Игнаси Белда - Том 33. Разум, машины и математика. Искусственный интеллект и его задачи
Здесь есть возможность читать онлайн «Игнаси Белда - Том 33. Разум, машины и математика. Искусственный интеллект и его задачи» весь текст электронной книги совершенно бесплатно (целиком полную версию без сокращений). В некоторых случаях можно слушать аудио, скачать через торрент в формате fb2 и присутствует краткое содержание. Год выпуска: 2014, ISBN: 2014, Издательство: Де Агостини, Жанр: Математика, на русском языке. Описание произведения, (предисловие) а так же отзывы посетителей доступны на портале библиотеки ЛибКат.

- Название:Том 33. Разум, машины и математика. Искусственный интеллект и его задачи
- Автор:
- Издательство:Де Агостини
- Жанр:
- Год:2014
- ISBN:978-5-9774-0728-1
- Рейтинг книги:3 / 5. Голосов: 1
-
Избранное:Добавить в избранное
- Отзывы:
-
Ваша оценка:
Том 33. Разум, машины и математика. Искусственный интеллект и его задачи: краткое содержание, описание и аннотация
Предлагаем к чтению аннотацию, описание, краткое содержание или предисловие (зависит от того, что написал сам автор книги «Том 33. Разум, машины и математика. Искусственный интеллект и его задачи»). Если вы не нашли необходимую информацию о книге — напишите в комментариях, мы постараемся отыскать её.
Том 33. Разум, машины и математика. Искусственный интеллект и его задачи — читать онлайн бесплатно полную книгу (весь текст) целиком
Ниже представлен текст книги, разбитый по страницам. Система сохранения места последней прочитанной страницы, позволяет с удобством читать онлайн бесплатно книгу «Том 33. Разум, машины и математика. Искусственный интеллект и его задачи», без необходимости каждый раз заново искать на чём Вы остановились. Поставьте закладку, и сможете в любой момент перейти на страницу, на которой закончили чтение.
Интервал:
Закладка:
Еще в XVIII веке Джозеф Пристли составил диаграмму, где изобразил, в какое время жили некоторые выдающиеся деятели античности.
В том же столетии, благодаря трудам Иммануила Канта, который утверждал, что именно представление делает объект возможным, а не наоборот, стало понятно, что нельзя вести споры о знаниях или реальности, не учитывая, что эти самые знания и реальность создает человеческий разум. Так представление и визуализация данных заслуженно заняли важнейшее место в науке.
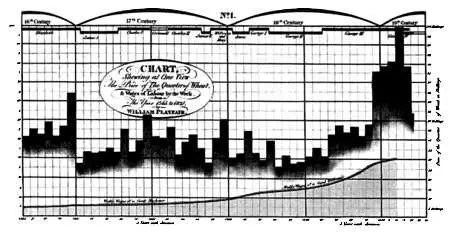
Позднее, во время Промышленной революции, начали появляться более сложные методы представления данных. В частности, Уильям Плейфэр создал методы, позволяющие представить изменение объемов производства, связав их с колебаниями цен на пшеницу и с величиной заработной платы при разных правителях на протяжении более 250 лет.
Благодаря вычислительной технике специалисты в сфере визуализации данных начали понимать, каким должно быть качественное представление данных для их быстрой интерпретации. Один из важнейших моментов, которые следует принимать во внимание (помимо самих данных, модели представления и графического движка, используемого для визуализации), — ограниченные способности восприятия самого аналитика, конечного потребителя данных. В мозгу аналитика происходят определенные когнитивные процессы, в ходе которых выстраивается ментальная модель данных. Однако эти когнитивные процессы страдают из-за ограниченности нашего восприятия: так. большинство из нас неспособны представить себе больше четырех или пять измерений. Чтобы упростить построение моделей, необходимо учитывать все эти ограничения. Качественная визуализация данных должна представлять информацию в иерархическом виде с различными уровнями подробностей. Также визуализация должна быть непротиворечивой и не содержать искажений. В ней следует свести к минимуму влияние данных, которые не содержат полезной информации или могут вести к ошибочным выводам. Рекомендуется дополнять визуализацию иными статистическими данными, указывающими статистическую значимость различной информации.
Для достижения всех этих целей используются стратегии, подобные рассмотренным в главе, посвященной анализу данных. Первая из них заключается в снижении размерности с помощью уже описанных методов, в частности, путем ввода латентных переменных. Вторая стратегия состоит в снижении числа выборок модели путем их разделения на значащие группы. Этот процесс называется кластеризацией (английское слово «кластер» можно перевести как «гроздь», «пучок»).
Кластерный анализ состоит в разделении множества результатов наблюдений на подмножества — кластеры, так, чтобы все результаты, принадлежащие к одному кластеру, обладали некими общими свойствами, необязательно очевидными. Кластеризация данных значительно упрощает их графическое представление, а также позволяет специалистам по визуализации понять изображаемые данные. Существует множество алгоритмов кластеризации, и каждый из них обладает особыми математическими свойствами, которые делают его пригодным для тех или иных типов данных.
В главе об анализе данных нельзя обойти стороной тему распознавания образов как одну из основных целей анализа. Для распознавания образов можно использовать все описанные выше средства: нейронные сети, метод опорных векторов, метод главных компонент и другие. Как вы видите, распознавание образов имеет непосредственное отношение к машинному обучению.
Цель системы-классификатора, подобно нейронной сети или методу опорных векторов, — предсказать, к какому классу относится данная выборка, то есть классифицировать ее. Поэтому системе-классификатору в целях обучения следует передать множество выборок известных классов. После обучения системы ей можно будет передавать для классификации новые выборки. Как и в описанных выше методах, начальное множество выборок известных классов обычно делится на два подмножества — обучающее и тестовое. Тестовое множество помогает проверить, не переобучена ли система.
Читать дальшеИнтервал:
Закладка:
Похожие книги на «Том 33. Разум, машины и математика. Искусственный интеллект и его задачи»
Представляем Вашему вниманию похожие книги на «Том 33. Разум, машины и математика. Искусственный интеллект и его задачи» списком для выбора. Мы отобрали схожую по названию и смыслу литературу в надежде предоставить читателям больше вариантов отыскать новые, интересные, ещё непрочитанные произведения.












Обсуждение, отзывы о книге «Том 33. Разум, машины и математика. Искусственный интеллект и его задачи» и просто собственные мнения читателей. Оставьте ваши комментарии, напишите, что Вы думаете о произведении, его смысле или главных героях. Укажите что конкретно понравилось, а что нет, и почему Вы так считаете.