Олег Андреев - Учитесь быстро читать
Здесь есть возможность читать онлайн «Олег Андреев - Учитесь быстро читать» весь текст электронной книги совершенно бесплатно (целиком полную версию без сокращений). В некоторых случаях можно слушать аудио, скачать через торрент в формате fb2 и присутствует краткое содержание. Город: Москва, Год выпуска: 1991, ISBN: 1991, Издательство: Просвещение, Жанр: Прочая научная литература, на русском языке. Описание произведения, (предисловие) а так же отзывы посетителей доступны на портале библиотеки ЛибКат.

- Название:Учитесь быстро читать
- Автор:
- Издательство:Просвещение
- Жанр:
- Год:1991
- Город:Москва
- ISBN:5-09-001867-7
- Рейтинг книги:4 / 5. Голосов: 1
-
Избранное:Добавить в избранное
- Отзывы:
-
Ваша оценка:
Учитесь быстро читать: краткое содержание, описание и аннотация
Предлагаем к чтению аннотацию, описание, краткое содержание или предисловие (зависит от того, что написал сам автор книги «Учитесь быстро читать»). Если вы не нашли необходимую информацию о книге — напишите в комментариях, мы постараемся отыскать её.
Учитесь быстро читать — читать онлайн бесплатно полную книгу (весь текст) целиком
Ниже представлен текст книги, разбитый по страницам. Система сохранения места последней прочитанной страницы, позволяет с удобством читать онлайн бесплатно книгу «Учитесь быстро читать», без необходимости каждый раз заново искать на чём Вы остановились. Поставьте закладку, и сможете в любой момент перейти на страницу, на которой закончили чтение.
Интервал:
Закладка:
Блоки алгоритма составляют основу логико-семантического анализа текста, который наш мозг выполняет в процессе чтения в значительной степени подсознательно. Есть основания полагать, что эффективность такого анализа у большинства читателей не всегда высока. В самом деле, знание определенной программы еще не означает умение ею пользоваться. Умение пользоваться определенной программой еще не означает возможность ее применения на уровне автоматизированного, неосознаваемого действия-навыка. Задача заключается в том, чтобы образовать именно навык, т. е. доведенное до автоматизма умение грамотно и глубоко анализировать текст в режиме быстрого чтения. Поэтапное формирование навыка и предполагает детальный разбор каждого уровня мыслительных операций при чтении текста с целью выявления его основного смыслового значения — доминанты. Эту задачу и решает дифференциальный алгоритм чтения. Он предлагает в процессе чтения в соответствии с блоками алгоритма производить логико-семантический анализ текста: вначале выделить ключевые слова, затем построить смысловые ряды и, наконец, выделив цепь значений, сформировать доминанту. Цель такого упражнения — показать мозгу, как правильно надо понимать текст. Именно так, и только так можно увидеть главное, действительно важное, проникнуть в суть вещей, явлений, излагаемых автором. Многократное повторение упражнения формирует новый способ кодирования, обеспечивающий затем высококачественное понимание текста в режиме быстрого чтения.
Теперь потренируемся: проведем медленное чтение текста, размечая его в соответствии с блоками дифференциального алгоритма чтения. Посмотрим на примере, как используется дифференциальный алгоритм.
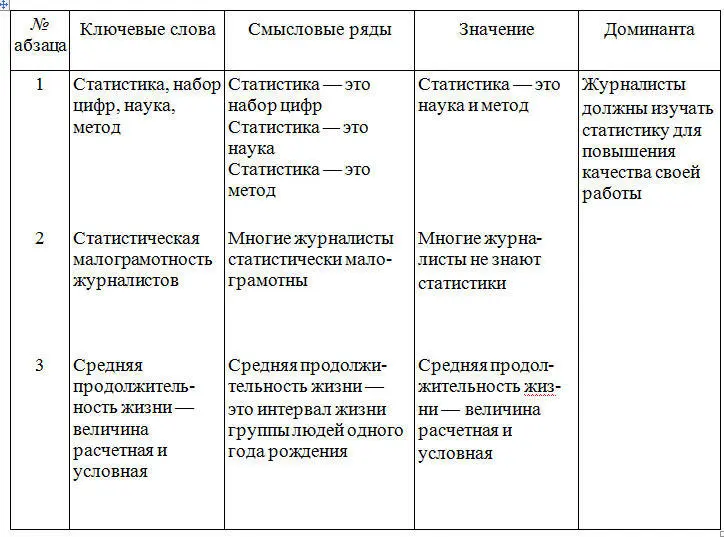
Наш век не без основания называют веком статистики. Статистика — слово многозначное. Это и набор цифр, полученных определенным образом и характеризующих некоторые явления, и специальная социально-экономическая наука, и научный метод широко применяемый как в общественных, так и в естественных науках.
