Борис Крук - ...И мир загадочный за занавесом цифр. Цифровая связь
Здесь есть возможность читать онлайн «Борис Крук - ...И мир загадочный за занавесом цифр. Цифровая связь» весь текст электронной книги совершенно бесплатно (целиком полную версию без сокращений). В некоторых случаях можно слушать аудио, скачать через торрент в формате fb2 и присутствует краткое содержание. Город: Москва, Год выпуска: 2004, ISBN: 2004, Издательство: Горячая линия-Телеком, Жанр: sci_radio, Прочая научная литература, на русском языке. Описание произведения, (предисловие) а так же отзывы посетителей доступны на портале библиотеки ЛибКат.

- Название:...И мир загадочный за занавесом цифр. Цифровая связь
- Автор:
- Издательство:Горячая линия-Телеком
- Жанр:
- Год:2004
- Город:Москва
- ISBN:5-93517-168-6
- Рейтинг книги:4 / 5. Голосов: 1
-
Избранное:Добавить в избранное
- Отзывы:
-
Ваша оценка:
...И мир загадочный за занавесом цифр. Цифровая связь: краткое содержание, описание и аннотация
Предлагаем к чтению аннотацию, описание, краткое содержание или предисловие (зависит от того, что написал сам автор книги «...И мир загадочный за занавесом цифр. Цифровая связь»). Если вы не нашли необходимую информацию о книге — напишите в комментариях, мы постараемся отыскать её.
Для любознательных читателей, для молодежи, выбирающей профессию, и всех, кто интересуется современными телекоммуникациями, будет полезна студентам высших и средних учебных, заведений.
...И мир загадочный за занавесом цифр. Цифровая связь — читать онлайн бесплатно полную книгу (весь текст) целиком
Ниже представлен текст книги, разбитый по страницам. Система сохранения места последней прочитанной страницы, позволяет с удобством читать онлайн бесплатно книгу «...И мир загадочный за занавесом цифр. Цифровая связь», без необходимости каждый раз заново искать на чём Вы остановились. Поставьте закладку, и сможете в любой момент перейти на страницу, на которой закончили чтение.
Интервал:
Закладка:
Добавим, что по образцу существующих "электронных библиотек" созданы "электронные музеи" — собрания "электронных копий" всех известных мировых шедевров живописи. Любой желающий может с помощью персонального компьютера "получить" на экране дисплея или обычного домашнего телевизора свой "заказ".
Итак, перед нами две тайны портрета Моны Лизы: создание оригинала флорентийским мастером Леонардо да Винчи и "электронной копии" американской исследовательницей Лиллиан Шварц. В этой книге мы будет разгадывать вторую, не менее увлекательную тайну волшебного превращения портрета в электрические импульсы двоичного алфавита.
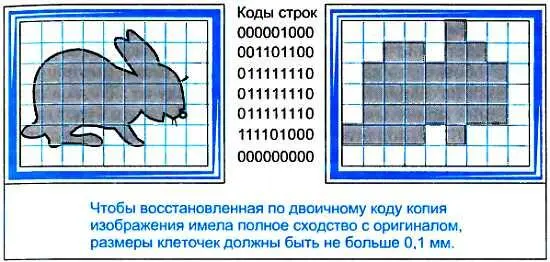
Сначала рассмотрим простой рисунок. Поступим так, как поступают начинающие художники, когда им нужно сделать копию с картины: разобьем ее на клетки. Чем меньше размер клеток, тем легче делать копию. После этого можно приступить непосредственно к двоичному кодированию картины. Условимся обозначать каждую клетку 0, если более половины ее площади не закрашено, и 1 в противном случае. Тогда в соответствии с принятым правилом код первой строки будет иметь вид 000001000, код второй строки — 001101100 и т. д., а двоичный код всей картины, записанный в виде последовательности кодов остальных строк, —
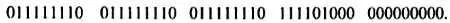
(С равным правом можно применить и "обратный" код, т. е. незакрашенному полю ставить 1, закрашенному — 0.)
