Джон Келлехер - Наука о данных. Базовый курс
Здесь есть возможность читать онлайн «Джон Келлехер - Наука о данных. Базовый курс» — ознакомительный отрывок электронной книги совершенно бесплатно, а после прочтения отрывка купить полную версию. В некоторых случаях можно слушать аудио, скачать через торрент в формате fb2 и присутствует краткое содержание. Город: Москва, Год выпуска: 2020, ISBN: 2020, Издательство: Альпина Паблишер, Жанр: Базы данных, на русском языке. Описание произведения, (предисловие) а так же отзывы посетителей доступны на портале библиотеки ЛибКат.

- Название:Наука о данных. Базовый курс
- Автор:
- Издательство:Альпина Паблишер
- Жанр:
- Год:2020
- Город:Москва
- ISBN:978-5-9614-3378-4
- Рейтинг книги:3 / 5. Голосов: 1
-
Избранное:Добавить в избранное
- Отзывы:
-
Ваша оценка:
Наука о данных. Базовый курс: краткое содержание, описание и аннотация
Предлагаем к чтению аннотацию, описание, краткое содержание или предисловие (зависит от того, что написал сам автор книги «Наука о данных. Базовый курс»). Если вы не нашли необходимую информацию о книге — напишите в комментариях, мы постараемся отыскать её.
Книга знакомит с основами науки о данных. В ней охватываются все ключевые аспекты, начиная с истории развития сбора и анализа данных и заканчивая этическими проблемами, связанными с конфиденциальностью информации. Авторы объясняют, как работают нейронные сети и машинное обучение, приводят примеры анализа бизнес-проблем и того, как их можно решить, рассказывают о сферах, на которые наука о данных окажет наибольшее влияние в будущем.
«Наука о данных» уже переведена на японский, корейский и китайский языки.
Наука о данных. Базовый курс — читать онлайн ознакомительный отрывок
Ниже представлен текст книги, разбитый по страницам. Система сохранения места последней прочитанной страницы, позволяет с удобством читать онлайн бесплатно книгу «Наука о данных. Базовый курс», без необходимости каждый раз заново искать на чём Вы остановились. Поставьте закладку, и сможете в любой момент перейти на страницу, на которой закончили чтение.
Интервал:
Закладка:

