Неизвестно - Prolog
Здесь есть возможность читать онлайн «Неизвестно - Prolog» весь текст электронной книги совершенно бесплатно (целиком полную версию без сокращений). В некоторых случаях можно слушать аудио, скачать через торрент в формате fb2 и присутствует краткое содержание. Жанр: Старинная литература, на русском языке. Описание произведения, (предисловие) а так же отзывы посетителей доступны на портале библиотеки ЛибКат.
- Название:Prolog
- Автор:
- Жанр:
- Год:неизвестен
- ISBN:нет данных
- Рейтинг книги:3 / 5. Голосов: 1
-
Избранное:Добавить в избранное
- Отзывы:
-
Ваша оценка:
Prolog: краткое содержание, описание и аннотация
Предлагаем к чтению аннотацию, описание, краткое содержание или предисловие (зависит от того, что написал сам автор книги «Prolog»). Если вы не нашли необходимую информацию о книге — напишите в комментариях, мы постараемся отыскать её.
Prolog — читать онлайн бесплатно полную книгу (весь текст) целиком
Ниже представлен текст книги, разбитый по страницам. Система сохранения места последней прочитанной страницы, позволяет с удобством читать онлайн бесплатно книгу «Prolog», без необходимости каждый раз заново искать на чём Вы остановились. Поставьте закладку, и сможете в любой момент перейти на страницу, на которой закончили чтение.
Интервал:
Закладка:
Этот вопрос порождает следующую последовательность целей:
конк( [а, b, с], [d, e], L)
конк( [b, с], [d, e], L') где L = [a | L']
конк( [с], [d, e], L") где L' = [b | L"]
конк( [ ], [d, e], L'") где L" = [c | L''']
true (истина) где L'" = [d, е]
Ясно, что программа фактически сканирует весь первый список, пока не обнаружит его конец.
А нельзя ли было бы проскочить весь первый список за один шаг и сразу подсоединить к нему второй список, вместо того, чтобы постепенно продвигаться вдоль него? Но для этого необходимо знать, где расположен конец списка, а следовательно, мы нуждаемся в другом его представлении. Один из вариантов - представлять список парой списков. Например, список
[а, b, с]
можно представить следующими двумя списками:
L1 = [a, b, c, d, e]
L2 = [d, e]
Подобная пара списков, записанная для краткости как L1-L2, представляет собой "разность" между L1 и L2. Это представление работает только при том условии, что L2 - "конечный участок" списка L1. Заметим, что один и тот же список может быть представлен несколькими "разностными парами". Поэтому список [а, b, с]можно представить как
[а, b, с]-[ ]
или
[a, b, c, d, e]-[d, e]
или
[a, b, c, d, e | T]-[d, e | T]
или
[а, b, с | Т]-Т
где Т - произвольный список, и т.п. Пустой список представляется любой парой L-L.
Поскольку второй член пары указывает на конец списка, этот конец доступен сразу. Это можно использовать для эффективной реализации конкатенации. Метод показан на рис. 8.1. Соответствующее отношение конкатенации записывается на Прологе в виде факта
конкат( A1-Z1, Z1-Z2, A1-Z2).
Давайте используем конкатдля конкатенации двух списков: списка [а, b, с], представленного парой [а, b, с | Т1]-Т1, и списка [d, e], представленного парой [d, e | Т2]-Т2 :
?- конкат( [а, b, с | Т1]-T1, [d, е | Т2]-Т2, L ).
Оказывается, что для выполнения конкатенации достаточно простого сопоставления этой цели с предложением конкат. Результат сопоставления:
T1 = [d, e | Т2]
L = [a, b, c, d, e | T2]-T2
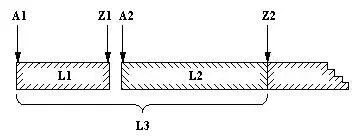
Рис. 8. 1. Конкатенация списков, представленных в виде разностных пар.
L1представляется как A1-Z1, L2как A2-Z2и результат L3- как A1-Z2.
При этом должно выполняться равенство Z1 = А2.
8. 5. 4. Повышение эффективности зa счет добавления вычисленных фактов к базе данных
Иногда в процессе вычислений приходится одну и ту же цель достигать снова и снова. Поскольку в Прологе отсутствует специальный механизм выявления этой ситуации, соответствующая цепочка вычислений каждый раз повторяется заново.
В качестве примера рассмотрим программу вычисления N-го числа Фибоначчи для некоторого заданного N. Последовательность Фибоначчи имеет вид:
1, 1, 2, 3, 5, 8, 13, ...
Каждый член последовательности, за исключением первых двух, представляет собой сумму предыдущих двух членов. Для вычисления N-гo числа Фибоначчи F определим предикат
фиб( N, F)
Нумерацию чисел последовательности начнем с N = 1. Программа для фибобрабатывает сначала первые два числа Фибоначчи как два особых случая, а затем определяет общее правило построения последовательности Фибоначчи:
фиб( 1, 1). % 1-е число Фибоначчи
фиб( 2, 1). % 2-е число Фибоначчи
фиб( N, F) :- % N-е число Фиб., N > 2
N > 2,
N1 is N - 1, фиб( N1, F1),
N2 is N - 2, фиб( N2, F2),
F is F1 + F2. % N-e число есть сумма двух
% предыдущих
Процедура фибимеет тенденцию к повторению вычислений. Это легко увидеть, если трассировать цель
?- фиб( 6, F).
На рис. 8.2 показано, как протекает этот вычислительный процесс. Например, третье число Фибоначчи f( 3) понадобилось в трех местах, и были повторены три раза одни и те же вычисления.
Этого легко избежать, если запоминать каждое вновь вычисленное число. Идея состоит в применении встроенной процедуры assertдля добавления этих (промежуточных) результатов в базу данных в виде фактов. Эти факты должны предшествовать другим предложениям, чтобы предотвратить применение общего правила в случаях, для которых результат уже известен. Усовершенствованная процедура фиб2отличается от фибтолько этим добавлением:
Читать дальшеИнтервал:
Закладка:
Похожие книги на «Prolog»
Представляем Вашему вниманию похожие книги на «Prolog» списком для выбора. Мы отобрали схожую по названию и смыслу литературу в надежде предоставить читателям больше вариантов отыскать новые, интересные, ещё непрочитанные произведения.




Обсуждение, отзывы о книге «Prolog» и просто собственные мнения читателей. Оставьте ваши комментарии, напишите, что Вы думаете о произведении, его смысле или главных героях. Укажите что конкретно понравилось, а что нет, и почему Вы так считаете.