Татьяна Ушакова - Рождение слова. Проблемы психологии речи и психолингвистики
Здесь есть возможность читать онлайн «Татьяна Ушакова - Рождение слова. Проблемы психологии речи и психолингвистики» — ознакомительный отрывок электронной книги совершенно бесплатно, а после прочтения отрывка купить полную версию. В некоторых случаях можно слушать аудио, скачать через торрент в формате fb2 и присутствует краткое содержание. Город: Москва, Год выпуска: 2011, ISBN: 2011, Жанр: psy_generic, на русском языке. Описание произведения, (предисловие) а так же отзывы посетителей доступны на портале библиотеки ЛибКат.

- Название:Рождение слова. Проблемы психологии речи и психолингвистики
- Автор:
- Жанр:
- Год:2011
- Город:Москва
- ISBN:978-5-9270-0206-1
- Рейтинг книги:3 / 5. Голосов: 1
-
Избранное:Добавить в избранное
- Отзывы:
-
Ваша оценка:
Рождение слова. Проблемы психологии речи и психолингвистики: краткое содержание, описание и аннотация
Предлагаем к чтению аннотацию, описание, краткое содержание или предисловие (зависит от того, что написал сам автор книги «Рождение слова. Проблемы психологии речи и психолингвистики»). Если вы не нашли необходимую информацию о книге — напишите в комментариях, мы постараемся отыскать её.
. Обозначен системный характер рассматриваемой области, объединяющей психологический, лингвистический, психофизиологический, когнитивистский и др. аспекты. Характеризуются принципы исследований по изучению механизмов языка и речи. Большое значение придано теме вербальной семантики. Ряд вопросов прояснен с помощью анализа онтогенеза речи и языка.
В формате a4.pdf сохранен издательский макет.
Рождение слова. Проблемы психологии речи и психолингвистики — читать онлайн ознакомительный отрывок
Ниже представлен текст книги, разбитый по страницам. Система сохранения места последней прочитанной страницы, позволяет с удобством читать онлайн бесплатно книгу «Рождение слова. Проблемы психологии речи и психолингвистики», без необходимости каждый раз заново искать на чём Вы остановились. Поставьте закладку, и сможете в любой момент перейти на страницу, на которой закончили чтение.
Интервал:
Закладка:
Несмотря на сложность теоретических моделей, исследователи стремятся к тому, чтобы они могли быть реализованы с помощью компьютерной программы. «Симуляция» (по существующей терминологии) модели на компьютере – важная черта современных когнитивистских разработок. Развитию исследований в этом направлении по ряду причин придается большое значение. Компьютерное моделирование становится формой критической проверки предлагаемых теорий, а также служит разработке того пути, на котором в будущем станет возможной имитация тех или других психических функций (и, соответственно, видов умственного труда) на электронно-вычислительной технике.
Условно можно различать два вида когнитивных моделей. Одни из них ориентированы на представление структур, т. е. относительно стабильных функциональных образований, работающих при действии рассматриваемой функции. Другие описывают процессы, протекающие с включением этих структур. Так, например, модель может описывать структуру «вербальных сетей», организация которых обеспечивает функционирование ассоциаций. Другого вида модель концентрируется на закономерностях процесса протекания вербальных ассоциаций, выражаемого в соответствующей модели.
Вообще же различие понятий структур и процессов довольно условное, если объектом анализа являются психические функции. Так, например, та же структура «вербальной сети» устанавливается в результате процесса выработки ассоциаций. Согласно идее Я. А. Пономарева, высказанной применительно к теории мышления, возможен переход этапов развития мышления в структурные уровни умственного механизма, а тех, в свою очередь, – в ступени процесса решения задач (Пономарев, 1983). При связанности понятий структур и процессов их разделение в процессе разработки когнитивистских моделей оказывается, тем не менее, довольно удобным, позволяя несколько упростить описание. Ниже будет представлено несколько современных моделей обоих видов, описывающих вербальную действительность.
Одна из широко известных в современной психолингвистике моделей вербального процесса была разработана В. Кинчем и Т. ван Дейком в конце 1970-х – начале 1980-х годов. В ней представлена обработка процесса понимания текста, что показано на рисунке 2.1.
