Олег Цилюрик - QNX/UNIX - Анатомия параллелизма
Здесь есть возможность читать онлайн «Олег Цилюрик - QNX/UNIX - Анатомия параллелизма» — ознакомительный отрывок электронной книги совершенно бесплатно, а после прочтения отрывка купить полную версию. В некоторых случаях можно слушать аудио, скачать через торрент в формате fb2 и присутствует краткое содержание. Город: Санкт-Петербург, Год выпуска: 2006, ISBN: 2006, Издательство: Символ-Плюс, Жанр: Программирование, ОС и Сети, на русском языке. Описание произведения, (предисловие) а так же отзывы посетителей доступны на портале библиотеки ЛибКат.

- Название:QNX/UNIX: Анатомия параллелизма
- Автор:
- Издательство:Символ-Плюс
- Жанр:
- Год:2006
- Город:Санкт-Петербург
- ISBN:5-93286-088-Х
- Рейтинг книги:4 / 5. Голосов: 1
-
Избранное:Добавить в избранное
- Отзывы:
-
Ваша оценка:
QNX/UNIX: Анатомия параллелизма: краткое содержание, описание и аннотация
Предлагаем к чтению аннотацию, описание, краткое содержание или предисловие (зависит от того, что написал сам автор книги «QNX/UNIX: Анатомия параллелизма»). Если вы не нашли необходимую информацию о книге — напишите в комментариях, мы постараемся отыскать её.
В качестве «испытательной площадки» для тестовых фрагментов выбрана ОСРВ QNX, что позволило с единой точки зрения взглянуть как на специфические механизмы микроядерной архитектуры QNX, так и на универсальные механизмы POSIX. В этом качестве книга может быть интересна и тем, кто не использует (и не планирует никогда использовать) ОС QNX: программистам в Linux, FreeBSD, NetBSD, Solaris и других традиционных ОС UNIX.
QNX/UNIX: Анатомия параллелизма — читать онлайн ознакомительный отрывок
Ниже представлен текст книги, разбитый по страницам. Система сохранения места последней прочитанной страницы, позволяет с удобством читать онлайн бесплатно книгу «QNX/UNIX: Анатомия параллелизма», без необходимости каждый раз заново искать на чём Вы остановились. Поставьте закладку, и сможете в любой момент перейти на страницу, на которой закончили чтение.
Интервал:
Закладка:
На этот раз за счет уменьшения периода системного тика на 2 порядка на протяжении «работы» (того же объема полезной работы!) было уже 7937,35/0,009219 = 860977 событий диспетчеризации.
Поскольку объем работы программы, выполняемый в этих двух случаях, остается неизменным, то на обслуживание дополнительных 860 977 – 5929 = 855 048 системных тиков (совместно с 855 048/4 = 213 762 точками диспетчеризации) и потребовались те 4 243 731 124 – 3 169 850 746 = 1 073 880 378 дополнительных тактов процессора, или около 1256 тактов на один системный тик. Ранее мы уже получали оценки затрат собственно на переключение контекстов между процессами (617) и потоками (374), которые происходят каждый четвертый системный тик, то есть непосредственно переключение контекста «отъедает» в среднем 90–150 (¼ часть затрат переключения контекста) на каждый системный тик или, другими словами, не более 10% затрат на обслуживание службы системных часов.
Попытаемся осмыслить полученные результаты:
• Время переключения адресных пространств процессов, управляемых MMU аппаратно, в принципе должно быть продолжительнее времени переключения контекстов потоков и тем более восстановления контекста единого последовательного потока, но…
• …но объем работы по обслуживанию каждого системного тика (прерывания таймера) настолько превышает объем операций переключения контекстов (рис. 2.7), что это практически полностью нивелирует разницу, будь то приложение в виде многих автономных процессов, многопоточное приложение или приложение в виде единого последовательного потока.
