Джон Келлехер - Наука о данных. Базовый курс
Здесь есть возможность читать онлайн «Джон Келлехер - Наука о данных. Базовый курс» — ознакомительный отрывок электронной книги совершенно бесплатно, а после прочтения отрывка купить полную версию. В некоторых случаях можно слушать аудио, скачать через торрент в формате fb2 и присутствует краткое содержание. Город: Москва, Год выпуска: 2020, ISBN: 2020, Издательство: Альпина Паблишер, Жанр: Базы данных, на русском языке. Описание произведения, (предисловие) а так же отзывы посетителей доступны на портале библиотеки ЛибКат.

- Название:Наука о данных. Базовый курс
- Автор:
- Издательство:Альпина Паблишер
- Жанр:
- Год:2020
- Город:Москва
- ISBN:978-5-9614-3378-4
- Рейтинг книги:3 / 5. Голосов: 1
-
Избранное:Добавить в избранное
- Отзывы:
-
Ваша оценка:
Наука о данных. Базовый курс: краткое содержание, описание и аннотация
Предлагаем к чтению аннотацию, описание, краткое содержание или предисловие (зависит от того, что написал сам автор книги «Наука о данных. Базовый курс»). Если вы не нашли необходимую информацию о книге — напишите в комментариях, мы постараемся отыскать её.
Книга знакомит с основами науки о данных. В ней охватываются все ключевые аспекты, начиная с истории развития сбора и анализа данных и заканчивая этическими проблемами, связанными с конфиденциальностью информации. Авторы объясняют, как работают нейронные сети и машинное обучение, приводят примеры анализа бизнес-проблем и того, как их можно решить, рассказывают о сферах, на которые наука о данных окажет наибольшее влияние в будущем.
«Наука о данных» уже переведена на японский, корейский и китайский языки.
Наука о данных. Базовый курс — читать онлайн ознакомительный отрывок
Ниже представлен текст книги, разбитый по страницам. Система сохранения места последней прочитанной страницы, позволяет с удобством читать онлайн бесплатно книгу «Наука о данных. Базовый курс», без необходимости каждый раз заново искать на чём Вы остановились. Поставьте закладку, и сможете в любой момент перейти на страницу, на которой закончили чтение.
Интервал:
Закладка:
Hadoop — это платформа с открытым исходным кодом, которая была разработана и выпущена Apache Software Foundation. Она хорошо зарекомендовала себя для эффективного приема и хранения больших объемов данных и обходится дешевле, чем традиционный подход. Кроме того, на рынке появился широкий ассортимент продуктов для обработки и анализа данных на платформе Hadoop. Приведенное выше высказывание, касающееся современных баз данных — «переместить алгоритмы в данные, вместо того чтобы перемещать данные в алгоритмы», — также применимо и к Hadoop.
В Hadoop данные делятся на разделы, которые распределяются по узлам кластера. В процессе работы с Hadoop различные аналитические инструменты обрабатывают данные в каждом из кластеров (часть этих данных может постоянно находиться в оперативной памяти), что обеспечивает быструю обработку данных, поскольку несколько кластеров анализируются одновременно. Ни извлечение данных, ни ETL-процесс не требуются. Данные анализируются там, где они хранятся. Существуют и другие примеры аналогичного подхода, скажем решения от Google и Amazon, где аналитическое программное обеспечение, такое как Spark, разворачивается на распределенных вычислительных архитектурах, позволяя анализировать данные там, где они находятся.
В мире больших данных специалист может запрашивать их массивные наборы с использованием аналитических языков, таких как Spark, Flink, Storm, и широкого спектра инструментов, а также постоянно растущего числа бесплатных и коммерческих продуктов. Эти продукты представляют собой инструменты высокоуровневой аналитики или панели мониторинга, которые упрощают работу специалиста с данными и аналитикой, что позволяет ему сконцентрироваться на анализе данных. Однако современному специалисту по данным приходится анализировать их в двух разных местах: в современных базах данных и в хранилищах больших данных на Hadoop. В следующей части мы рассмотрим, как решается эта проблема.
Если у организации нет данных такого размера и масштаба, которым требуется Hadoop, то для управления данными ей будет достаточно традиционной базы данных. Однако есть мнение, что инструменты хранения и обработки данных, доступные в мире Hadoop, в итоге вытеснят традиционные базы данных. Такое сложно себе представить, и потому в последнее время обсуждается более сбалансированный подход к управлению данными в так называемом мире гибридных баз, где традиционные базы данных сосуществуют с Hadoop.