Эту двоичную информацию — с виду она ничем не отличается от закодированной текстовой или речевой информации — можно записать в электронную память или передать на расстояние подобно тому, как передается двоичный код телеграмм. Правда, восстановленная по данной последовательности 0 и 1 картина будет отличаться от исходной. Однако если разбить изображение на достаточно большое число клеток (взяв, например, ширину клетки 0,5 мм или еще меньше), то можно добиться полного, как говорится, один к одному, сходства восстановленного изображения с оригиналом. Конечно, в этом случае двоичный код картины нам придется записывать на бумаге гораздо дольше: ведь он будет содержать в 50-100 раз большее число 0 и 1. Для того чтобы поместить в микросхему изображение размером всего лишь со спичечный коробок (4x5 см), объем ее памяти при ширине клеточки 0,5 мм должен составлять 8000 бит, а при ширине клеточки 0,1 мм — уже 200000 бит. Таким образом, более точное описание изображения требует больших информационных затрат. За качество, как всегда, приходится платить.
Обратите внимание, закодировать нашу картину двоичным кодом было весьма просто, поскольку мы имели дело с изображением, состоящим всего из двух цветовых градаций: поле каждой клеточки было условлено считать либо белым (0), либо закрашенным (1). А как быть с фотографией? Ну хотя бы с той, которую называем черно-белой. Ведь на ней вопреки названию имеются плавные переходы от белого цвета к черному. Как определить степень "яркости" той или иной клеточки? Дело осложняется еще и тем, что при разбиении фотографии на клеточки может оказаться, что яркость изображения даже внутри одной клеточки будет неодинаковой. Очевидно, чем меньше размеры клеточки, тем более однородной будет ее яркость. Если в клеточке размером 1 мм 2нарисовать пять черных линий (есть умельцы, которые умудряются на рисовом зернышке разместить целое стихотворение), то человеческий глаз легко их различит. Если же таких линий больше, скажем десять, то глаз не сможет их различить: все они сольются воедино и клеточка будет казаться однотонной. Это свойство глаза — различать определенное число линий на 1 мм — называется его разрешающей способностью. Ученые установили, что разрешающая способность человеческого глаза у разных людей колеблется от 5 до 10 линий на 1 мм. Это означает, что для фотографических изображений размер клеточки должен быть не больше 0,1х0,1 мм, т. е. на 1 мм 2изображения должно поместиться как минимум 100 таких клеточек. Только тогда можно считать яркость внутри клеточки всюду одинаковой.
— Но ведь на такого же размера клеточки мы разбивали и изображение, состоящее всего из двух тонов! — воскликнет наблюдательный читатель.
Правильно. Никакого особого отличия в разложении на отдельные элементы (клеточки) этих двух типов изображений нет. Разница заключается в другом. В первом случае было только две градации яркости (помните, поле либо белое, либо закрашенное?). Это и позволило нам сразу же применить двоичный алфавит: 0 и 1. Во втором же случае мы имеем дело с непрерывной шкалой изменения яркостей элементов изображения (от белого цвета до черного).
Читать дальшеИнтервал:
Закладка:
Похожие книги на «...И мир загадочный за занавесом цифр. Цифровая связь»
Представляем Вашему вниманию похожие книги на «...И мир загадочный за занавесом цифр. Цифровая связь» списком для выбора. Мы отобрали схожую по названию и смыслу литературу в надежде предоставить читателям больше вариантов отыскать новые, интересные, ещё непрочитанные произведения.












Обсуждение, отзывы о книге «...И мир загадочный за занавесом цифр. Цифровая связь» и просто собственные мнения читателей. Оставьте ваши комментарии, напишите, что Вы думаете о произведении, его смысле или главных героях. Укажите что конкретно понравилось, а что нет, и почему Вы так считаете.