Иван Братко - Программирование на языке Пролог для искусственного интеллекта
Здесь есть возможность читать онлайн «Иван Братко - Программирование на языке Пролог для искусственного интеллекта» весь текст электронной книги совершенно бесплатно (целиком полную версию без сокращений). В некоторых случаях можно слушать аудио, скачать через торрент в формате fb2 и присутствует краткое содержание. Город: Москва, Год выпуска: 1990, ISBN: 1990, Издательство: Мир, Жанр: Программирование, на русском языке. Описание произведения, (предисловие) а так же отзывы посетителей доступны на портале библиотеки ЛибКат.

- Название:Программирование на языке Пролог для искусственного интеллекта
- Автор:
- Издательство:Мир
- Жанр:
- Год:1990
- Город:Москва
- ISBN:5-03-001425-Х
- Рейтинг книги:2.5 / 5. Голосов: 2
-
Избранное:Добавить в избранное
- Отзывы:
-
Ваша оценка:
Программирование на языке Пролог для искусственного интеллекта: краткое содержание, описание и аннотация
Предлагаем к чтению аннотацию, описание, краткое содержание или предисловие (зависит от того, что написал сам автор книги «Программирование на языке Пролог для искусственного интеллекта»). Если вы не нашли необходимую информацию о книге — напишите в комментариях, мы постараемся отыскать её.
Для программистов разной квалификации, специалистов по искусственному интеллекту, для всех изучающих программирование.
Программирование на языке Пролог для искусственного интеллекта — читать онлайн бесплатно полную книгу (весь текст) целиком
Ниже представлен текст книги, разбитый по страницам. Система сохранения места последней прочитанной страницы, позволяет с удобством читать онлайн бесплатно книгу «Программирование на языке Пролог для искусственного интеллекта», без необходимости каждый раз заново искать на чём Вы остановились. Поставьте закладку, и сможете в любой момент перейти на страницу, на которой закончили чтение.
Интервал:
Закладка:
Мы говорим, что дерево (приближенно) сбалансировано, если для каждой вершины дерева соответствующие два поддерева содержат примерно равное число элементов. Если дерево хорошо сбалансировано, то его глубина пропорциональна log n . В этом случае мы говорим, что дерево имеет логарифмическую сложность. Сбалансированный справочник лучше списка настолько же, насколько log n меньше n . К сожалению, это верно только для приближенно сбалансированного дерева. Если происходит разбалансировка дерева, то производительность падает. В случае полностью разбалансированных деревьев, дерево фактически превращается в список. Глубина дерева в этом случае равна n , а производительность поиска оказывается столь же низкой, как и в случае списка. В связи с этим мы всегда заинтересованы в том, чтобы справочники были сбалансированы. Методы достижения этой цели мы обсудим в гл. 10.
9.9. Определите предикаты
двдерево( Объект)
справочник( Объект)
распознающие, является ли Объектдвоичным деревом или двоичным справочником соответственно. Используйте обозначения, введенные в данном разделе.
9.10. Определите процедуру
глубина( ДвДерево, Глубина)
вычисляющую глубину двоичного дерева в предположении, что глубина пустого дерева равна 0, а глубина одноэлементного дерева равна 1.
9.11. Определите отношение
линеаризация( Дерево, Список)
соответствующее "выстраиванию" всех вершин дерева в список.
9.12. Определите отношение
максэлемент( Д, Элемент)
таким образом, чтобы переменная Элементприняла значение наибольшего из элементов, хранящихся в дереве Д.
9.13. Внесите изменения в процедуру
внутри( Элемент, ДвСправочник)
добавив в нее третий аргумент Путьтаким образом, чтобы можно было бы получить путь между корнем справочника и указанным элементом.
9.3. Двоичные справочники: добавление и удаление элемента
Если мы имеем дело с динамически изменяемым множеством элементов данных, то нам может понадобиться внести в него новый элемент или удалить из него один из старых. В связи с этим набор основных операций, выполняемых над множеством S, таков:
внутри( X, S) % X содержится в S
добавить( S, X, S1) % Добавить X к S, результат - S1
удалить( S, X, S1) % Удалить X из S, результат - S1
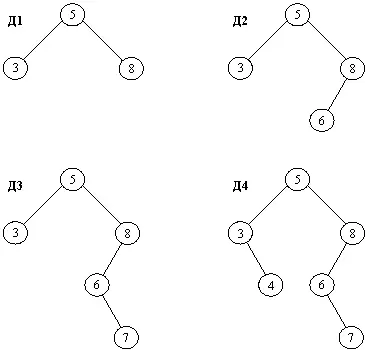
Рис. 9.9. Введение в двоичный справочник нового элемента на уровне листьев. Показанные деревья соответствуют следующей последовательности вставок: добавить( Д1, 6, Д2) , добавить( Д2, 6, Д3) , добавить( Д3, 6, Д4)
доблист( nil, X, дер( nil, X, nil) ).
доблист( дер( Лев, X, Прав), X, дер( Лев, X, Прав) ).
доблист( дер( Лев, Кор, Прав), X, дер( Лев1, Кор, Прав)) :-
больше( Кор, X),
доблист( Лев, X, Лев1)).
доблист( дер( Лев, Кор, Прав), X, дер( Лев, Кор, Прав1)) :-
больше( X, Кор),
доблист( Прав, X, Прав1).
Рис. 9.10. Вставление в двоичный справочник нового элемента в качестве листа.
Определим отношение добавить . Простейший способ: ввести новый элемент на самый нижний уровень дерева, так что он станет его листом. Место, на которое помещается новый элемент, выбрать таким образом, чтобы не нарушить упорядоченность дерева. На рис. 9.9 показано, какие изменения претерпевает дерево в процессе введения в него новых элементов. Назовем такой метод вставления элемента в множество
доблист( Д, X, Д1)
Правила добавления элемента на уровне листьев таковы:
• Результат добавления элемента X к пустому дереву есть дерево дер( nil, X, nil).
• Если X совпадает с корнем дерева Д, то Д1 = Д (в множестве не допускается дублирования элементов).
• Если корень дерева Д больше, чем X, то X вносится в левое поддерево дерева Д; если корень меньше, чем X, то X вносится в правое поддерево.
На рис. 9.10 показана соответствующая программа.
Теперь рассмотрим операцию удалить . Лист дерева удалить легко, однако удалить какую-либо внутреннюю вершину — дело не простое. Удаление листа можно на самом деле определить как операцию, обратную операции добавления листа:
удлист( Д1, X, Д2) :-
доблист( Д2, X, Д1).
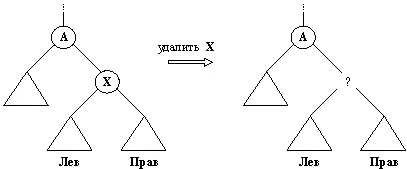
Рис. 9.11. Удаление X из двоичного справочника. Возникает проблема наложения "заплаты" на место удаленного элемента X.
Читать дальшеИнтервал:
Закладка:
Похожие книги на «Программирование на языке Пролог для искусственного интеллекта»
Представляем Вашему вниманию похожие книги на «Программирование на языке Пролог для искусственного интеллекта» списком для выбора. Мы отобрали схожую по названию и смыслу литературу в надежде предоставить читателям больше вариантов отыскать новые, интересные, ещё непрочитанные произведения.












Обсуждение, отзывы о книге «Программирование на языке Пролог для искусственного интеллекта» и просто собственные мнения читателей. Оставьте ваши комментарии, напишите, что Вы думаете о произведении, его смысле или главных героях. Укажите что конкретно понравилось, а что нет, и почему Вы так считаете.