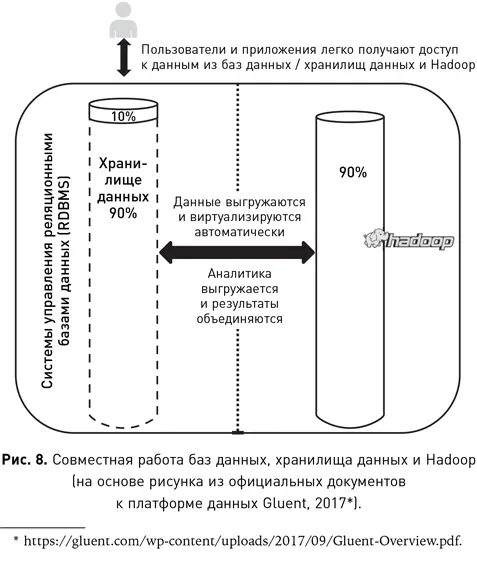
В мире гибридных баз все данные связаны между собой и работают вместе, что позволяет эффективно обмениваться ими, обрабатывать и анализировать их. На рис. 8 показано традиционное хранилище данных, но при этом большая часть данных находится не в базе или хранилище, а перемещена в Hadoop. Между базой данных и Hadoop создается соединение, которое позволяет специалисту запрашивать данные, как если бы они находились в одном месте. Ему не потребуется запрашивать отдельно данные из базы и из Hadoop. Гибридная база автоматически определит, какие части запроса необходимо выполнить в каждом из местоположений, затем объединит результаты и представит их специалисту. Точно так же по мере роста хранилища часть данных устаревает, и гибридное решение автоматически перемещает редко используемые данные в среду Hadoop, а те, что становятся востребованными, наоборот, возвращает обратно. Гибридная база данных сама определяет местоположение данных на основе частоты запросов и типа проводимого анализа.
Одним из преимуществ гибридных решений является то, что специалист по-прежнему запрашивает данные на SQL. Ему не нужно изучать другой язык запросов или применять особые инструменты. Сегодняшние тенденции позволяют предположить, что в ближайшем будущем основные поставщики баз данных, облачных хранилищ и программного обеспечения для интеграции данных будут предлагать именно гибридные решения.
Подготовка и интеграция данных
Интеграция данных включает в себя их получение из разных источников и последующее объединение с целью получения единого представления данных по всей организации. Разберем это на примере медицинской карты. В идеале у каждого человека должна быть одна медицинская карта, чтобы каждая больница, поликлиника и врач могли использовать один и тот же идентификатор пациента, единицы измерения, систему оценок и т. д. К сожалению, почти в каждой больнице имеется собственная независимая система учета пациентов и то же справедливо в отношении внутрибольничных медицинских лабораторий. Представьте себе, как трудно бывает найти историю болезни и назначить правильное лечение пациенту. Такие проблемы возникают в рамках одной больницы. Когда же несколько больниц обмениваются данными пациентов, проблемы их интеграции становятся еще существеннее. Именно поэтому первые три этапа CRISP-DM занимают до 70–80 % общего времени проекта, причем бо́льшая часть этого времени уходит на интеграцию данных.
Читать дальшеИнтервал:
Закладка:
Похожие книги на «Наука о данных. Базовый курс»
Представляем Вашему вниманию похожие книги на «Наука о данных. Базовый курс» списком для выбора. Мы отобрали схожую по названию и смыслу литературу в надежде предоставить читателям больше вариантов отыскать новые, интересные, ещё непрочитанные произведения.











Обсуждение, отзывы о книге «Наука о данных. Базовый курс» и просто собственные мнения читателей. Оставьте ваши комментарии, напишите, что Вы думаете о произведении, его смысле или главных героях. Укажите что конкретно понравилось, а что нет, и почему Вы так считаете.