Ричард Докинз - Сліпий годинникар - як еволюція доводить відсутність задуму у Всесвіті
Здесь есть возможность читать онлайн «Ричард Докинз - Сліпий годинникар - як еволюція доводить відсутність задуму у Всесвіті» весь текст электронной книги совершенно бесплатно (целиком полную версию без сокращений). В некоторых случаях можно слушать аудио, скачать через торрент в формате fb2 и присутствует краткое содержание. Год выпуска: 2018, ISBN: 2018, Издательство: Книжковий Клуб «Клуб Сімейного Дозвілля», Жанр: Биология, на украинском языке. Описание произведения, (предисловие) а так же отзывы посетителей доступны на портале библиотеки ЛибКат.

- Название:Сліпий годинникар: як еволюція доводить відсутність задуму у Всесвіті
- Автор:
- Издательство:Книжковий Клуб «Клуб Сімейного Дозвілля»
- Жанр:
- Год:2018
- ISBN:978-617-12-6244-7
- Рейтинг книги:3 / 5. Голосов: 1
-
Избранное:Добавить в избранное
- Отзывы:
-
Ваша оценка:
Сліпий годинникар: як еволюція доводить відсутність задуму у Всесвіті: краткое содержание, описание и аннотация
Предлагаем к чтению аннотацию, описание, краткое содержание или предисловие (зависит от того, что написал сам автор книги «Сліпий годинникар: як еволюція доводить відсутність задуму у Всесвіті»). Если вы не нашли необходимую информацию о книге — напишите в комментариях, мы постараемся отыскать её.
Сліпий годинникар: як еволюція доводить відсутність задуму у Всесвіті — читать онлайн бесплатно полную книгу (весь текст) целиком
Ниже представлен текст книги, разбитый по страницам. Система сохранения места последней прочитанной страницы, позволяет с удобством читать онлайн бесплатно книгу «Сліпий годинникар: як еволюція доводить відсутність задуму у Всесвіті», без необходимости каждый раз заново искать на чём Вы остановились. Поставьте закладку, и сможете в любой момент перейти на страницу, на которой закончили чтение.
Интервал:
Закладка:
За спроби розглянути всі можливі дерева виникають труднощі з обчисленням. Якщо треба класифікувати лише трьох тварин, то кількість можливих дерев дорівнює трьом: А , з’єднане з B в обхід C ; А з C в обхід B ; B з C в обхід А . Якщо ж треба класифікувати більшу кількість тварин, можна виконати такі самі розрахунки, але кількість можливих дерев різко зросте. Якщо треба розглянути лише чотирьох тварин, то загальна кількість можливих дерев спорідненості є все ще контрольованою й дорівнює лише 15. Комп’ютеру не знадобиться багато часу, щоб обчислити, яке з цих 15 є найощадливішим. Але якщо треба розглянути вже 20 тварин, то, за моїми підрахунками, кількість можливих дерев дорівнює 8 200 794 532 637 891 559 375 (див. рис. 9). Було розраховано, що найшвидшому з сучасних комп’ютерів, аби виявити найощадливіше дерево всього з 20 тварин, знадобилося б 10 000 мільйонів років, що приблизно дорівнює вікові Всесвіту. А таксономісти часто прагнуть побудувати дерева з понад 20 тварин.
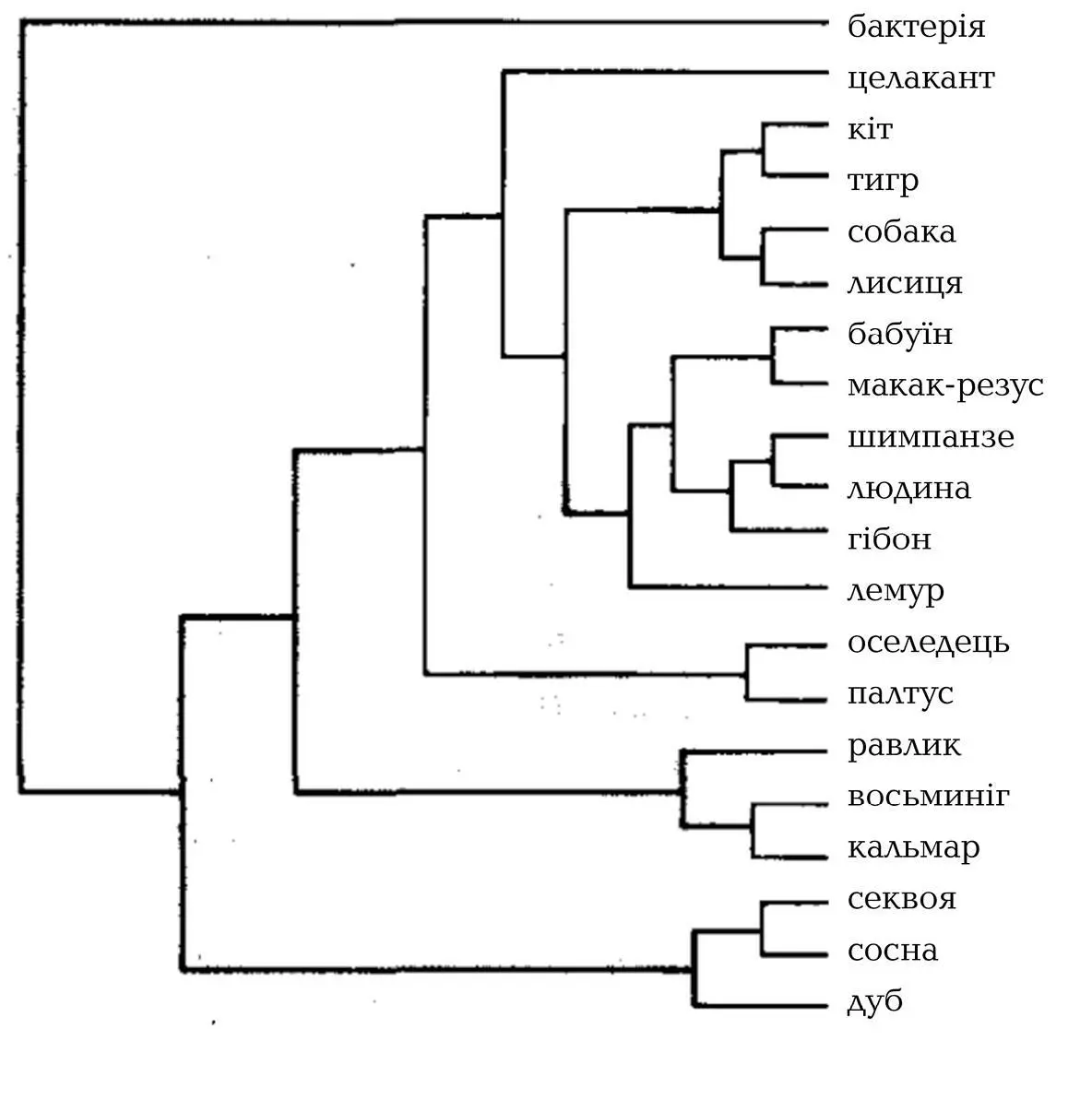
Рис. 9. Це генеалогічне дерево є правильним. Існує 8 200 794 532 637 891 559 374 інші способи класифікації цих 20 організмів, і всі вони є неправильними.
