Communication Networks and Service Management in the Era of Artificial Intelligence and Machine Learning
Здесь есть возможность читать онлайн «Communication Networks and Service Management in the Era of Artificial Intelligence and Machine Learning» — ознакомительный отрывок электронной книги совершенно бесплатно, а после прочтения отрывка купить полную версию. В некоторых случаях можно слушать аудио, скачать через торрент в формате fb2 и присутствует краткое содержание. Жанр: unrecognised, на английском языке. Описание произведения, (предисловие) а так же отзывы посетителей доступны на портале библиотеки ЛибКат.

- Название:Communication Networks and Service Management in the Era of Artificial Intelligence and Machine Learning
- Автор:
- Жанр:
- Год:неизвестен
- ISBN:нет данных
- Рейтинг книги:3 / 5. Голосов: 1
-
Избранное:Добавить в избранное
- Отзывы:
-
Ваша оценка:
Communication Networks and Service Management in the Era of Artificial Intelligence and Machine Learning: краткое содержание, описание и аннотация
Предлагаем к чтению аннотацию, описание, краткое содержание или предисловие (зависит от того, что написал сам автор книги «Communication Networks and Service Management in the Era of Artificial Intelligence and Machine Learning»). Если вы не нашли необходимую информацию о книге — напишите в комментариях, мы постараемся отыскать её.
a comprehensive overview of the impact of artificial intelligence (AI) and machine learning (ML) on service and network management. Beginning with a fulsome description of ML and AI, the book moves on to discuss management models, architectures, and frameworks. The authors also explore how AI and ML can be used in service management functions like the generation of workload profiles, service provisioning, and more. The book includes a handpicked selection of applications and case studies, as well as a treatment of emerging technologies the authors predict could have a significant impact on network and service management in the future. Statistical analysis and data mining are also discussed, particularly with respect to how they allow for an improvement of the management and security of IT systems and networks. Readers will also enjoy topics like: A thorough introduction to network and service management, machine learning, and artificial intelligence An exploration of artificial intelligence and machine learning for management models, including autonomic management, policy-based management, intent based management, and network virtualization-based management Discussions of AI and ML for architectures and frameworks, including cloud systems, software defined networks, 5G and 6G networks, and Edge/Fog networks An examination of AI and ML for service management, including the automatic generation of workload profiles using unsupervised learning Perfect for information and communications technology educators, Communication Networks and Service Management in the Era of Artificial Intelligence and Machine Learning will also earn a place in the libraries of engineers and professionals who seek a structured reference on how the emergence of artificial intelligence and machine learning techniques is affecting service and network management.
Communication Networks and Service Management in the Era of Artificial Intelligence and Machine Learning — читать онлайн ознакомительный отрывок
Ниже представлен текст книги, разбитый по страницам. Система сохранения места последней прочитанной страницы, позволяет с удобством читать онлайн бесплатно книгу «Communication Networks and Service Management in the Era of Artificial Intelligence and Machine Learning», без необходимости каждый раз заново искать на чём Вы остановились. Поставьте закладку, и сможете в любой момент перейти на страницу, на которой закончили чтение.
Интервал:
Закладка:
2.2.1 Supervised Learning
The goal of supervised learning is to learn a mapping from the input space to the output space where the correct values are provided by labels, called the supervisor. Figure 2.1shows an overview of the supervised learning model. If the output data are real‐valued, then such problems are also called regression. Otherwise, they are called classification, where the learning system fits a model that associates sets of (input) exemplars with labels, possibly with a corresponding measure of certainty. After training with past data, the model learns a classification rule, which may be in the form of an If‐Then‐Else form. Having a rule like this enables us to make predictions if the future is similar to the past. In some cases, we may want to calculate a probability, then the classification becomes learning an association between the input and output data. Learning a rule from data also allows knowledge extraction. In this case, the rule is a simple (complex) model that describes the data and therefore the learning model provides us with an insight about the process underlying the data. Moreover, a learning model also performs compression by fitting a rule to the data. This enables us to use less memory to store the data and less computation to process. Another use of supervised learning is outlier detection. In this case once the rule is learned, we focus on the parts of the data that are not covered by the rule. In other words, we identify the instances that do not follow the rule and/or are exceptions to the rule. These are outliers and imply anomalies requiring further analysis.
