Виталий Батов - Другому как понять тебя?
Здесь есть возможность читать онлайн «Виталий Батов - Другому как понять тебя?» весь текст электронной книги совершенно бесплатно (целиком полную версию без сокращений). В некоторых случаях можно слушать аудио, скачать через торрент в формате fb2 и присутствует краткое содержание. Город: Москва, Год выпуска: 1991, ISBN: 1991, Издательство: Знание, Жанр: Прочая научная литература, на русском языке. Описание произведения, (предисловие) а так же отзывы посетителей доступны на портале библиотеки ЛибКат.

- Название:Другому как понять тебя?
- Автор:
- Издательство:Знание
- Жанр:
- Год:1991
- Город:Москва
- ISBN:5-07-002147-8
- Рейтинг книги:5 / 5. Голосов: 1
-
Избранное:Добавить в избранное
- Отзывы:
-
Ваша оценка:
Другому как понять тебя?: краткое содержание, описание и аннотация
Предлагаем к чтению аннотацию, описание, краткое содержание или предисловие (зависит от того, что написал сам автор книги «Другому как понять тебя?»). Если вы не нашли необходимую информацию о книге — напишите в комментариях, мы постараемся отыскать её.
Наша брошюра посвящена этим, прежде не поднимавшимся в научно-популярной литературе, вопросам. В работе высказана оригинальная точка зрения на авторство «Тихого Дона», даны психологические характеристики видных политических деятелей.
http://znak.traumlibrary.net
Другому как понять тебя? — читать онлайн бесплатно полную книгу (весь текст) целиком
Ниже представлен текст книги, разбитый по страницам. Система сохранения места последней прочитанной страницы, позволяет с удобством читать онлайн бесплатно книгу «Другому как понять тебя?», без необходимости каждый раз заново искать на чём Вы остановились. Поставьте закладку, и сможете в любой момент перейти на страницу, на которой закончили чтение.
Интервал:
Закладка:
В статье «Лингвистические спектры», вышедшей в 1915 году, Морозов характеризует свой метод как «средство для отличения плагиата от истинных произведений того или другого известного автора». Идею метода Морозов заимствует у немецких исследователей XIX века В. Диттербергера и К. Риттера, которые изучали спорные тексты (среди них тексты, приписываемые Платону, Гёте и др.) методами статистического анализа употребительности отдельных речевых форм, слов, выражений, фразеологических оборотов и синонимов. Причем в качестве счетных единиц выбирались наиболее подвижные и легко заменяющиеся синонимами элементы языка.
В основе предложенного Н. А. Морозовым метода лежало глубокое убеждение автора в том, что языковые элементы распределяются в общей структуре текста в определенной пропорции, которая характеризует индивидуальный речевой стиль писателя. Но если немецкие исследователи использовали сравнительно редко встречающиеся в тексте лингвистические формы (предполагая, что уникальность языковых форм определяет индивидуальность стиля писателя), Морозов, наоборот, предложил «отбросив все редкие слова, ограничиться наиболее частыми и общими для всех родов литературы». За этим кажущимся незначительным различием в позициях немецких исследователей и Н. А. Морозова скрывалось принципиальное расхождение: не исключительность языкового элемента определяет стиль писателя, но своеобразие в употреблении общих языковых форм, а это может быть объективно установлено только математически. Далее Морозов обратил внимание на тот факт, что не только необходимо учитывать слова, имеющие большую частоту употребления, но и то, что группы этих слов неоднородны, т. е. они должны принадлежать различным частям речи. Особое внимание он уделял незнаменательным словам, служебным, или как назвал их автор, распорядительным частицам речи (союзы, предлоги, некоторые местоимения, наречия и пр.). Отвечая утвердительно на вопрос: нельзя ли по частоте употребления таких частиц узнавать авторов, как по чертам их портретов? — Морозов предлагает: «Для этого прежде всего надо перевести их частоты на графики, обозначая каждую распорядительную частицу на горизонтальной линии, а число ее повторений на вертикальной, и сравнить эти графики между собой у различных авторов».
