Евгений Роговский - Нужна ли анонимность демократическому информационному обществу?
Здесь есть возможность читать онлайн «Евгений Роговский - Нужна ли анонимность демократическому информационному обществу?» весь текст электронной книги совершенно бесплатно (целиком полную версию без сокращений). В некоторых случаях можно слушать аудио, скачать через торрент в формате fb2 и присутствует краткое содержание. Год выпуска: 2013, Издательство: Россия и Америка в XXI веке, Жанр: Интернет, Культурология, на русском языке. Описание произведения, (предисловие) а так же отзывы посетителей доступны на портале библиотеки ЛибКат.

- Название:Нужна ли анонимность демократическому информационному обществу?
- Автор:
- Издательство:Россия и Америка в XXI веке
- Жанр:
- Год:2013
- ISBN:нет данных
- Рейтинг книги:4 / 5. Голосов: 1
-
Избранное:Добавить в избранное
- Отзывы:
-
Ваша оценка:
Нужна ли анонимность демократическому информационному обществу?: краткое содержание, описание и аннотация
Предлагаем к чтению аннотацию, описание, краткое содержание или предисловие (зависит от того, что написал сам автор книги «Нужна ли анонимность демократическому информационному обществу?»). Если вы не нашли необходимую информацию о книге — напишите в комментариях, мы постараемся отыскать её.
Нужна ли анонимность демократическому информационному обществу? — читать онлайн бесплатно полную книгу (весь текст) целиком
Ниже представлен текст книги, разбитый по страницам. Система сохранения места последней прочитанной страницы, позволяет с удобством читать онлайн бесплатно книгу «Нужна ли анонимность демократическому информационному обществу?», без необходимости каждый раз заново искать на чём Вы остановились. Поставьте закладку, и сможете в любой момент перейти на страницу, на которой закончили чтение.
Интервал:
Закладка:
В докладе показано, как много могут рассказать о человеке пометки like («нравится»), которые расставляют пользователи сети Facebook . В принципе пометки like подобны иным широко распространенным «цифровым следам» поведения пользователей в сети Интернет, таким, например, как «статистика использования браузеров» ( browsing histories ), «вопросы, задаваемые в поисковых системах» ( search queries ) или «история покупок в интернет-магазинах» ( purchase histories ). Однако пометки like отличаются от иных источников информации тем, что постоянно доступны «по умолчанию». Как оказалось, эти пометки представляют собой универсальный массив цифровой информации, подобный запросам в поисковых системах, протоколам посещения Web -сайтов или записям о покупках, сделанных по кредитной карте. На основе этого массива достаточно точно могут быть оценены многие чувствительные «атрибуты личности» от сексуальной ориентации до уровня интеллектуального развития.
Доклад демонстрирует эффективный пример применения в практической психологии хорошо опробованных методов статистического моделирования. В ней показано, как именно относительно простые, рутинные протокольные цифровые записи о действиях пользователя киберпространства могут быть использованы для автоматической оценки широкой палитры персональных характеристик («атрибутов»). Проводя в сети все больше времени, пользователи Facebook "клик за кликом" рисуют удивительно точную картину самих себя и не ощущают при этом того, что раскрывают свою конфиденциальную информацию. Авторы этого исследования честно признались, что специально выбрали те параметры, "наклонности" и "атрибуты" личности пользователей, которые в наибольшей степени иллюстрируют, насколько точными и настораживающими могут быть результаты их прогнозирования на основе общедоступной информации. Им удалось создать программу, достаточно точно "предсказывающую" не только пол и возраст пользователей, но также и такие высокочувствительные их личные данные ("персональные атрибуты"), как сексуальная ориентация, этническая и религиозная принадлежность, политические взгляды, личные наклонности, уровень интеллектуального развития и удовлетворенности своей жизнью ("уровень счастья"), употребление наркотиков, разобщенность родителей и проч. В общем виде схема проведенного исследования представлена на рис. 1 .
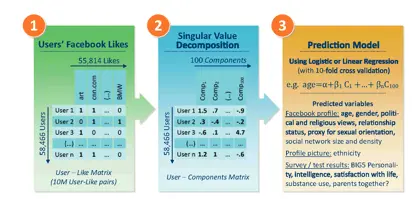
Общая схема исследования
1) В Facebook были выбраны 58 466 добровольцев из США, которые согласились поработать с приложением My Personality Facebook ( www.mypersonality.org/wiki ) и расставить свои пометки like ("нравится") на различных материалах (контенте), доступных в этой социальной сети: фотографиях, "друзьях", интересных страницах, спорте, музыке, книгах, ресторанах, популярных Web -сайтах и проч. В среднем каждый из участников расставил примерно 170 пометок, всего пометок удостоились 55 814 материалов, при этом абсолютное большинство из них отмечалось неоднократно, то есть разными участниками. По завершении работы с этим приложением оно содержало информацию об участниках, взятую из их "профилей Facebook ", список расставленных ими пометок like , а также некоторую иную информацию.
Далее была сделана матрица "участник — пометка" (представлена на рис. 1 слева), составленная из строк, каждая из которых содержит пометки, поставленные одним участником. В клетку матрицы ставилась "1", если данный участник (строка) пометил данный материал (столбец) словом like , и "0" — в противном случае. Всего в такой матрице было проставлено около 10 млн. единиц (? 58466 *170, то есть произведение количества участников на число помет).
2) На втором шаге размерность матрицы "участник — пометка" была сокращена с помощью формального математического метода "сингулярно-значимой декомпозиции" ( singular-value decomposition, SVD ) [14] Golub, G. H., Kahan, W. Calculating the singular values and pseudo-inverse of a matrix / SIAM (Society for Industrial and Applied Mathematics) // Journal on Mathematical Analysis. 1965, Vol. 2, No. 2, pp. 205–224.
. В результате исходная матрица была преобразована в матрицу "участник — компоненты" (представлена на рис. 1 в центре), у которой количество столбцов сокращено до 100 в соответствие с числом выделенных значимых факторов (компонент). Клетки этой матрицы заполнялись не "1", а специально рассчитанными "коэффициентами значения" той или иной компоненты.
Интервал:
Закладка:
Похожие книги на «Нужна ли анонимность демократическому информационному обществу?»
Представляем Вашему вниманию похожие книги на «Нужна ли анонимность демократическому информационному обществу?» списком для выбора. Мы отобрали схожую по названию и смыслу литературу в надежде предоставить читателям больше вариантов отыскать новые, интересные, ещё непрочитанные произведения.










Обсуждение, отзывы о книге «Нужна ли анонимность демократическому информационному обществу?» и просто собственные мнения читателей. Оставьте ваши комментарии, напишите, что Вы думаете о произведении, его смысле или главных героях. Укажите что конкретно понравилось, а что нет, и почему Вы так считаете.