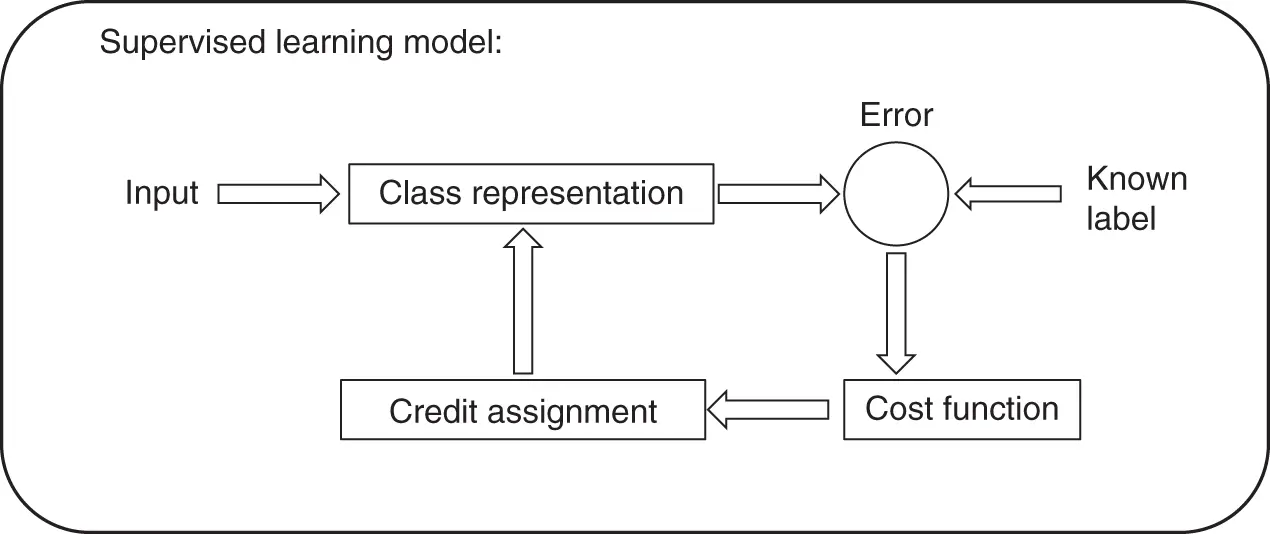
Figure 2.1 Supervised learning model.
2.2.2 Unsupervised Learning
The goal of unsupervised learning is to identify the regularities in the input. The assumption is that there is a structure to the input space such that certain patterns occur more often than others. Figure 2.2shows an overview of the unsupervised learning model. Thus, we aim to identify and differentiate between patterns with different underlying properties. Once this is achieved, we might also be able to distinguish between typical and atypical behaviors. One method to achieve this is clustering. Clustering aims to find groupings of input. This can be used for data exploration to understand the structure of data and/or for data preprocessing where clustering allows us to map data to a new 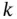 dimensional space, where the new dimensionality can be larger than the original dimensionality of the data. One advantage of unsupervised learning is that it does not required labeled data. Labeling data (obtaining ground‐truth) is costly. Thus, we can use large amounts of unlabeled data for learning the cluster parameters. This is why unsupervised learning is widely used for “anomaly detection” in network and service management [11–13].
dimensional space, where the new dimensionality can be larger than the original dimensionality of the data. One advantage of unsupervised learning is that it does not required labeled data. Labeling data (obtaining ground‐truth) is costly. Thus, we can use large amounts of unlabeled data for learning the cluster parameters. This is why unsupervised learning is widely used for “anomaly detection” in network and service management [11–13].
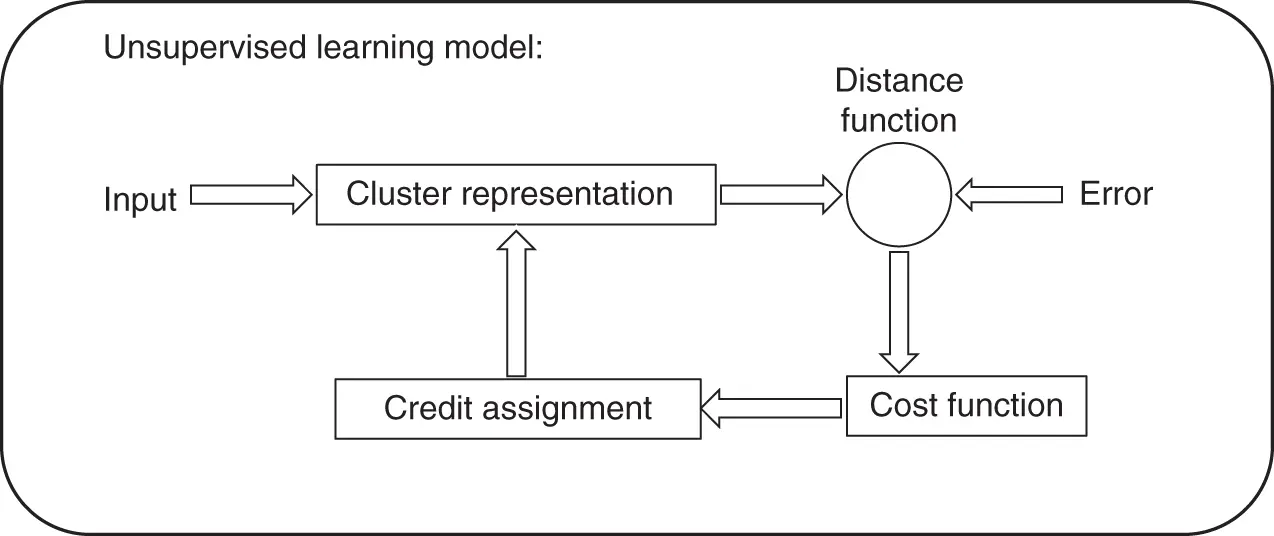
Figure 2.2 Unsupervised learning model.