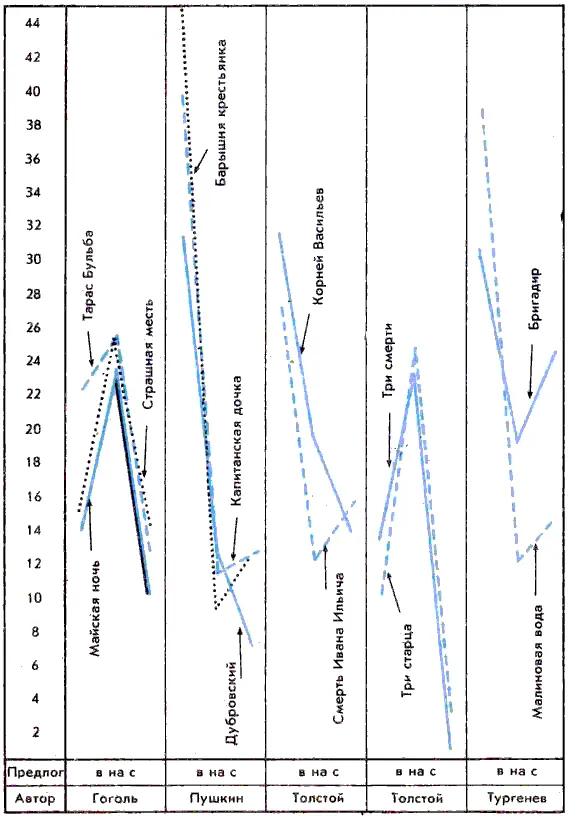
Рис. 1. Образцы «главного предложного спектра» (по Н. А. Морозову)
Таким образом, результат анализа текста, по Морозову, можно представить в виде графика распределения частоты встречаемости различных языковых элементов, сгруппированных в тот или иной грамматический класс (например, график распределения частоты встречаемости предлогов). Эти графики Морозов и называл лингвистическими спектрами.
На рис. 1 приведены примеры лингвистических спектров ряда произведений современных Морозову русских писателей. При обработке текстов Морозов отсчитывал (исключая эпиграфы или вводные цитаты из иностранных авторов) первую тысячу слов. Наиболее часто повторяющимися оказались у всех исследованных авторов предлоги «в», «на» и «с», поэтому их графики Морозов и назвал «главным предложным спектром».
Повышение надежности метода и достоверности результатов достигается, во-первых, за счет увеличения объема текста, то есть числа языковых единиц, входящих в один спектр, и, во-вторых, за счет увеличения числа самих спектров. В конечном итоге и первое и второе требование выполняется при увеличении объема исследуемого текста.
Метод Морозова остался бы действующим рабочим инструментом литературоведов и по сей день, если бы не одно обстоятельство: все показатели этого метода зависят от объема анализируемого текста, а сам автор не определил границу объема, за которой надежность метода не подлежит сомнению. Дело в том, что показатели частоты употребления отдельных языковых элементов, полученные на текстах, скажем, в сто словоформ [1] Словоформа — конкретное слово в грамматической форме.
, могут различаться даже у одного автора, а весь метод строится на близости значений этих показателей. И только в достаточно больших текстах — порядка нескольких тысяч словоформ — показатели частоты стабилизируются и становятся пригодными для сравнения текстов разных авторов.
Ответ на вопрос о минимально необходимом объеме текста, достаточном для установления авторства, дал польский исследователь Е. Ворончак в работе, посвященной математико-статистическому анализу устойчивости различных показателей, используемых в настоящее время в исследованиях языка и стиля произведения. Он приходит к выводу, что границей объема текста (ниже которой результаты недостоверны, а выше — достоверны) является пять тысяч словоформ. Но проблема надежности методов, основанных на использовании частотных показателей, все же остается, так как в литературоведческой практике основной массив анонимной литературы состоит из текстов, гораздо меньших по объему (среди анонимных текстов наиболее часто встречаются письма, полемические статьи, черновые фрагменты произведений, т. е. тексты, не всегда превышающие и тысячу словоформ). Непригодность частотных расчетов для атрибуции коротких текстов заставляет изменить направление поиска надежных показателей. Одно из новых направлений в решении проблемы авторства
Читать дальшеИнтервал:
Закладка:
Похожие книги на «Другому как понять тебя?»
Представляем Вашему вниманию похожие книги на «Другому как понять тебя?» списком для выбора. Мы отобрали схожую по названию и смыслу литературу в надежде предоставить читателям больше вариантов отыскать новые, интересные, ещё непрочитанные произведения.











Обсуждение, отзывы о книге «Другому как понять тебя?» и просто собственные мнения читателей. Оставьте ваши комментарии, напишите, что Вы думаете о произведении, его смысле или главных героях. Укажите что конкретно понравилось, а что нет, и почему Вы так считаете.