Обучение с учителем называется именно так, потому что каждый объект в наборе данных содержит как входные значения, так и выходное (целевое) значение. Таким образом, алгоритм обучения может направлять свой поиск наилучшей функции, проверяя соответствие каждой пробуемой функции набору данных, и в то же время сам набор данных выступает в качестве контролера процесса обучения или учителя, обеспечивая обратную связь. Очевидно, что для обучения с учителем каждый объект в наборе данных должен быть промаркирован значением целевого атрибута. Однако зачастую целевой атрибут бывает сложно измерить в необработанном виде, а значит, и создать набор данных с маркированными объектами. При подобном сценарии много времени и усилий тратится, чтобы создать набор данных с целевыми значениями атрибутов, прежде чем модель можно будет обучать.
При обучении без учителя целевой атрибут отсутствует. Следовательно, алгоритмы обучения без учителя не требуют времени и усилий на маркировку целевым атрибутом объектов в наборе данных. Однако отсутствие целевого атрибута означает и то, что обучение становится более сложным: вместо конкретной задачи поиска соответствующего отображения между входным и выходным значениями, перед алгоритмом ставится более общая задача поиска закономерностей в данных. Самым распространенным типом обучения без учителя является кластерный анализ, когда алгоритм ищет кластеры объектов, схожих друг с другом. Часто эти алгоритмы кластеризации начинают со случайной группы кластеров, а затем итеративно обновляют кластеры (перебрасывая объекты из одного кластера в другой) таким образом, чтобы увеличить подобие внутри каждого кластера и разницу между ними.
Задача кластеризации — выяснить, как измерить подобие. Если все атрибуты в наборе данных являются числовыми и имеют одинаковые диапазоны, то, вероятно, имеет смысл просто рассчитать евклидово расстояние (или расстояние по прямой) между рядами. Объекты, которые находятся близко друг к другу в евклидовом пространстве, рассматриваются как подобные. Однако существует ряд факторов, которые могут усложнить обнаружение сходства между объектами. В некоторых наборах данных разные числовые атрибуты имеют разные диапазоны, в результате чего разброс значений в одном атрибуте может быть не таким значительным, как в другом. В таких случаях атрибуты должны быть нормализованы путем присвоения им одинакового диапазона. Еще одним усложняющим фактором при расчете сходства является то, что подобие объектов можно определять по-разному. Порой одни атрибуты являются более важными, чем другие, поэтому имеет смысл при расчетах задавать весовой параметр некоторым атрибутам, что бывает необходимо и тогда, когда набор данных содержит нечисловые значения. Эти более сложные сценарии могут потребовать разработки индивидуальных параметров подобия для использования алгоритмом кластеризации.
Чтобы проиллюстрировать обучение без учителя на конкретном примере, представим, что мы проводим анализ причин развития диабета 2-го типа среди взрослых белых американцев мужского пола. Мы начнем с построения набора данных, в котором каждая строка будет представлять одного человека, а столбцы — атрибуты, которые, по нашему мнению, имеют отношение к исследованию. Для этого примера мы возьмем следующие атрибуты: рост человека в метрах, его вес в килограммах, продолжительность тренировок в течение недели в минутах, размер обуви и вероятность развития у него диабета, полученную на основе клинических тестов и изучения образа жизни, выраженную в процентах. Таблица 2 иллюстрирует фрагмент этого набора данных. Очевидно, что есть и другие атрибуты, которые могут быть включены в набор, например возраст человека, и что среди выбранных атрибутов есть лишние, например размер обуви, который не коррелирует с развитием сахарного диабета. Как мы обсуждали в главе 2, выбор атрибутов для набора данных — ключевая задача науки о данных, но в этом примере мы намеренно будем работать с таким набором данных, какой у нас есть.
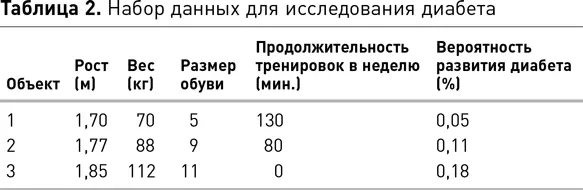
При обучении без учителя алгоритм кластеризации будет искать группы строк, которые более похожи друг на друга, чем на другие строки. Каждая из этих групп определяет кластер подобных объектов. С точки зрения изучения причин развития диабета выявление кластеров схожих пациентов (объектов) может помочь выявить причины заболевания или сопутствующих диабету заболеваний путем поиска значений атрибутов, которые относительно часто встречаются в кластере. Простая идея поиска кластеров подобных объектов служит мощным инструментом и применима ко многим областям жизни. Другой пример кластеризации строк — предоставление рекомендаций для клиентов. Если клиенту понравилась книга, песня или фильм, он с высокой вероятностью получит удовольствие от другой книги, песни или фильма из того же кластера.
Читать дальшеИнтервал:
Закладка:
Похожие книги на «Наука о данных. Базовый курс»
Представляем Вашему вниманию похожие книги на «Наука о данных. Базовый курс» списком для выбора. Мы отобрали схожую по названию и смыслу литературу в надежде предоставить читателям больше вариантов отыскать новые, интересные, ещё непрочитанные произведения.











Обсуждение, отзывы о книге «Наука о данных. Базовый курс» и просто собственные мнения читателей. Оставьте ваши комментарии, напишите, что Вы думаете о произведении, его смысле или главных героях. Укажите что конкретно понравилось, а что нет, и почему Вы так считаете.