Figure 2.3 Reinforcement learning model.
2.2.3 Reinforcement Learning
The goal of reinforcement learning is to learn the best sequence of actions (policy) in a given environment to maximize the cumulative reward. Figure 2.3shows an overview of the reinforcement learning model. In this case, reinforcement learning model acts as a decision‐making agent, making actions in an environment and receives rewards/penalties while trying to solve a problem. In reinforcement learning problems, the environment is in a certain state (from a set of possible states) at any given time. The state information may be complete (Markov) or incomplete (non‐Markov). The agent has a set of actions (from a set of possible actions), and when an action is taken, the state of the environment changes. Thus, unlike unsupervised or supervised learning, reinforcement learning explicitly interacts with the “task”. The model is built interactively with the task, not independently from the task. At each time step, a reward signal is typically assumed, where the reward might just be “you have not failed.” Indeed, there might never be any “ultimate reward” other than to maximize the duration between failures, or maximize the number of packets routed. In supervised learning, the data label explicitly tells us what to do. Conversely, reinforcement models might attempt to learn a function describing the relative “value” of being in each state. Decision‐making would then simplify to identifying the action that moved the current state to the next state with most “value.” Reinforcement learning is therefore also explicitly engaged in establishing the order in which it is exposed to state from the task. This is again distinct from either supervised or unsupervised learning in which the data is generally assumed to conform to the independent and identically distributed (i.i.d.) assumption. Moreover, when complete information is available, a reinforcement learning agent may make optimal decisions from the current state alone. 1However, when complete state information is not present, then the reinforcement learning agent would additionally have to develop internal models of state that extend state to previously visited values. Needless to say, this requirement has implications for the representation adopted as well as the process of credit assignment. Reinforcement learning algorithms have a wider spectrum of applications than supervised learning algorithms, however, they might take a longer time to converge given that the feedback is less explicit than with supervised and unsupervised learning. It should be noted here that the application of reinforcement learning in network and service management is developing rapidly and we see more and more impressive results in the field [14–16].
2.3 Learning for Network and Service Management
AI/ML techniques have a vital list of applications in many network and service management tasks, including (but are not limited to) traffic/service classification and prediction for performance management; intrusion, malware identification, and attribution for security management; root cause analysis and fault identification/prediction for fault management; and resource/job allocation/assignment for configuration management. As discussed in Chapter, the growth in connected devices as well as new communication technologies from 5G+ to SDN to NFV persuade network and service management research to explore new methodologies from the AI/ML field [17].
Given the current advances in networks/services AI/ML has found its place in performance management tasks for its ability to learn from big data to predict different conditions, to aggregate patterns, to identify triggers for operations and management actions. For example, traffic prediction has seen multiple ML‐based applications from time series forecasting [18] to neural networks [19, 20] to hidden Markov models [21] to genetic algorithms [22]. Moreover, many other tasks in performance management have employed AI/ML techniques for traffic management in the cloud and mobile edge computing, network resource management and allocation, Quality of Service assurance, and congestion control. These leverage the capabilities of AI/ML techniques to learn from temporal and dynamic data [23–26]. Current examples of such developments include Deep Neural Networks [27], transfer learning [28], Deep Reinforcement Learning [15, 29], and Stream online learning [30].
Читать дальшеИнтервал:
Закладка:
Похожие книги на «Communication Networks and Service Management in the Era of Artificial Intelligence and Machine Learning»
Представляем Вашему вниманию похожие книги на «Communication Networks and Service Management in the Era of Artificial Intelligence and Machine Learning» списком для выбора. Мы отобрали схожую по названию и смыслу литературу в надежде предоставить читателям больше вариантов отыскать новые, интересные, ещё непрочитанные произведения.












Обсуждение, отзывы о книге «Communication Networks and Service Management in the Era of Artificial Intelligence and Machine Learning» и просто собственные мнения читателей. Оставьте ваши комментарии, напишите, что Вы думаете о произведении, его смысле или главных героях. Укажите что конкретно понравилось, а что нет, и почему Вы так считаете.