Semantic Web for Effective Healthcare Systems
Здесь есть возможность читать онлайн «Semantic Web for Effective Healthcare Systems» — ознакомительный отрывок электронной книги совершенно бесплатно, а после прочтения отрывка купить полную версию. В некоторых случаях можно слушать аудио, скачать через торрент в формате fb2 и присутствует краткое содержание. Жанр: unrecognised, на английском языке. Описание произведения, (предисловие) а так же отзывы посетителей доступны на портале библиотеки ЛибКат.

- Название:Semantic Web for Effective Healthcare Systems
- Автор:
- Жанр:
- Год:неизвестен
- ISBN:нет данных
- Рейтинг книги:4 / 5. Голосов: 1
-
Избранное:Добавить в избранное
- Отзывы:
-
Ваша оценка:
Semantic Web for Effective Healthcare Systems: краткое содержание, описание и аннотация
Предлагаем к чтению аннотацию, описание, краткое содержание или предисловие (зависит от того, что написал сам автор книги «Semantic Web for Effective Healthcare Systems»). Если вы не нашли необходимую информацию о книге — напишите в комментариях, мы постараемся отыскать её.
The aim of this book is to analyze the current status on how Semantic Web is used to solve the health data integration and interoperability problem, how it provides advanced data linking capabilities that can improve search and retrieval of medical data. There are chapters in the book which analyze the tools and approaches to semantic health data analysis and knowledge discovery. The book discusses the role of semantic technologies in extracting and transforming healthcare data before storing it in repositories. It also discusses different approaches for integrating heterogeneous healthcare data. To summarize, the book will help readers understand key concepts in semantic web applications for biomedical engineering and healthcare.
Semantic Web for Effective Healthcare Systems — читать онлайн ознакомительный отрывок
Ниже представлен текст книги, разбитый по страницам. Система сохранения места последней прочитанной страницы, позволяет с удобством читать онлайн бесплатно книгу «Semantic Web for Effective Healthcare Systems», без необходимости каждый раз заново искать на чём Вы остановились. Поставьте закладку, и сможете в любой момент перейти на страницу, на которой закончили чтение.
Интервал:
Закладка:
- Chapter 12provides information on rare diseases and explores the relationship between rare diseases, diagnoses, and information retrieval. In particular, it illustrates the history, characteristics, types, and classification along with databases of rare disease information. It also explores the challenges faced by researchers in rare disease information retrieval and how they can be resolved by search query optimization.
- Chapter 13reviews the recent advances in medical terminology tools and application strategies currently in use for semantic reasoning and interoperability in healthcare. Common terminology standards used in health information and technology, such as SNOMED CT, RxNorm, LOINC, ICD-x-CM, and UCUM, are discussed. Also discussed are the current reference terminology mapping solutions that enable semantic interoperability of data between health systems.
- Chapter 14builds upon the existing AI-based model in order to discover a new model to improve healthcare facilities for the faster recovery of COVID-19 patients. The chapter discusses different AI-related solutions for the healthcare industry.
In conclusion, we are grateful to all those who directly and indirectly contributed to this book. We are also grateful to the publisher for giving us the opportunity to publish it.
Vishal Jain Jyotir Moy Chatterjee Ankita Bansal Abha JainSeptember 2021
Acknowledgment
I would like to acknowledge the most important people in my life—my late grandfather Shri Gopal Chatterjee, my late grandmother Smt. Subhankori Chatterjee, my late mother Nomita Chatterjee, my uncle Shri. Moni Moy Chatterjee, and my father Shri. Aloke Moy Chatterjee. The book has been my long-cherished dream, which would not have become a reality without the support and love of these amazing people. They continued to encourage me despite my failing to give them the proper time and attention. I am also grateful to my friends, who have encouraged and blessed this work with their unconditional love and patience.
Jyotir Moy ChatterjeeDepartment of IT Lord Buddha Education Foundation (Asia Pacific University of Technology & Innovation) Kathmandu, Nepal
1
An Ontology-Based Contextual Data Modeling for Process Improvement in Healthcare
A. M. Abirami1* and A. Askarunisa2
1Department of Information Technology, Thiagarajar College of Engineering, Madurai, Tamil Nadu, India
2Department of Computer Science and Engineering, KLN College of Information Technology, Madurai, Tamil Nadu, India
Abstract
The internet world contains large volume of text data. The integration of web sources is required to derive needed information. Human annotation is much difficult and tedious. Automated processing is necessary to make these data readable by machines. But mostly they are available in unstructured format, and they need to be formatted into structured form. Structured information is retrieved from unstructured or semi-structured text which is defined as text analytics. There are many Information Extraction (IE) techniques available to model the documents (product/service reviews). Vector space model uses only the content but not the contextual representation. This complexity is resolved by Semantic web, the initiative of WWW Consortium. The advantage of the use of Semantic web enables the ease of communication between Businesses and in process improvement.
