные атомарные операции и отношения происходит-раньше
Рассмотрим чуть более сложный пример с тремя переменными и пятью потоками.
Листинг 5.6.Ослабленные операции в нескольких потоках
#include
#include
#include
std::atomic x(0), y(0), z(0);← (1)
std::atomic go(false); ← (2)
unsigned const loop_count = 10;
struct read_values {
int x, y, z;
};
read_values values1[loop_count];
read_values values2[loop_count];
read_values values3[loop_count];
read_values values4[loop_count];
read_values values5[loop_count];
void increment(
std::atomic* var_to_inc, read_values* values) {
while (!go) ← (3) В цикле ждем сигнала
std::this_thread::yield();
for (unsigned i = 0; i < loop_count; ++i) {
values[i].x = x.load(std::memory_order_relaxed);
values[i].y = y.load(std::memory_order_relaxed);
values[i].z = z.load(std::memory_order_relaxed);
var_to_inc->store(i + 1, std::memory_order_relaxed);← (4)
std::this_thread::yield();
}
}
void read_vals(read_values* values) {
while (!go) ← (5) В цикле ждем сигнала
std::this_thread::yield();
for (unsigned i = 0; i < loop_count; ++i) {
values[i].x = x.load(std::memory_order_relaxed);
values[i].y = y.load(std::memory_order_relaxed);
values[i].z = z.load(std::memory_order_relaxed);
std::this_thread::yield();
}
}
void print(read_values* v) {
for (unsigned i = 0; i < loop_count; ++i) {
if (i)
std::cout << ",";
std::cout <<
"(" << v [i] .x << "," << v[i].y << "," << v[i].z << ")";
}
std::cout << std::endl;
}
int main() {
std::thread t1(increment, &x, values1);
std::thread t2(increment, &y, values2);
std::thread t3(increment, &z, values3);
std::thread t4(read_vals, values4);
std::thread t5(read_vals, values5);
go = true; ←┐ Сигнал к началу выполнения
│ (6) главного цикла
t5.join();
t4.join();
t3.join();
t2.join();
t1.join();
print(values1);←┐
print(values2); │ Печатаем получившиеся
print(values3); (7) значения
print(values4);
print(values5);
}
По существу, это очень простая программа. У нас есть три разделяемых глобальных атомарных переменных (1)и пять потоков. Каждый поток выполняет 10 итераций цикла, читая значения трех атомарных переменных в режиме memory_order_relaxedи сохраняя их в массиве. Три из пяти потоков обновляют одну из атомарных переменных при каждом проходе по циклу (4), а остальные два только читают ее. После присоединения всех потоков мы распечатываем массивы, заполненные каждым из них (7).
Интервал:
Закладка:
Похожие книги на «Параллельное программирование на С++ в действии. Практика разработки многопоточных программ»
Представляем Вашему вниманию похожие книги на «Параллельное программирование на С++ в действии. Практика разработки многопоточных программ» списком для выбора. Мы отобрали схожую по названию и смыслу литературу в надежде предоставить читателям больше вариантов отыскать новые, интересные, ещё непрочитанные произведения.











Обсуждение, отзывы о книге «Параллельное программирование на С++ в действии. Практика разработки многопоточных программ» и просто собственные мнения читателей. Оставьте ваши комментарии, напишите, что Вы думаете о произведении, его смысле или главных героях. Укажите что конкретно понравилось, а что нет, и почему Вы так считаете.