Чарльз Петцольд - Код. Тайный язык информатики
Здесь есть возможность читать онлайн «Чарльз Петцольд - Код. Тайный язык информатики» — ознакомительный отрывок электронной книги совершенно бесплатно, а после прочтения отрывка купить полную версию. В некоторых случаях можно слушать аудио, скачать через торрент в формате fb2 и присутствует краткое содержание. Город: Москва, Год выпуска: 2019, ISBN: 2019, Издательство: Манн, Иванов и Фербер, Жанр: Прочая научная литература, Программирование, Прочая околокомпьтерная литература, на русском языке. Описание произведения, (предисловие) а так же отзывы посетителей доступны на портале библиотеки ЛибКат.
- Название:Код. Тайный язык информатики
- Автор:
- Издательство:Манн, Иванов и Фербер
- Жанр:
- Год:2019
- Город:Москва
- ISBN:978-5-00117-545-2
- Рейтинг книги:3.33 / 5. Голосов: 6
-
Избранное:Добавить в избранное
- Отзывы:
-
Ваша оценка:
Код. Тайный язык информатики: краткое содержание, описание и аннотация
Предлагаем к чтению аннотацию, описание, краткое содержание или предисловие (зависит от того, что написал сам автор книги «Код. Тайный язык информатики»). Если вы не нашли необходимую информацию о книге — напишите в комментариях, мы постараемся отыскать её.
Код. Тайный язык информатики — читать онлайн ознакомительный отрывок
Ниже представлен текст книги, разбитый по страницам. Система сохранения места последней прочитанной страницы, позволяет с удобством читать онлайн бесплатно книгу «Код. Тайный язык информатики», без необходимости каждый раз заново искать на чём Вы остановились. Поставьте закладку, и сможете в любой момент перейти на страницу, на которой закончили чтение.
Интервал:
Закладка:
В период разработки системы ASCII потребностям некоторых других стран уделяли внимание, хотя нелатинские алфавиты при этом особо не учитывались. Согласно опубликованному стандарту ASCII, десять его кодов (40h, 5Bh, 5Ch, 5Dh, 5Eh, 60h, 7Bh, 7Ch, 7Dh и 7Eh) можно переопределить в соответствии с национальными потребностями. Кроме того, при необходимости символ решетки (#) можно заменить символом британского фунта (£), а символ доллара ($) — обобщенным для валюты символом (¤). Очевидно, что замена символов имеет смысл только тогда, когда все пользователи конкретного текстового документа, содержащего эти переопределенные коды, знают об этом изменении.
Поскольку многие компьютерные системы хранят символы в виде 8-битных значений, можно расширить их набор со 128 до 256. В таком наборе коды с 00h по 7Fh определяются так же, как и в обычной системе ASCII, а коды с 80h по FFh могут представлять что-то совершенно иное. Этот метод использовался для определения дополнительных кодов для букв с диакритическими значками и нелатинских алфавитов. В качестве примера приведу набор кодов для букв кириллицы. В представленной таблице старшая тетрада шестнадцатеричного кода символа указана в верхней строке, а младшая — в левом столбце.
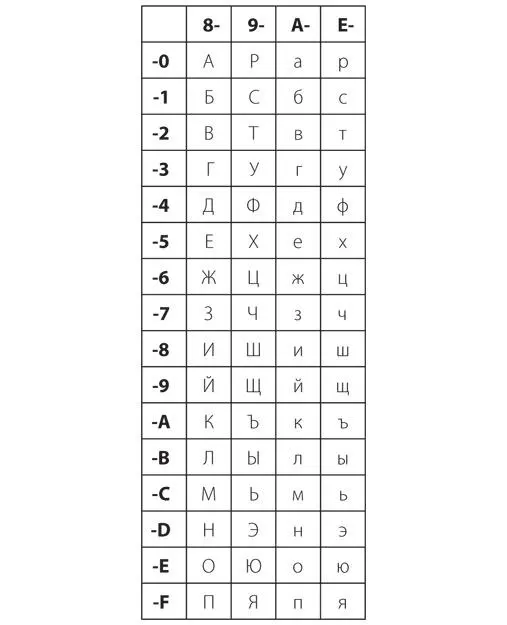
Символом кода A0h назначен неразрывный пробел. Обычно когда компьютерная программа форматирует текст в строки и абзацы, то разрыв строки равен пробелу, код ASCII которого 20h. Код A0h должен отображаться как пробел, но не может использоваться для разрыва строк. Неразрывный пробел может понадобиться, например, в фразе «WW II». Символ кода ADh — мягкий перенос. Его используют для разделения гласных в середине слова. На печатаемой странице он появляется, только когда необходимо перенести слово с одной строки на другую.