В журналистской работе ко многим темам без статистики совершенно невозможно подойти. В частности, все, относящееся к вопросам народонаселения, прямо-таки основано на статистике. Относительная редкость статей на демографические темы (при громадном интересе к ним и читателей, и общественной важности этих тем) в немалой мере объясняется статистической малограмотностью многих журналистов. Очень часто смысл цифр читателям непонятен. Один пример. Кто не слышал и неупотреблял слов «средняя продолжительность жизни»? Для подавляющего большинства значение их таково: это средний возраст смерти в данное время. Однако истинный смысл их совсем иной: это средняя продолжительность жизни тех, кто родился в данном году, при условии, что на всем протяжении жизни данного поколения возрастные коэффициенты смертности будут такими же, как и в год рождения. Таким образом, эти величина расчетная и условная..
В этом отрывке подчеркнуты ключевые слова. Порядок обработки абзацев этого текста по алгоритму показан в табл. 4.
Нужно иметь в виду, что, выполняя упражнения в соответствии с блоками дифференциального алгоритма, мы тренируем мыслительные процессы как бы расчлененно — замедленно и по частям. При чтении они, разумеется, протекают иначе — быстро, одновременно и в значительной мере подсознательно. Но чтобы навык такого чтения стал автоматизированным и мгновенным, тренировать его нужно дифференцированно.
Размечая текст по блокам алгоритма, мы с карандашом в руках прочитываем его три раза. При первом чтении подчеркиваем только ключевые слова. Как видно из приведенного выше примера, не все слова текста являются ключевыми, а только те из них, которые будут использованы для последующих построений. Второе чтение используем для построения смысловых рядов: удобно записывать их на отдельном листочке. И наконец, читая текст, а точнее, смысловые ряды, в третий раз формируем значения, из которых складывается затем доминанта. Здесь любопытно провести некоторую аналогию с рекомендациями, которые давали просветители прошлого века для чтения. Так, русский поэт XVIII в. Я. Княжнин советовал: «Читается трояким образом: первое — читать и не понимать; второе — читать и понимать; третье — читать и понимать даже то, что не написано». Формируя доминанту, мы как раз и решаем задачу поиска именно того, что, как говорят, содержится между строк. Иногда говорят: «приценись», прежде чем читать все подряд. Да, именно так, ведь вы присматриваетесь, прицениваетесь, прежде чем купить что-то. Другими словами, предварительно знакомитесь, составляете себе предварительное представление. Тот же самый прием вы применяете к статье или книге, когда ее «покупаете», т. е. собираетесь прочитать. Выполняя упражнения, рекомендуемые ниже, вы убедитесь также, что избыточность текста — вполне реальное, осязаемое явление. Действительно, из всего многообразия слов текста после его графической произвольной разметки в соответствии с алгоритмом остается очень небольшая часть — «сухой остаток», который и составляет основное смысловое содержание.
Читать дальшеИнтервал:
Закладка:
Похожие книги на «Учитесь быстро читать»
Представляем Вашему вниманию похожие книги на «Учитесь быстро читать» списком для выбора. Мы отобрали схожую по названию и смыслу литературу в надежде предоставить читателям больше вариантов отыскать новые, интересные, ещё непрочитанные произведения.











Обсуждение, отзывы о книге «Учитесь быстро читать» и просто собственные мнения читателей. Оставьте ваши комментарии, напишите, что Вы думаете о произведении, его смысле или главных героях. Укажите что конкретно понравилось, а что нет, и почему Вы так считаете.