Keywords:Ontology, semantic-web, decision making, healthcare, service, reviews
1.1 Introduction
Text analysis is defined as deriving structured data from unstructured text. Additional information like customer insight about the product or service can be retrieved from the unstructured data sources using text analytics techniques. Its techniques have different applications such as insurance claims assessment, competitor analysis, sentiment analysis and the like. Many industries use text analytics for their business improvement. Social media impacts different industries like product business [1, 2], tourism [3, 4], and healthcare service [5] with the tremendous changes in the recent past years.
Retrieving and summarizing web data, which are dispersed in different web pages, are difficult and complex processes; also, they consume most of the manual effort and time. No standard data model exists for web documents. This increases the necessity of annotating the huge number of text documents that exist in the World Wide Web (WWW). Extracting and collating the information from these text is a complex task. Unlike numerical dataset, text documents contain more number of features. The amount of resources required to represent big dataset may be improved by representing the text documents with most needed and non-redundant features. Classification or clustering algorithms may be used for identifying the features from the text documents. The documents are analyzed, modeled and then used in the process of business improvement or for personal interest. Thus, the annotated text improves automated decision-making process, which in turn reduces the manual effort and time required for text analysis.
The report from British Columbia Safety and Quality Council says when patients and healthcare service entities are engaged in online platform, then there would be greater improvement in offering healthcare services. Improvement in healthcare services is visible when insights from the experience of patients are analyzed [5]. Hence, it becomes necessary to consolidate the opinions from the customers or clients so as to improve business, decision-making and increase revenue. Figure 1.1gives the overview of decision-making process from the online product/service reviews, using different information extraction and text analysis techniques.
There exist many challenges while analyzing the social media text or user-generated content. In languages like English, the same word has multiple meaning (polysemy), and different words have same meaning (synonymy). People show “variety” and use heterogeneous words while expressing their views. It often leads to complication in processing the textual data. Most of the feature extraction techniques do not consider the semantic relationships between the terms. Subjectivity that exists in text processing techniques adds complexity to the process, which in turn impacts the evaluation of results. Also, the rare availability of gold-standard or annotated text data for different domains add more challenges to text analysis [6]. Hence, the identification and application of suitable Natural Language Processing (NLP) techniques are the main research focus in text data analysis.
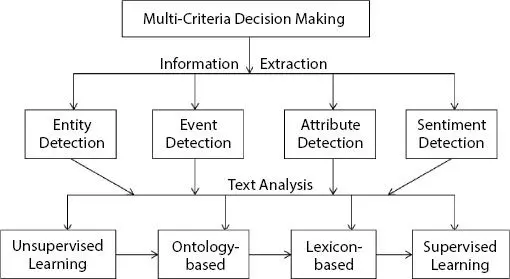
Figure 1.1 Decision-making process from social media reviews.
Text analytics supports the context matching between the reader and the writer. This challenge can be managed if different vocabularies of features and their relationship are well represented in the data model. For example, content based contextual user feedback analysis enables the users to buy new products or avail any service by highlighting the best features of products or services. Challenges and issues in information retrieval problems are overcome if Ontology representation and topic modelling techniques are used for modeling the text documents. The chapter focuses on extracting relevant features from the set of documents and building domain ontology for them. The Ontology helps in building the predictive or sentiment analysis model by using suitable information retrieval (IR) techniques and contextual representation of data, so as to enable automated decision-making process, before buying a new product or availing a new service, as shown in Figure 1.2.
Читать дальшеИнтервал:
Закладка:
Похожие книги на «Semantic Web for Effective Healthcare Systems»
Представляем Вашему вниманию похожие книги на «Semantic Web for Effective Healthcare Systems» списком для выбора. Мы отобрали схожую по названию и смыслу литературу в надежде предоставить читателям больше вариантов отыскать новые, интересные, ещё непрочитанные произведения.












Обсуждение, отзывы о книге «Semantic Web for Effective Healthcare Systems» и просто собственные мнения читателей. Оставьте ваши комментарии, напишите, что Вы думаете о произведении, его смысле или главных героях. Укажите что конкретно понравилось, а что нет, и почему Вы так считаете.