IvanStorogev? KpNemo - Как почистить сканы книг и сделать книгу
Здесь есть возможность читать онлайн «IvanStorogev? KpNemo - Как почистить сканы книг и сделать книгу» весь текст электронной книги совершенно бесплатно (целиком полную версию без сокращений). В некоторых случаях можно слушать аудио, скачать через торрент в формате fb2 и присутствует краткое содержание. Жанр: Программирование, на русском языке. Описание произведения, (предисловие) а так же отзывы посетителей доступны на портале библиотеки ЛибКат.

- Название:Как почистить сканы книг и сделать книгу
- Автор:
- Жанр:
- Год:неизвестен
- ISBN:нет данных
- Рейтинг книги:5 / 5. Голосов: 1
-
Избранное:Добавить в избранное
- Отзывы:
-
Ваша оценка:
Как почистить сканы книг и сделать книгу: краткое содержание, описание и аннотация
Предлагаем к чтению аннотацию, описание, краткое содержание или предисловие (зависит от того, что написал сам автор книги «Как почистить сканы книг и сделать книгу»). Если вы не нашли необходимую информацию о книге — напишите в комментариях, мы постараемся отыскать её.
Как почистить сканы книг и сделать книгу — читать онлайн бесплатно полную книгу (весь текст) целиком
Ниже представлен текст книги, разбитый по страницам. Система сохранения места последней прочитанной страницы, позволяет с удобством читать онлайн бесплатно книгу «Как почистить сканы книг и сделать книгу», без необходимости каждый раз заново искать на чём Вы остановились. Поставьте закладку, и сможете в любой момент перейти на страницу, на которой закончили чтение.
Интервал:
Закладка:
Вернемся к сканам книги. На краях и переплета после сканирования часто бывают черные полосы. Это тоже шум. От полезного сигнала, изображения текста, он отличается расположением в двумерном пространстве изображения страницы, поэтому отделить его легко руками и относительно легко автоматически. Стоит, однако, неплотно прижать толстую книгу при сканировании и черная полоса будет пересекаться с текстом. И всё, выделить текст в этом месте методами обработки изображения станет невозможно. Но если речь идет всего о 1-2 буквах в начале (конце) строки, мозг, почти на 100% восстановит недостающие буквы. Вдь ткст очн избтчн, при удални глснх всё ещ мжно пнть о чм рчь. Однако фильтрация и восстановление будет идти не изображения, а текста как последовательности букв и слов, с учетом их смысла, семантики.
Программа NeatImage, описанная в 1-ой части статьи использует другой критерий различения шума и сигнала – разницу в двумерных спектрах сигнала и шума. Обратите внимание: указывать где шум, а где сигнал нам пришлось самостоятельно. В иных случаях шум и сигнал могут поменяются местами. Например, криминалисту может быть задан вопрос: – "Где взята бумага, на которой написана жуткая записка?". И фактура бумаги была бы полезным сигналом, а изображение текста – шумом. В 3-й части статьи будет описана работа с фильтром Фотошопа Smart Blur. Там используются другие критерии разделения сигнала и шума.
Нужно обязательно понимать, по какому критерию происходит разделение сигнала и шума в используемых вами процедурах фильтрации. Тогда можно будет выработать более эффективный метод обработки.
Ведь если мы по очереди применим несколько фильтров с разными критериями фильтрации, то результат будет хороший. Если же фильтры обрабатывают по одному и тому же критерию, то с какого-то момента, улучшения не будет, а то и начнется ухудшение разделения.
Здесь описана работа с Фотошопом, но подобный инструмент есть в любом достаточно мощном растровом редакторе: Gimp, Corel Photopaint, PaintShop Pro и др. Алгоритмы у всех одинаковы. Важно лишь наличие у редактора режима пакетной обработки.
Итак, инструмент Curves. Что, собственно, мы им сделаем? Это очень просто: разделим шум и полезное изображение по критерию яркости. Всё, что будет белее некоторого порога, станет максимально белым. Соответственно всё, что будет темнее некоторого порога, будет совершенно черным. Все наши усилия будут направленны как раз на установление этих порогов так, чтобы фон попал в белое, а текст – в черное. Имейте ввиду, если после предыдущих этапов обработки на изображении есть участки шума более темные, чем наиболее светлые участки текста, то Curves их не только не удалит, а наоборот – подчеркнет.
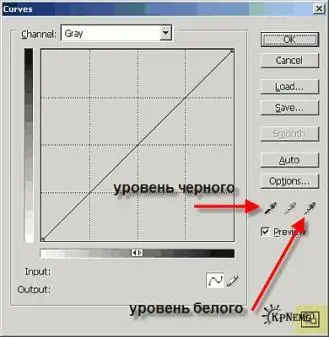
Вызываем Curves (Меню: Image -› Adjustments -› Curves или просто Ctrl-M). На Рис. 1 стрелками указаны две пипетки: "Уровень черного" и "Уровень белого". Орудуя ими по очереди мы и подгоним пороги так, чтобы текст было побольше, а шума поменьше. Серая пипетка нам не нужна. Кнопка в правом нижнем углу (подсвечена желтым) увеличивает окошко или делает его компактным.
Перед вызовом Curves нужно увеличить изображение на весь экран так, чтобы были целиком видны 3-4 буквы. Обязательно должна попасть точка и запятая, буквы с мелкими деталями. Лучше выберите сильно зашумленный участок, там где шум более темный. По возможности выберите участок с мелким шрифтом, например текст сноски внизу страницы.
Теперь по очереди, чередую пипетки, щелкайте на белой – на участках с шумом, черной – на полезных участках картинки, на буквах.
Когда будет работать пипетками, контролируйте следующие критерии, они выбраны с учетом характерных ошибок FineReader'а:
– точка "." и запятая "," должны отличаться;
– белый участок внутри букв "е", "о", "R" и т.п не должен быть залит черным;
– мелкие детали букв должны быть различимы, например хвостик у курсивной " а ", она не должна превращатся в " о ";
– следите за "коромыслом" у буквы "й", точкой над "i" и другими подобными элементами букв;
– обратите внимание на верхние (и нижние) индексы, например значки и цифры, указывающие на сноску;
– мелкие разрывы в вертикальных участках широких букв – "м", "ш" – не страшны;
– в горизонтальных/наклонных участках букв "н", "и", "п" разрывов быть не должно. FR немедленно начинает их путать;
Читать дальшеИнтервал:
Закладка:
Похожие книги на «Как почистить сканы книг и сделать книгу»
Представляем Вашему вниманию похожие книги на «Как почистить сканы книг и сделать книгу» списком для выбора. Мы отобрали схожую по названию и смыслу литературу в надежде предоставить читателям больше вариантов отыскать новые, интересные, ещё непрочитанные произведения.











Обсуждение, отзывы о книге «Как почистить сканы книг и сделать книгу» и просто собственные мнения читателей. Оставьте ваши комментарии, напишите, что Вы думаете о произведении, его смысле или главных героях. Укажите что конкретно понравилось, а что нет, и почему Вы так считаете.