Игнаси Белда - Том 33. Разум, машины и математика. Искусственный интеллект и его задачи
Здесь есть возможность читать онлайн «Игнаси Белда - Том 33. Разум, машины и математика. Искусственный интеллект и его задачи» весь текст электронной книги совершенно бесплатно (целиком полную версию без сокращений). В некоторых случаях можно слушать аудио, скачать через торрент в формате fb2 и присутствует краткое содержание. Год выпуска: 2014, ISBN: 2014, Издательство: Де Агостини, Жанр: Математика, на русском языке. Описание произведения, (предисловие) а так же отзывы посетителей доступны на портале библиотеки ЛибКат.

- Название:Том 33. Разум, машины и математика. Искусственный интеллект и его задачи
- Автор:
- Издательство:Де Агостини
- Жанр:
- Год:2014
- ISBN:978-5-9774-0728-1
- Рейтинг книги:3 / 5. Голосов: 1
-
Избранное:Добавить в избранное
- Отзывы:
-
Ваша оценка:
Том 33. Разум, машины и математика. Искусственный интеллект и его задачи: краткое содержание, описание и аннотация
Предлагаем к чтению аннотацию, описание, краткое содержание или предисловие (зависит от того, что написал сам автор книги «Том 33. Разум, машины и математика. Искусственный интеллект и его задачи»). Если вы не нашли необходимую информацию о книге — напишите в комментариях, мы постараемся отыскать её.
Том 33. Разум, машины и математика. Искусственный интеллект и его задачи — читать онлайн бесплатно полную книгу (весь текст) целиком
Ниже представлен текст книги, разбитый по страницам. Система сохранения места последней прочитанной страницы, позволяет с удобством читать онлайн бесплатно книгу «Том 33. Разум, машины и математика. Искусственный интеллект и его задачи», без необходимости каждый раз заново искать на чём Вы остановились. Поставьте закладку, и сможете в любой момент перейти на страницу, на которой закончили чтение.
Интервал:
Закладка:
* * *
Для решения задач такого типа обычно используются классические алгоритмы поиска, применяемые в искусственном интеллекте, в частности поиск с возвратом ( back-tracking ) или метод ветвей и границ ( branch-and-bound ). Оба этих алгоритма действуют схожим образом: по сути, они разворачивают комбинаторное дерево и обходят его в поисках оптимального варианта. Развертывание комбинаторного дерева происходит достаточно просто. На первом этапе создается дерево, содержащее все возможные планы (вспомните понятия, которые мы объяснили в первой главе, рассказывая об интеллектуальном алгоритме, способном определять оптимальные ходы в шахматной партии). Далее с помощью интеллектуальных алгоритмов последовательно отсекаются те ветви, которым соответствуют нереальные планы либо планы, нарушающие ограничения или ведущие к неоптимальному решению.
Важное отличие метода поиска с возвратом от метода ветвей и границ заключается в том, что первый метод состоит в обходе дерева в глубину, второй — в обходе в ширину. Это различие крайне важно: в зависимости от представления задачи отсечение той или иной ветви может иметь разную эффективность.
Последовательное отсечение ветвей дерева по мере обхода абсолютно необходимо — в противном случае, как и почти во всех комбинаторных задачах, число планов, а значит, и число ветвей, будет так велико, что его нельзя будет обойти за разумное время. Чтобы ускорить отсечение ветвей, в методах, основанных на обходе дерева, обычно используются так называемые эвристики (или формальное представление интуитивных понятий), которые может применить специалист предметной области, чтобы определить: та или иная ветвь не приведет к нужному результату, и ее необходимо отсечь как можно скорее. Разумеется, если мы отсечем ветвь, которая соответствует неосуществимому плану, на раннем этапе алгоритма, то можем сэкономить несколько часов вычислений — с переходом на более высокие уровни число вариантов, которые необходимо проанализировать, возрастает экспоненциально.
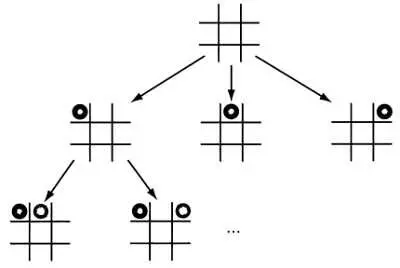
Простой пример дерева планирования для игры «крестики-нолики».
* * *
ТЕОРЕМА «БЕСПЛАТНОГО ОБЕДА НЕ БЫВАЕТ»
Теорема под названием «бесплатного обеда не бывает» (no-free lunch) гласит: не существует алгоритма, позволяющего получить оптимальные решения всех возможных задач. Теорема получила свое любопытное название на основе метафоры о стоимости блюд в различных ресторанах. Допустим, что существует определенное число ресторанов (каждый из них обозначает определенный алгоритм прогнозирования), где в меню различным блюдам (каждое блюдо обозначает определенную задачу прогнозирования) сопоставлена цена (или качество решения этой задачи, которое позволяет получить рассматриваемый алгоритм). Человек, который любит поесть и при этом не прочь сэкономить, может определить, какой ресторан предлагает его любимое блюдо по самой выгодной цене. Вегетарианец, сопровождающий этого обжору, наверняка обнаружит, что его любимое вегетарианское блюдо в этом ресторане стоит намного дороже. Если обжора захочет полакомиться бифштексом, он выберет ресторан, где бифштекс подают по самой низкой цене. Но у его друга-вегетарианца при этом не останется другого выбора, кроме как заказать единственное вегетарианское блюдо в этом ресторане, пусть даже по заоблачной цене. Это очень точная метафора ситуации, когда необходимость использования определенного алгоритма для решения конкретной задачи приводит к гарантированно неоптимальным результатам. Исследователи прилагают огромные усилия для создания супералгоритма или суперметода, позволяющего составить идеальный план, но в конечном итоге неизменно сталкиваются с определенным множеством данных или контекстом, в котором оптимальные результаты показывает другой алгоритм.
Теорема имеет еще одно важное следствие: если мы тратим много сил на корректировку алгоритма, чтобы добиться идеальных результатов для определенных исходных данных, эти корректировки гарантированно приведут к ухудшению работы алгоритма для другого множества данных. Вывод: любой алгоритм будет либо работать идеально для небольшого числа случаев и плохо — во всех остальных, либо будет демонстрировать посредственные результаты во всех случаях. соответствует неосуществимому плану, на раннем этапе алгоритма, то можем сэкономить несколько часов вычислений — с переходом на более высокие уровни число вариантов, которые необходимо проанализировать, возрастает экспоненциально.
Читать дальшеИнтервал:
Закладка:
Похожие книги на «Том 33. Разум, машины и математика. Искусственный интеллект и его задачи»
Представляем Вашему вниманию похожие книги на «Том 33. Разум, машины и математика. Искусственный интеллект и его задачи» списком для выбора. Мы отобрали схожую по названию и смыслу литературу в надежде предоставить читателям больше вариантов отыскать новые, интересные, ещё непрочитанные произведения.












Обсуждение, отзывы о книге «Том 33. Разум, машины и математика. Искусственный интеллект и его задачи» и просто собственные мнения читателей. Оставьте ваши комментарии, напишите, что Вы думаете о произведении, его смысле или главных героях. Укажите что конкретно понравилось, а что нет, и почему Вы так считаете.