Crispin, Lisa - Agile Testing - A Practical Guide for Testers and Agile Teams
Здесь есть возможность читать онлайн «Crispin, Lisa - Agile Testing - A Practical Guide for Testers and Agile Teams» весь текст электронной книги совершенно бесплатно (целиком полную версию без сокращений). В некоторых случаях можно слушать аудио, скачать через торрент в формате fb2 и присутствует краткое содержание. Год выпуска: 2008, Издательство: Addison-Wesley Professional, Жанр: Старинная литература, на английском языке. Описание произведения, (предисловие) а так же отзывы посетителей доступны на портале библиотеки ЛибКат.

- Название:Agile Testing: A Practical Guide for Testers and Agile Teams
- Автор:
- Издательство:Addison-Wesley Professional
- Жанр:
- Год:2008
- ISBN:нет данных
- Рейтинг книги:4 / 5. Голосов: 1
-
Избранное:Добавить в избранное
- Отзывы:
-
Ваша оценка:
Agile Testing: A Practical Guide for Testers and Agile Teams: краткое содержание, описание и аннотация
Предлагаем к чтению аннотацию, описание, краткое содержание или предисловие (зависит от того, что написал сам автор книги «Agile Testing: A Practical Guide for Testers and Agile Teams»). Если вы не нашли необходимую информацию о книге — напишите в комментариях, мы постараемся отыскать её.
Agile Testing: A Practical Guide for Testers and Agile Teams — читать онлайн бесплатно полную книгу (весь текст) целиком
Ниже представлен текст книги, разбитый по страницам. Система сохранения места последней прочитанной страницы, позволяет с удобством читать онлайн бесплатно книгу «Agile Testing: A Practical Guide for Testers and Agile Teams», без необходимости каждый раз заново искать на чём Вы остановились. Поставьте закладку, и сможете в любой момент перейти на страницу, на которой закончили чтение.
Интервал:
Закладка:
At the functional test level, our FitNesse test fixtures build data in-memory wherever possible. These tests run quickly, and the results appear almost instantaneously. When we need to test the database layer, or if we need to test legacy code that’s not accessible independently of the database layer, we usually write FitNesse tests that set up and tear down their own data using a home-grown data fixture. These tests are necessary, but they run slowly and are expensive to maintain, so we keep them to the absolute minimum needed to give us confidence. We want our build that runs business-facing tests to provide feedback within a couple of hours in order to keep us productive.
—Lisa
Comprehensive explanations and examples of various types of test doubles can be found in xUnit Test Patterns . See the bibliography for more information on that and tools for working with test stubs and with mock and fake objects.
Because it’s so difficult to get traction on test automation, it would be easy to say “OK, we’ve got some tests, and they do take hours to run, but it’s better than no tests.” Database access is a major contributor to slow tests. Keep taking small steps to fake the database where you can, and test as much logic as possible without involving the database. If this is difficult, reevaluate your system architecture and see if it can be organized better for testing.
Tools such as DbFit and NdbUnit can simplify database testing and enable test-driven database development; see the bibliography for more resources.
If you’re testing business logic, algorithms, or calculations in code, you’re interested in the behavior of the code itself given certain inputs; you don’t care where the data comes from as long as it accurately represents real data. If this is the case, build test data that is part of the test and can be accessed in memory, and let the production code operate from that. Simulate database access and objects, and focus on the purpose of the test. Not only will the tests run faster, but they’ll be easier to write and maintain.
When generating data for a test, use values that reflect the intent of the test, where possible. Unless you’re completely confident that each test is independent, generate unique test values for each test. For example, use timestamps as part of the field values. Unique data is another safety net to keep tests from infecting each other with stray data. When you need large amounts of data, try generating the data randomly, but always clean it up at the end of the test so that it doesn’t bleed into the next test. We recognize that sometimes you need to test very specific types of data. In these cases, randomly generated data would defeat the purpose of the test. But you may be able to use enough randomization to ensure that each test has unique inputs.
When Database Access Is Unavoidable or Even Desirable
If the system under test relies heavily on the database, this naturally has to be tested. If the code you’re testing reads from and/or writes to the database, at some point you need to test that, and you’ll probably want at least some regression tests that verify the database layer of code.
Setup/Teardown Data for Each Test
Our preferred approach is to have every test add the data it needs to a test schema, operate on the data, verify the results in the database, and then delete all of that test data so the test can be rerun without impacting other subsequent tests. This supports the idea that tests are independent of each other.
