Джин Ким - Руководство по DevOps
Здесь есть возможность читать онлайн «Джин Ким - Руководство по DevOps» весь текст электронной книги совершенно бесплатно (целиком полную версию без сокращений). В некоторых случаях можно слушать аудио, скачать через торрент в формате fb2 и присутствует краткое содержание. Город: Москва, Год выпуска: 2018, ISBN: 2018, Издательство: Манн, Иванов и Фербер, Жанр: Интернет, Базы данных, Прочая околокомпьтерная литература, на русском языке. Описание произведения, (предисловие) а так же отзывы посетителей доступны на портале библиотеки ЛибКат.

- Название:Руководство по DevOps
- Автор:
- Издательство:Манн, Иванов и Фербер
- Жанр:
- Год:2018
- Город:Москва
- ISBN:9785001007500
- Рейтинг книги:4 / 5. Голосов: 1
-
Избранное:Добавить в избранное
- Отзывы:
-
Ваша оценка:
Руководство по DevOps: краткое содержание, описание и аннотация
Предлагаем к чтению аннотацию, описание, краткое содержание или предисловие (зависит от того, что написал сам автор книги «Руководство по DevOps»). Если вы не нашли необходимую информацию о книге — напишите в комментариях, мы постараемся отыскать её.
Руководство по DevOps — читать онлайн бесплатно полную книгу (весь текст) целиком
Ниже представлен текст книги, разбитый по страницам. Система сохранения места последней прочитанной страницы, позволяет с удобством читать онлайн бесплатно книгу «Руководство по DevOps», без необходимости каждый раз заново искать на чём Вы остановились. Поставьте закладку, и сможете в любой момент перейти на страницу, на которой закончили чтение.
Интервал:
Закладка:
• Сбор данных на уровнях бизнес-логики, приложения и среды.На каждом из этих уровней мы создаем телеметрию в виде событий, логов и показателей. Логи могут храниться в специфичных для приложения файлах на каждом сервере (например, /var/log/httpd-error.log), но будет лучше, если все логи будут отсылаться в одно и то же место, что упростит централизацию, ротацию и удаление. Такая услуга обеспечивается большинством операционных систем, например syslog для Linux, Event Log («Журнал событий») для Windows и так далее. Кроме того, мы собираем показатели на всех уровнях стека приложения, чтобы лучше понять, как ведет себя наша система. На уровне операционной системы можно собрать телеметрию работы центрального процессора, памяти, диска или использования сети с помощью таких инструментов, как collectd, Ganglia и так далее. Среди других собирающих данные инструментов можно назвать AppDynamics, New Relic и Pingdom.
• Маршрутизатор событий, ответственный за хранение событий и показателей.Этот компонент отвечает за визуализацию, отслеживание трендов, оповещение, обнаружение аномалий и многое другое. Собирая, храня и агрегируя нашу телеметрию, мы упрощаем последующий анализ и проверки работоспособности. Здесь же мы храним конфигурации, связанные с нашими службами (а также со связанными с ними приложениями и средой), и где, вероятно, оповещаем о превышении пороговых значений и проводим проверки работоспособности [107].
Собрав логи в одном месте, мы можем преобразовать их в показатели, подсчитывая их в маршрутизаторе событий; например, такое событие, как «child pid 14024 exit signal Segmentation fault», может быть подсчитано и просуммировано как один из показателей ошибки сегментации во всей производственной инфраструктуре.
Преобразовав логи в показатели, мы можем применить к ним статистические методы, например обнаружение отклонений от нормального состояния, чтобы выявлять выбросы и отклонения еще раньше. Скажем, настроить систему оповещения так, чтобы она сообщала о переходе от десяти ошибок сегментации на прошлой неделе к тысячам таких ошибок за последний час, что, конечно, требует тщательного расследования.
В дополнение к сбору телеметрии из служб и окружения необходимо также фиксировать важные события в процессе развертывания, например, когда программа проходит или проваливает автоматизированные тесты или когда мы развертываем продукт в любой среде. Кроме того, надо собирать данные, сколько времени требуется на выполнение сборок и на прохождение тестов. Так мы можем заметить условия, свидетельствующие о возможных проблемах, например если тест качества работы или сборка занимают в два раза больше времени, чем нужно. Это позволит найти и исправить ошибки до того, как они перейдут в фазу эксплуатации.
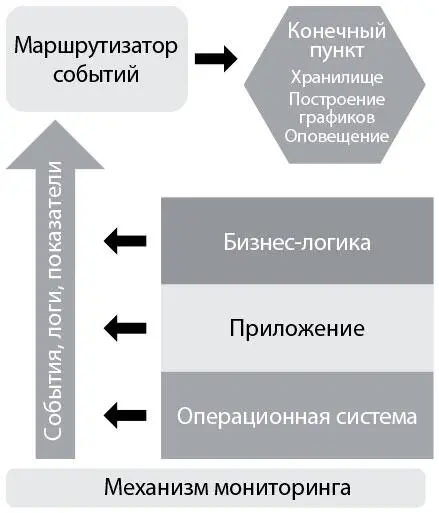
Рис. 26. Механизм мониторинга (источник: Торнбулл. The Art of Monitoring, Kindle edition, глава 2)
Далее нужно убедиться, что в нашу телеметрическую инфраструктуру легко заносить новую информацию и извлекать старую. Хорошо, если все будет организовано с помощью самообслуживающихся API, чтобы не приходилось оформлять тикет [108]и долго ждать отчета.
В идеале нужно создать телеметрическую систему, информирующую нас, когда, а также где и как именно произошло нечто интересное. Эта система должна быть удобна для анализа вручную и автоматизированно, а также данные должны быть доступны для анализа без доступа к самому приложению, предоставившему логи. Как заметил Адриан Коккрофт, «Мониторинг настолько важен, что наши системы мониторинга должны быть более доступными и более гибкими, чем то, за чем они наблюдают».
Термин «телеметрия» синонимичен слову «показатели»: это все логи событий и все индикаторы служб на всех уровнях стека приложения, полученные как на этапе эксплуатации, так и до него, а также в процессе развертывания продукта.
Теперь, когда у нас есть инфраструктура централизованной телеметрии, мы должны удостовериться в том, что все разрабатываемые и используемые приложения поставляют достаточное количество нужных данных. Для этого инженеры разработки и эксплуатации должны генерировать телеметрию эксплуатации в процессе своей повседневной работы как для новых, так и для уже существующих служб.
Скотт Праф, главный архитектор и вице-президент отдела разработки компании CSG, отметил: «Каждый раз, когда NASA запускает ракету, тысячи автоматизированных сенсоров в ней отчитываются о состоянии каждого компонента этого ценнейшего объекта. А мы же часто не принимаем таких же мер предосторожности с нашими программами. Мы обнаружили, что создание телеметрии на уровнях приложения и инфраструктуры — одна из самых выгодных инвестиций, что мы когда-либо делали. В 2014 г. мы фиксировали более миллиарда событий в день, причем данные поступали из более чем сотни тысяч мест в коде».
Читать дальшеИнтервал:
Закладка:
Похожие книги на «Руководство по DevOps»
Представляем Вашему вниманию похожие книги на «Руководство по DevOps» списком для выбора. Мы отобрали схожую по названию и смыслу литературу в надежде предоставить читателям больше вариантов отыскать новые, интересные, ещё непрочитанные произведения.












Обсуждение, отзывы о книге «Руководство по DevOps» и просто собственные мнения читателей. Оставьте ваши комментарии, напишите, что Вы думаете о произведении, его смысле или главных героях. Укажите что конкретно понравилось, а что нет, и почему Вы так считаете.