IvanStorogev? KpNemo - Как почистить сканы книг и сделать книгу
Здесь есть возможность читать онлайн «IvanStorogev? KpNemo - Как почистить сканы книг и сделать книгу» весь текст электронной книги совершенно бесплатно (целиком полную версию без сокращений). В некоторых случаях можно слушать аудио, скачать через торрент в формате fb2 и присутствует краткое содержание. Жанр: Программирование, на русском языке. Описание произведения, (предисловие) а так же отзывы посетителей доступны на портале библиотеки ЛибКат.

- Название:Как почистить сканы книг и сделать книгу
- Автор:
- Жанр:
- Год:неизвестен
- ISBN:нет данных
- Рейтинг книги:5 / 5. Голосов: 1
-
Избранное:Добавить в избранное
- Отзывы:
-
Ваша оценка:
Как почистить сканы книг и сделать книгу: краткое содержание, описание и аннотация
Предлагаем к чтению аннотацию, описание, краткое содержание или предисловие (зависит от того, что написал сам автор книги «Как почистить сканы книг и сделать книгу»). Если вы не нашли необходимую информацию о книге — напишите в комментариях, мы постараемся отыскать её.
Как почистить сканы книг и сделать книгу — читать онлайн бесплатно полную книгу (весь текст) целиком
Ниже представлен текст книги, разбитый по страницам. Система сохранения места последней прочитанной страницы, позволяет с удобством читать онлайн бесплатно книгу «Как почистить сканы книг и сделать книгу», без необходимости каждый раз заново искать на чём Вы остановились. Поставьте закладку, и сможете в любой момент перейти на страницу, на которой закончили чтение.
Интервал:
Закладка:
Растровая форма хранения книг особенно часто применяется для книг с формулами. В этом случае сканирование с разрешением 600dpi обязательно, иначе трудно будет разобрать индексы в формулах, отличить похожие буквы, например "омега" и w . А ведь в математике нередки вложенные индексы (индекс индекса). Там при сканировании с разрешением 300dpi вообще трудно что-либо разобрать, тем более распечатать. Вот смотрите:
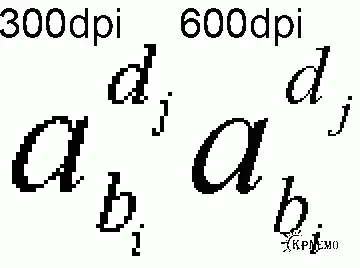
Буквы i и j на картинке слева трудно отличить друг от друга. А ведь это не скан, а печать в файл. При сканировании всё будет гораздо хуже – маленькая точка на бумаге и всё, и 2 балла на экзамене!
Таким образом:
Сканировать для наших целей нужно с разрешением 600dpi!
В крайнем случае, 400dpi.
Теперь нужно выбрать образцовую страницу для настройки программ обработки, чтобы остальные обработать автоматически, в пакетном режиме. Выберите самую обычную, типовую страницу, может быть слегка более грязную, чем в среднем.
Посмотрите все отсканенные страницы книги, может быть некоторые нужно пересканить.
Все сильно загрязненные, искаженные, с более мелким шрифтом, чем остальные, с очень крупными пятнами, с рисунками на всю или почти всю страницу и т.п. сразу положите в отдельную папку. Их проще обработать отдельно, по одной. Обычно таких немного.
Дальше приступим к обработке сканов последовательно в программе NeatImagePro+, потом в PhotoShop’е. Начнем с первой.
Нам понадобится программа NeatImagePro+ (NI+), у неё множество уникальных возможностей, например с её помощью можно делать замечательные "гламурные" картинки обнаженной натуры. Вот её сайт: neatimage.com. Но нам туда не надо, там её свободно не раздают. К счастью, у Вас есть я, а у нас всех Рапидшара:
Neat Image Pro+ Edition v5.0.5.0
пароль:))))))
Это не самая последняя версия, зато с лекарством и вполне рабочая.
NI+ работает следующим образом: выделяется характерный участок картинки с шумом, но без полезного изображения. Программа этот участок оценивает и "вычитает" шум из всей картинки.
Я закавычил "вычитает" потому, что на самом деле не "вычитает", а умножает, и не картинку на шум, а их двухмерные спектральные представления. Да и не умножает, если в школьном смысле… Но мы в эти дебри не полезем:-).
Главное окно программы организовано в виде вкладок:
1) Вкладка: Input Image
Про то, как загрузить файл в программу, я рассказывать не буду, замечу лишь, что NI+ не желает открывать 8-битный TIFF, если он сохранен, например из PhotoShop’а как индексированный 8-битный с палитрой, но нормально открывает, если TIFF сохранить как grayscale.
2) Вкладка: Device Noise Profile
На этом этапе мы должны выбрать участок скана, где нет букв и рисунков, но есть характерные шумы. Обратите внимание: темные полосы около корешка или на краях тоже не должны попасть в наш выбор. На выделенный участок показывает стрелка на Рис. 1:
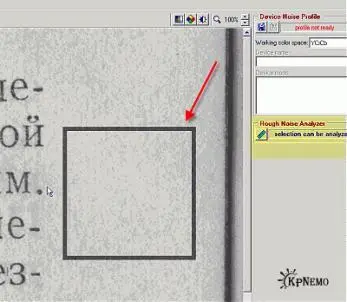
После того, как мы выделим подходящий участок, надо щелкнуть по кнопке "Rough NoiseAnalyzer" на левой панели, на Рис.1 подсвечена желтым. Некоторое время наблюдаем за синей полоской… и на левой панели, под упомянутой кнопкой, появятся дополнительные настройки (Рис. 2).
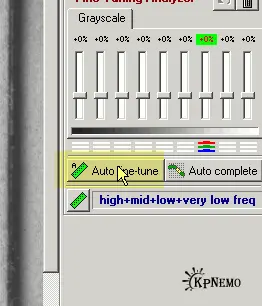
Проще всего нажать на кнопочку "Auto fine-tune" (подсвечена желтым), и перейти к вкладке 3:
3) Вкладка: Noise Filter Settings
Здесь мы настроим фильтр так, чтобы сделать максимально четкими буквы и убить шумы. Перед настройкой фильтра нужно выделить участок подходящий участок с полезнымизображением и увеличить его на весь экран. При выборе участка нужно руководствоваться следующими соображениями:
1) Брать нужно, по возможности, максимально зашумленный участок;
2) Одновременно этот участок должен с наиболее мелким деталями полезного изображения, например с мелким шрифтом.
Поскольку мы обрабатываем не фотографию любимой кошки, а текст, то естественность изображения нас не волнует. Главное, чтобы буквы были почетче, а шума поменьше. Поэтому смело двигаем движки на левой половине панели и смотрим, что получается. Обращайте внимание на мелкие детали букв: хвостики, например сравнивайте "C" и "G"; внутренние участки букв, например в верхней части строчной "е".
Читать дальшеИнтервал:
Закладка:
Похожие книги на «Как почистить сканы книг и сделать книгу»
Представляем Вашему вниманию похожие книги на «Как почистить сканы книг и сделать книгу» списком для выбора. Мы отобрали схожую по названию и смыслу литературу в надежде предоставить читателям больше вариантов отыскать новые, интересные, ещё непрочитанные произведения.











Обсуждение, отзывы о книге «Как почистить сканы книг и сделать книгу» и просто собственные мнения читателей. Оставьте ваши комментарии, напишите, что Вы думаете о произведении, его смысле или главных героях. Укажите что конкретно понравилось, а что нет, и почему Вы так считаете.