Игнаси Белда - Том 33. Разум, машины и математика. Искусственный интеллект и его задачи
Здесь есть возможность читать онлайн «Игнаси Белда - Том 33. Разум, машины и математика. Искусственный интеллект и его задачи» весь текст электронной книги совершенно бесплатно (целиком полную версию без сокращений). В некоторых случаях можно слушать аудио, скачать через торрент в формате fb2 и присутствует краткое содержание. Год выпуска: 2014, ISBN: 2014, Издательство: Де Агостини, Жанр: Математика, на русском языке. Описание произведения, (предисловие) а так же отзывы посетителей доступны на портале библиотеки ЛибКат.

- Название:Том 33. Разум, машины и математика. Искусственный интеллект и его задачи
- Автор:
- Издательство:Де Агостини
- Жанр:
- Год:2014
- ISBN:978-5-9774-0728-1
- Рейтинг книги:3 / 5. Голосов: 1
-
Избранное:Добавить в избранное
- Отзывы:
-
Ваша оценка:
Том 33. Разум, машины и математика. Искусственный интеллект и его задачи: краткое содержание, описание и аннотация
Предлагаем к чтению аннотацию, описание, краткое содержание или предисловие (зависит от того, что написал сам автор книги «Том 33. Разум, машины и математика. Искусственный интеллект и его задачи»). Если вы не нашли необходимую информацию о книге — напишите в комментариях, мы постараемся отыскать её.
Том 33. Разум, машины и математика. Искусственный интеллект и его задачи — читать онлайн бесплатно полную книгу (весь текст) целиком
Ниже представлен текст книги, разбитый по страницам. Система сохранения места последней прочитанной страницы, позволяет с удобством читать онлайн бесплатно книгу «Том 33. Разум, машины и математика. Искусственный интеллект и его задачи», без необходимости каждый раз заново искать на чём Вы остановились. Поставьте закладку, и сможете в любой момент перейти на страницу, на которой закончили чтение.
Интервал:
Закладка:
* * *
ИНФОРМАЦИОННОЕ ДЕРЕВО
Дерево — это структура данных, которая очень широко используется в инженерном деле, так как позволяет строить иерархии данных. При работе с деревьями используются особые понятия.
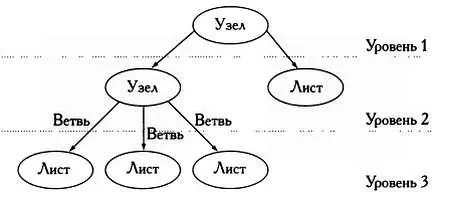
Данные, представленные в дереве, называются узлами. Эти узлы, представляющие единицы информации, делятся на разные уровни и связываются между собой ветвями. Узел, связанный с узлом более высокого уровня, называется потомком, узел, связанный с узлом низшего уровня, — родителем. Узлы, не имеющие потомков, называются листьями.
* * *
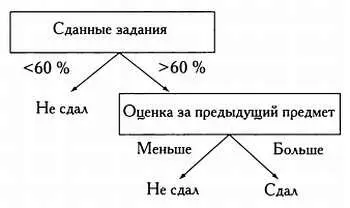
В этом случае посещаемость не является определяющей переменной, поэтому не представлена в виде узла дерева. Существуют различные методологии, позволяющие определить, является ли переменная модели дискриминантной (иными словами, можно ли разделить выборку на группы в зависимости от значений этой переменной). В основе одной из самых популярных методологий лежит понятие энтропии Шеннона. В рамках этой методологии для каждого уровня дерева определяется переменная, порождающая меньше всего энтропии. Именно эта переменная и будет дискриминантной для рассматриваемого уровня. Рассмотрим метод подробнее.
Энтропия Шеннона Sрассчитывается по следующей формуле:
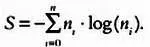
Попробуем применить это понятие в нашей задаче об экзаменах. На первом уровне дерева необходимо проанализировать энтропию, порождаемую каждой переменной. Первая переменная — «оценка за предыдущий предмет». Если мы разделим выборки в зависимости от значений этой переменной, получим два подмножества выборок. Для первого подмножества энтропия Шеннона будет равна
S Оценка за предыдущий предмет ниже средней = -0,75∙ log(0,75)— 0,25∙ log(0,25)= 0,56,
так как среди студентов, которые в прошлом году получили оценку ниже средней, не сдали экзамен 75 %, сдали — 25 %. Для второго множества энтропия Шеннона будет равна
S Оценка за предыдущий предмет ниже средней = -0,33∙ log(0,33)— 0,67∙ log(0,67)= 0,64,
так как треть студентов, которые в прошлом году получили оценку выше средней, не сдали экзамен, две трети студентов — сдали.
Подобные расчеты повторяются для каждой переменной. Следующая переменная — «посещаемость». Для простоты установим граничное значение посещаемости, равное 95 %. В этом случае
S Посещаемость выше 95 %= -0,6∙ log (0,6)— 0,4∙ log(0,4)= 0,67;
S Посещаемость выше 95 %= -0,5∙ log (0,5)— 0,5∙ log(0,5)= 0,69
Наконец, рассмотрим переменную «сданные задания» и вновь для простоты разобъем выборку на 2 группы, выделив тех, кто сдал больше и меньше 60 % заданий.
Имеем:
S Сдано более 60 % заданий= -0,75∙ log(0,75)— 0,25∙ log(0,25)= 0,56;
и
S Сдано более 60 % заданий= -1∙ log(1)= 0
Следовательно, наилучшей дискриминантной переменной будет последняя, так как энтропия подмножеств, выделенных на ее основе, равна 0,56 и 0.
В этом случае все представители обучающей выборки, сдавшие менее 60 % заданий, не сдали экзамен, следовательно, эту ветвь дерева можно не рассматривать.
Но другая ветвь содержит одинаковое число студентов, сдавших и не сдавших экзамен. Следовательно, необходимо продолжить анализ, не учитывая уже дискриминированные выборки.
Теперь остались только две переменные, которые могут повлиять на итоговое решение: «оценка за предыдущий предмет» и «посещаемость». Значения энтропии Шеннона для групп, выделенных в зависимости от значений первой дискриминантной переменной, таковы:
S Оценка за предыдущий предмет ниже средней= -0,5∙ log (0,5)— 0,5∙ log (0,5)= 0,69;
S Оценка за предыдущий предмет ниже средней= -1∙ log(1)= 0
Если мы рассмотрим переменную «посещаемость»,
S Посещаемость выше 95 % = -0,33∙ log (0,33)— 0,67∙ log (0,67)= 0,64;
Читать дальшеИнтервал:
Закладка:
Похожие книги на «Том 33. Разум, машины и математика. Искусственный интеллект и его задачи»
Представляем Вашему вниманию похожие книги на «Том 33. Разум, машины и математика. Искусственный интеллект и его задачи» списком для выбора. Мы отобрали схожую по названию и смыслу литературу в надежде предоставить читателям больше вариантов отыскать новые, интересные, ещё непрочитанные произведения.












Обсуждение, отзывы о книге «Том 33. Разум, машины и математика. Искусственный интеллект и его задачи» и просто собственные мнения читателей. Оставьте ваши комментарии, напишите, что Вы думаете о произведении, его смысле или главных героях. Укажите что конкретно понравилось, а что нет, и почему Вы так считаете.