Lisa’s Story
We use a generic data fixture that lets the person writing the test specify the database table, columns, and values for the columns in order to add data. Another generic data lookup fixture lets us enter a table name and SQL where clause to verify the actual persisted data. We can also use the generic data fixture to delete data using the table name and a key value. Figure 14-3 shows an example of a table that uses a data fixture to build test data in the database. It populates the table “all fund” with the specified columns and values. It’s easy for those of us writing test cases to populate the tables with all of the data we need.
Figure 14-3 Example of a table using a data fixture to build test data in the database
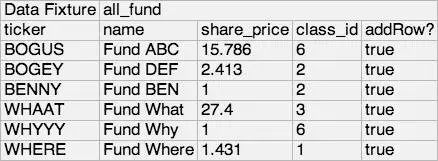
Note that the schemas we use for these tests have most of their constraints removed, so we only have to populate the tables and columns pertinent to the functionality being tested. This makes maintenance a little easier, too. The downside is that the test is a bit less realistic, but tests using other tools verify the functionality with a realistic environment.
The downside to creating test data this way is that whenever a change is made in the database, such as a new column with a required value, all of the data fixture tables in the tests that populate that table will have to be changed. These tests can be burdensome to write and maintain, so we only use them when absolutely needed. We try to design the tests to keep maintenance costs down. For example, the data fixture in Figure 14-3 is in an “include” library and can be included into the tests that need it. Let’s say we add a new column, “fund_category.” We only need to add it to this “include” table, rather than in 20 different tests that use it.
—Lisa
Canonical Data
Another alternative is having test schemas that can quickly be refreshed with data from a canonical or seed database. The idea is that this seed data is a representative sample of real production data. Because it’s a small amount of data, it can be quickly rebuilt each time a suite of regression tests needs to be run.
This approach also increases the time it takes to run tests, but it’s just a few minutes at the start of the regression suite rather than taking time out of each individual test. The tests will still be slower than tests that don’t access the database, but they’ll be faster than tests that have to laboriously populate every column in every table.
Canonical data has many uses. Testers and programmers can have their own test schema to refresh at will. They can conduct both manual and automated tests without stepping on anyone else’s testing. If the data is carefully chosen, the data will be more realistic than the limited amount of data each test can build for itself.
Of course, as with practically everything, there’s a downside. Canonical data can be a pain to keep up. When you need new test scenarios, you have to identify production data that will work, or make up the data you need and add it to the seed schema. You have to scrub the data, mask real peoples’ identifying characteristics, making it innocuous for security reasons. Every time you add a table or column to the production database, you must update your test schemas accordingly. You might have to roll date-sensitive data forward every year, or do other large-scale maintenance. You have to carefully select which tables should be refreshed and which tables don’t need refreshing, such as lookup tables. If you have to add data to increase test coverage, the refresh will take longer to do, increasing the time of the build process that triggers it. As we’ve been emphasizing, it’s important that your automated builds provide feedback in a timely manner, so longer and longer database refreshes lengthen your feedback cycle. You also lose the test independence with canonical data, so if one test fails, others may follow suit.
Lisa’s team members run their GUI test suites and some of their functional regression tests against schemas refreshed each run with canonical data. On rare occasions, tests fail unexpectedly because of an erroneous update to the seed data. Deciding whether to “roll” data forward, so that, for example, 2008’s rows become 2009’s rows, gets to be a headache. So far, the ROI on using canonical data has been acceptable for the team. Janet’s current team also uses seed data for its “middle layer” testing on local builds. It works well for fast feedback during the development cycle. However, the test environment and the staging environments use a migrated copy of production data. The downside is that the regression tests can only be run on local copies of the build. The risk is low because they practice “build once, deploy to many.”
Читать дальшеИнтервал:
Закладка:
Похожие книги на «Agile Testing: A Practical Guide for Testers and Agile Teams»
Представляем Вашему вниманию похожие книги на «Agile Testing: A Practical Guide for Testers and Agile Teams» списком для выбора. Мы отобрали схожую по названию и смыслу литературу в надежде предоставить читателям больше вариантов отыскать новые, интересные, ещё непрочитанные произведения.












Обсуждение, отзывы о книге «Agile Testing: A Practical Guide for Testers and Agile Teams» и просто собственные мнения читателей. Оставьте ваши комментарии, напишите, что Вы думаете о произведении, его смысле или главных героях. Укажите что конкретно понравилось, а что нет, и почему Вы так считаете.