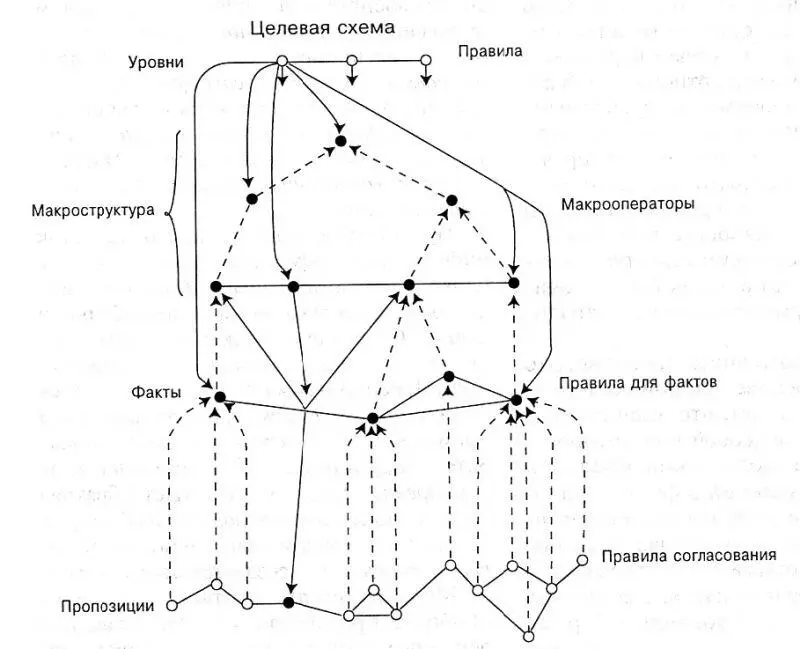
Рис. 2.1. Модель обработки и понимания текста (В. Кинч и Т. ван Дейк)
Главная идея и задача модели состоит в том, что человек, понимая текст, производит его смысловую переработку и выделяет существенную информацию, опуская детали. В норме понимание текста не представляет его буквальное и дословное запечатление. Направленность модели состоит в том, чтобы с использованием точных и по возможности формализованных процедур показать, как происходит эта переработка, приводящая к вычленению и сохранению существенной информации (соответствующей у человека пониманию). Содержание модели заключается в описании используемых процедур, не все они, однако, формализованы. Эти процедуры достаточно сложны и специфичны. Охарактеризуем здесь их общий смысл.
Предполагается, что обработка текста происходит на нескольких горизонтально показанных уровнях, обозначенных на рисунке слева, справа – применяемые к ним операции. Нижний из них – это сам текст, представленный в виде пропозиций; затем располагается описываемый в тексте уровень фактов; следующий уровень – макроструктуры текста, на вершине расположен уровень целевой схемы. На первом уровне обработки происходит трансформация текста в ряд пропозиций. Это делается для того, чтобы выявить семантические отношения слов и «отсечь» грамматическую форму. Пропозиции имеют структуру: предикат-субъект-объект (например, «открыла – Кюри – радий»). На основе пропозициональной формы текстового материала с помощью определяемых в модели операций строится семантическая сеть, отражающая отношения между пропозициями. В сетях показаны причинные, временные, пространственные отношения между объектами. Сети оказываются все более сложными по мере того, как анализируемый текст наращивает сложность описываемых отношений. В результате объем информации превосходит возможности оперативной памяти. При этом включается целевая схема, которая в соответствии с заданными «ожиданиями» и при включении долговременной памяти производит отбор наиболее релевантной информации и формирует структуру «конденсата» информации – как бы заключительную репрезентацию «смысла» анализируемого текста.
Читать дальшеИнтервал:
Закладка:
Похожие книги на «Рождение слова. Проблемы психологии речи и психолингвистики»
Представляем Вашему вниманию похожие книги на «Рождение слова. Проблемы психологии речи и психолингвистики» списком для выбора. Мы отобрали схожую по названию и смыслу литературу в надежде предоставить читателям больше вариантов отыскать новые, интересные, ещё непрочитанные произведения.












Обсуждение, отзывы о книге «Рождение слова. Проблемы психологии речи и психолингвистики» и просто собственные мнения читателей. Оставьте ваши комментарии, напишите, что Вы думаете о произведении, его смысле или главных героях. Укажите что конкретно понравилось, а что нет, и почему Вы так считаете.