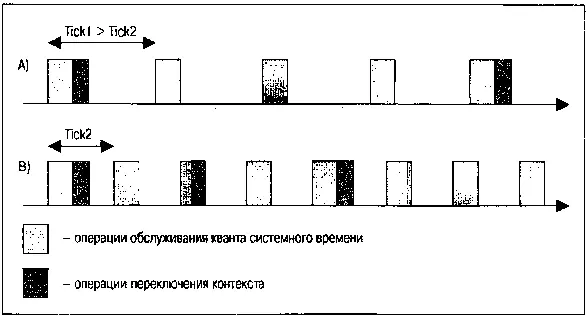
Рис. 2.7. Эффекты, возникающие при принудительном изменении частоты системных часов
На рис. 2.7 показана последовательность тиков системных часов и связанная с нею последовательность актов диспетчеризации. При уменьшении периода наступления системных тиков (частоты аппаратных прерываний от системных часов) в силу фиксированных объемов операций, требуемых как для одних, так и для других действий, относительная доля времени, остающаяся для выполнения полезной работы, падает.
• И это будет выполняться не только для потоков, диспетчеризуемых с дисциплиной RR (вытесняемых по истечении бюджета времени выделенного им кванта), но и для потоков с любойдисциплиной диспетчеризации, в том числе и FIFO, когда выполняющийся поток (а значит, поток наивысшего приоритета в системе) вообще «не собирается» никому передавать управление.
• Для программиста-разработчика результаты этого теста позволяют сформулировать правило, возможно абсурдное с позиций элементарной (но поверхностной) логики: Распараллеливание задачи (если это возможно) на N ветвей (будь то использование потоков или процессов) практически не изменяет итоговое время ее выполнения.
Еще одним побочным результатом рассмотрения можно назвать следующее: эффективность диспетчеризации потоков (сохранения и переключения контекстов), принадлежащих одному процессу, ни в чем не превосходит эффективность диспетчеризации группы потоков, принадлежащих различным процессам. И в этом своем качестве — эффективности периода выполнения — потоки в своей «легковесности» ничем не превосходят автономные параллельные процессы. [25] Мы умышленно делаем акцент на этом месте, так как существует «красивая народная легенда» (и это утверждение встречается порой и в литературе), что потоки на периоде выполнения намного эффективнее (в смысле переключения контекста), чем процессы.
В завершение воспользуемся все теми же тестовыми приложениями для ответа на часто задаваемый вопрос: «Насколько эффективно ОС QNX поддерживает приложения, содержащие большое («слишком большое») количество потоков? Посмотрим, как это выглядит. Все выполнения мы делаем при минимально возможном значении системного тика, когда ОС существенно более «озабочена» своими внутренними процессами, нежели процессом вычислений:
# nice -n-19 p4-2 2 10
Rescheduling interval = 0.036876 msec.
Threads scheduling time: 1555.43 msec [831574415 cycles]
# nice -n-19 p4-2 20 10
Rescheduling interval = 0.036876 msec.
Threads scheduling time: 15642 msec. [8362674590 cycles]
# nice -n-19 p4-2 200 10
Rescheduling interval = 0.036876 msec
Threads scheduling time: 161112 msec. [86134950020 cycles]
Наблюдается очень хорошая линейная зависимость итогового времени от числа потоков (от 2 до 200). Таким образом, время выполнения работы в каждом из потоков практически не зависит от общего числа параллельно выполняющихся с ним потоков.
Читать дальшеИнтервал:
Закладка:
Похожие книги на «QNX/UNIX: Анатомия параллелизма»
Представляем Вашему вниманию похожие книги на «QNX/UNIX: Анатомия параллелизма» списком для выбора. Мы отобрали схожую по названию и смыслу литературу в надежде предоставить читателям больше вариантов отыскать новые, интересные, ещё непрочитанные произведения.










Обсуждение, отзывы о книге «QNX/UNIX: Анатомия параллелизма» и просто собственные мнения читателей. Оставьте ваши комментарии, напишите, что Вы думаете о произведении, его смысле или главных героях. Укажите что конкретно понравилось, а что нет, и почему Вы так считаете.