К сожалению, за минувшие десятилетия было создано много разных расширений кодировки ASCII, что привело к большой путанице и негативно отразилось на совместимости. Набор ASCII был расширен более радикальным образом для кодирования идеограмм китайского, японского и корейского языков. В одной популярной кодировке под названием Shift-JIS (Japan Industrial Standard — японский промышленный стандарт) коды с 81h по 9Fh фактически представляют первый байт двухбайтового кода символа. Таким образом, система Shift-JIS позволяет кодировать около 6000 дополнительных символов. К сожалению, Shift-JIS — не единственная система, которая использует такой подход. В Азии широко распространены еще три стандартных набора двухбайтовых символов (Double-byte character sets, DBCS).
Существование нескольких несовместимых наборов двухбайтовых символов — лишь одна из проблем. Печально, что некоторые символы, в частности обычные символы ASCII, представлены однобайтовыми кодами, а тысячи идеограмм — 2-байтовыми. Это затрудняет работу с такими наборами.
Считая предпочтительным наличие единой однозначной системы кодирования символов, подходящей для всех языков мира, в 1988 году несколько крупных компьютерных компаний объединились для разработки альтернативы ASCII, получившей название Unicode. В отличие от 7-битного кода ASCII, Unicode — 16-битный. Для каждого символа в кодировке Unicode требуется два байта. Значит, Unicode предусматривает коды символов от 0000h до FFFFh, то есть может представлять 65 536 различных символов. Этого достаточно для охвата всех языков мира, которые с большой долей вероятности будут использоваться в компьютерной индустрии, даже с возможностью расширения.
Кодировка Unicode создавалась не с нуля. Первые 128 символов Unicode, коды которых находятся в диапазоне от 0000h до 007Fh, соответствуют тем же символам в системе ASCII. Кроме того, коды Unicode с 00A0h по 00FFh — это коды описанного выше расширения ASCII для латинского алфавита Latin Alphabet No 1. В Unicode также включены другие мировые стандарты.
Несмотря на то что Unicode — очевидное улучшение систем кодировки, это не гарантирует его мгновенного принятия. Система ASCII и множество несовершенных расширений настолько укоренились в мире компьютерных технологий, что вытеснить их будет сложно.
Единственная настоящая проблема системы Unicode в том, что она делает недействительным прежнее соответствие между одним текстовым символом и одним байтом памяти. Закодированный с помощью стандарта ASCII роман «Гроздья гнева» занимает один мегабайт, а в кодировке Unicode — два мегабайта. Однако это небольшая плата за универсальную и однозначную систему кодирования.
Читать дальшеИнтервал:
Закладка:
Похожие книги на «Код. Тайный язык информатики»
Представляем Вашему вниманию похожие книги на «Код. Тайный язык информатики» списком для выбора. Мы отобрали схожую по названию и смыслу литературу в надежде предоставить читателям больше вариантов отыскать новые, интересные, ещё непрочитанные произведения.












Обсуждение, отзывы о книге «Код. Тайный язык информатики» и просто собственные мнения читателей. Оставьте ваши комментарии, напишите, что Вы думаете о произведении, его смысле или главных героях. Укажите что конкретно понравилось, а что нет, и почему Вы так считаете.