Джин Ким - Руководство по DevOps
Здесь есть возможность читать онлайн «Джин Ким - Руководство по DevOps» весь текст электронной книги совершенно бесплатно (целиком полную версию без сокращений). В некоторых случаях можно слушать аудио, скачать через торрент в формате fb2 и присутствует краткое содержание. Город: Москва, Год выпуска: 2018, ISBN: 2018, Издательство: Манн, Иванов и Фербер, Жанр: Интернет, Базы данных, Прочая околокомпьтерная литература, на русском языке. Описание произведения, (предисловие) а так же отзывы посетителей доступны на портале библиотеки ЛибКат.

- Название:Руководство по DevOps
- Автор:
- Издательство:Манн, Иванов и Фербер
- Жанр:
- Год:2018
- Город:Москва
- ISBN:9785001007500
- Рейтинг книги:4 / 5. Голосов: 1
-
Избранное:Добавить в избранное
- Отзывы:
-
Ваша оценка:
Руководство по DevOps: краткое содержание, описание и аннотация
Предлагаем к чтению аннотацию, описание, краткое содержание или предисловие (зависит от того, что написал сам автор книги «Руководство по DevOps»). Если вы не нашли необходимую информацию о книге — напишите в комментариях, мы постараемся отыскать её.
Руководство по DevOps — читать онлайн бесплатно полную книгу (весь текст) целиком
Ниже представлен текст книги, разбитый по страницам. Система сохранения места последней прочитанной страницы, позволяет с удобством читать онлайн бесплатно книгу «Руководство по DevOps», без необходимости каждый раз заново искать на чём Вы остановились. Поставьте закладку, и сможете в любой момент перейти на страницу, на которой закончили чтение.
Интервал:
Закладка:
Как пошутил один из инженеров Etsy Йен Малпасс, «если в Etsy и есть религия, то это церковь графиков. Если что-то меняется, мы это отслеживаем. Иногда мы рисуем график того, что еще не меняется, на тот случай, если оно вдруг решит пуститься во все тяжкие… Отслеживание всего, что только можно, — ключ к быстрому продвижению вперед, но единственный способ воплотить этот принцип в жизнь — сделать так, чтобы отслеживание показателей было простым… Мы облегчаем сотрудникам задачу наблюдения за нужными им показателями сразу же, без поглощающих время изменений конфигурации или других сложных процессов».
Одним из открытий доклада 2015 State of DevOps Report было то, что в успешных организациях проблемы в процессе создания программного продукта решались в 168 раз быстрее, чем в других фирмах, причем у ведущих организаций медианное значение MTTR [106]измерялось в минутах, тогда как медианный показатель MTTR фирм с низкими показателями измерялся в днях. Две самые важные методики, позволившие минимизировать MTTR, заключались в использовании контроля версий IT-эксплуатацией и применении телеметрии и проактивного мониторинга рабочей среды.
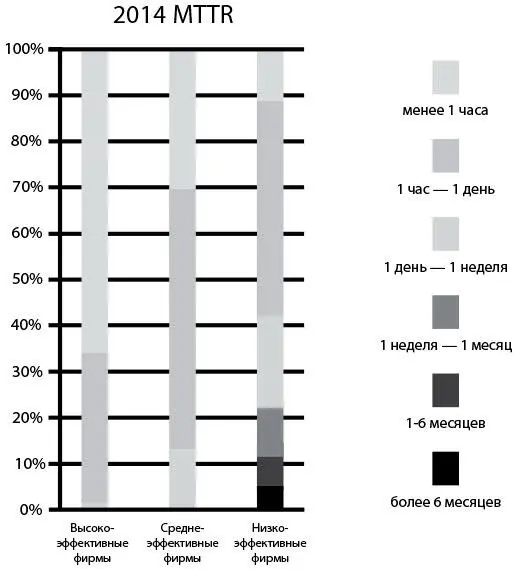
Рис. 25. Время устранения проблемы для высокоэффективных, среднеэффективных и низкоэффективных организаций (источник: отчет 2014 State of DevOps Report компании Puppet Labs)
Наша цель в этой главе — вслед за Etsy построить такую систему телеметрии, чтобы мы всегда были уверены, что наши процессы в производстве протекают так, как нужно. И когда проблемы все-таки случаются, мы можем быстро определить, что пошло не так, и принять обоснованные решения, как лучше всего их разрешить, в идеале — задолго до того, как они повлияют на наших клиентов. Более того, телеметрия как раз и становится средством, позволяющим составить правильное представление о реальности и обнаружить места, где наше понимание расходится с истинным положением дел.
Эксплуатационный мониторинг и логирование — процедуры далеко не новые; многие поколения инженеров эксплуатации использовали и настраивали под себя разные платформы мониторинга (например, HP OpenView, IBM Tivoli, BMC Patrol/BladeLogic), чтобы обеспечить работоспособность производственных систем. Данные обычно собирались с помощью работающих на серверах агентов или с помощью мониторинга без агентов (например, SNMP-ловушки или наблюдение с помощью опросов). Часто для front-end был специальный графический интерфейс (GUI), а отчеты для back-end делались подробнее с помощью таких инструментов, как Crystal Reports.
Точно так же методики разработки приложений с помощью эффективного логирования и использования результатов телеметрии не есть нечто новое: практически для любого языка программирования существует множество разнообразных проработанных библиотек для логирования.
Однако в течение долгих десятилетий все, что у нас было — лишь разрозненные данные, логи созданные разработчиками, интересные только разработчикам, в эксплуатации же следят только за тем, работает ли среда или нет. В результате, когда происходит сбой, никто не может определить, почему вся система работает не так, как должна, или почему конкретный компонент выходит из строя. В результате, когда происходит сбой, никто не может определить, почему вся система работает не так, как должна, или почему конкретный компонент выходит из строя. Все это сильно осложняет попытки вернуть систему в рабочее состояние.
Чтобы отслеживать проблемы в момент возникновения, необходимо так спроектировать и организовать приложения и среду, чтобы они предоставляли телеметрию, позволяющую понять, как работает система в целом. Когда на всех уровнях стека приложения есть мониторинг и логирование, можно применять другие важные инструменты, например создание графиков и визуализацию показателей, обнаружение аномалий, проактивное оповещение и распространение информации и так далее.
В книге The Art of Monitoring Джеймс Торнбулл описал современную архитектуру мониторинга, разработанную и используемую инженерами эксплуатации в масштабных интернет-компаниях (например, Google, Amazon, Facebook). Эта архитектура часто состояла из инструментов с открытым исходным кодом (например, Nagios и Zenoss), измененных под заказчика и использованных в огромных масштабах: этого сложно было бы достичь с помощью лицензированных коммерческих программ того времени. Архитектура состоит из следующих компонентов.
Читать дальшеИнтервал:
Закладка:
Похожие книги на «Руководство по DevOps»
Представляем Вашему вниманию похожие книги на «Руководство по DevOps» списком для выбора. Мы отобрали схожую по названию и смыслу литературу в надежде предоставить читателям больше вариантов отыскать новые, интересные, ещё непрочитанные произведения.












Обсуждение, отзывы о книге «Руководство по DevOps» и просто собственные мнения читателей. Оставьте ваши комментарии, напишите, что Вы думаете о произведении, его смысле или главных героях. Укажите что конкретно понравилось, а что нет, и почему Вы так считаете.