Д. Стефенс - C++. Сборник рецептов
Здесь есть возможность читать онлайн «Д. Стефенс - C++. Сборник рецептов» весь текст электронной книги совершенно бесплатно (целиком полную версию без сокращений). В некоторых случаях можно слушать аудио, скачать через торрент в формате fb2 и присутствует краткое содержание. Город: Москва, Год выпуска: 2007, ISBN: 2007, Издательство: КУДИЦ-ПРЕСС, Жанр: Программирование, на русском языке. Описание произведения, (предисловие) а так же отзывы посетителей доступны на портале библиотеки ЛибКат.

- Название:C++. Сборник рецептов
- Автор:
- Издательство:КУДИЦ-ПРЕСС
- Жанр:
- Год:2007
- Город:Москва
- ISBN:5-91136-030-6
- Рейтинг книги:4 / 5. Голосов: 1
-
Избранное:Добавить в избранное
- Отзывы:
-
Ваша оценка:
C++. Сборник рецептов: краткое содержание, описание и аннотация
Предлагаем к чтению аннотацию, описание, краткое содержание или предисловие (зависит от того, что написал сам автор книги «C++. Сборник рецептов»). Если вы не нашли необходимую информацию о книге — напишите в комментариях, мы постараемся отыскать её.
C++. Сборник рецептов — читать онлайн бесплатно полную книгу (весь текст) целиком
Ниже представлен текст книги, разбитый по страницам. Система сохранения места последней прочитанной страницы, позволяет с удобством читать онлайн бесплатно книгу «C++. Сборник рецептов», без необходимости каждый раз заново искать на чём Вы остановились. Поставьте закладку, и сможете в любой момент перейти на страницу, на которой закончили чтение.
Интервал:
Закладка:
Поймите, как реализован vector, узнайте о сложности методов вставки и удаления и минимизируйте ненужные операции с памятью с помощью метода reserve. Пример 6.2 показывает некоторые из этих методик в действии.
Пример 6.2. Эффективное использование vector
#include
#include
#include
using std::vector;
using std::string;
void f(vector& vec) {
// Передача vec по ссылке (или,
// если требуется, через указатель)
// ...
}
int main() {
vector vec(500); // При создании vector говорим, что в него
// планируется поместить определенное количество
// объектов
vector vec2;
// Заполняем vec...
f(vec);
vec2 reserve(500); // Или постфактум говорим vector,
// что требуется буфер достаточно большого
// размера для хранения объектов
// Заполняем vec2...
}
Ключ к эффективному использованию vectorлежит в знании его работы. Когда у вас есть четкое представление реализации vector, вопросы производительности становятся очевидными.
vector— это по сути управляемый массив. Более конкретно, vector— это непрерывный фрагмент памяти (т.е. массив), который достаточно велик для хранения n объектов типа T, где n больше или равно нулю и меньше или равно зависящему от реализации максимальному размеру. Обычно n увеличивается в процессе жизни контейнера при добавлении или удалении элементов, но оно никогда не уменьшается. Что отличает vectorот массива — это автоматическое управление памятью массива, методы для вставки и получения элементов и методы, которые предоставляют метаданные о контейнере, такие как размер (число элементов) и емкость (размер буфера), а также информацию о типе: vector::value_type— это тип T, vector::pointer— это тип указатель-на- Tи т.д. Два последних и некоторые другие являются частью любого стандартного контейнера, и они позволяют писать обобщенный код, который работает независимо от типа T. Рисунок 6.1 показывает графическое представление того, что предоставляют некоторые из методов vector, если vectorимеет размер 7 и емкость 10.
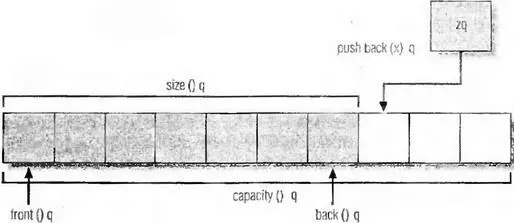
Рис. 6.1. Внутренности vector
Если вам любопытно, как поставщик вашей стандартной библиотеки реализовал vector, скомпилируйте пример 6.1 и пройдите в отладчике все вызовы методов vector или откройте заголовочный файл реализации стандартной библиотеки и изучите его. Код, который вы там увидите, по большей части не является дружественным к читателю, но он должен осветить некоторые моменты. Во-первых, если вы еще не видели кода библиотеки, он даст вам представление о методиках реализации, используемых для написания эффективного, переносимого обобщенного кода. Во-вторых, он даст точное представление о том, что представляют собой используемые вами контейнеры. При написании кода, который должен работать с различными реализациями стандартной библиотеки, это следует сделать в любом случае.
Однако независимо от поставщика библиотеки почти все реализации векторов похожи. В них есть переменная экземпляра, которая указывает на массив из T, и элементы, добавляемые или присваиваемые вами, с помощью конструктора копирования или операции присвоения помешаются в элементы этого массива.
Обычно добавление объекта Tв следующий доступный слот буфера выполняется с помощью копирующего конструктора и new, которому передается тип создаваемого объекта, а также адрес, по которому он должен быть создан. Если вместо этого явно присвоить значение слоту, используя его индекс (с помощью operator[]или at), то будет использован оператор присвоения T. Заметьте, что в обоих случаях объект клонируется либо с помощью конструктора копирования, либо T::operator=. vectorне просто хранит адрес добавляемого объекта. Именно по этой причине любой тип, сохраняемый в векторе, должен поддерживать копирующий конструктор и присвоение. Эти свойства означают, что эквивалентный объект типа Tможет быть создан с помощью вызова конструктора копирования Tили оператора присвоения. Это очень важно из-за семантики копирования vector— если конструктор копирования или присвоение объектов не работает, то результаты, получаемые из vector, могут отличаться от того, что в него помещалось. А это плохо.
Интервал:
Закладка:
Похожие книги на «C++. Сборник рецептов»
Представляем Вашему вниманию похожие книги на «C++. Сборник рецептов» списком для выбора. Мы отобрали схожую по названию и смыслу литературу в надежде предоставить читателям больше вариантов отыскать новые, интересные, ещё непрочитанные произведения.












Обсуждение, отзывы о книге «C++. Сборник рецептов» и просто собственные мнения читателей. Оставьте ваши комментарии, напишите, что Вы думаете о произведении, его смысле или главных героях. Укажите что конкретно понравилось, а что нет, и почему Вы так считаете.