Хоча молекулярні таксономісти були першими, хто почав про неї говорити, проблема вибухових великих цифр насправді прихована по всій немолекулярній таксономії. Немолекулярні таксономісти просто уникали її, роблячи інтуїтивні здогади. З усіх можливих генеалогічних дерев, які можна було б випробувати, величезну кількість можна відкинути одразу — наприклад, усі ті мільйони можливих генеалогічних дерев, де люди розміщуються ближче до земляних червів, аніж до шимпанзе. Таксономісти навіть не переймаються тим, аби звернути увагу на такі очевидно абсурдні дерева спорідненості, а натомість зосереджуються на порівняно небагатьох деревах, що не надто різко суперечать їхнім сталим уявленням. Це, мабуть, справедливо, хоча завжди існує небезпека, що по-справжньому найощадливішим деревом виявиться одне з тих, які були відкинуті без розгляду. Комп’ютери теж можна запрограмувати йти навпростець, і масштаби проблеми вибухових великих цифр, на щастя, можна зменшити.
Молекулярна інформація є настільки багатою, що нашу таксономію можна будувати окремо, знову й знову, для різних білків. Після цього можна використовувати наші висновки, зроблені з вивчення однієї молекули, для перевірки наших висновків, що базуються на дослідженні іншої. Якщо нас турбує, що історія, яку розповідає одна білкова молекула, заплутується конвергенцією, можна одразу ж перевірити її, подивившись на іншу білкову молекулу. Конвергентна еволюція насправді є особливим різновидом збігу. Проблема ж зі збігами полягає в тому, що, навіть якщо вони виникають один раз, вони значно менш імовірно стаються двічі. А ще менш імовірно — тричі. Розглядаючи дедалі більше окремих білкових молекул, можна практично убезпечити себе від будь-яких збігів.
Наприклад, в одному дослідженні групою новозеландських біологів 11 тварин були класифіковані, і не раз, а п’ять разів, незалежним чином із використанням п’яти різних білкових молекул. Цими тваринами були вівця, макак-резус, кінь, кенгуру, щур, кролик, собака, свиня, людина, корова й шимпанзе. Ідея полягала в тому, аби спочатку розробити дерево взаємозв’язків серед цих 11 тварин із використанням одного білка, а потім подивитися, чи буде отримане таке саме дерево взаємозв’язків для іншого білка. Після цього зробити те саме для третього, четвертого та п’ятого білків. Теоретично припускалося, що, наприклад, коли теорія еволюції є хибною, можливо, кожен із п’яти білків дасть зовсім інше дерево «родинних зв’язків».
Усі п’ять білкових послідовностей для всіх 11 тварин були доступні для перегляду в бібліотеці. Для 11 тварин треба розглянути 654 729 075 можливих дерев взаємозв’язків, а тому довелося застосувати звичайні обхідні шляхи. Для кожної з п’яти білкових молекул комп’ютер роздрукував найощадливіше дерево родинних зв’язків. Це дало п’ять кращих незалежних здогадів щодо можливого єдино правильного дерева взаємозв’язків між цими 11 тваринами. Найкращим результатом, на який тільки можна сподіватися, було б, якби всі ці п’ять дерев виявились ідентичними. Імовірність отримання такого результату завдяки чистій удачі насправді дуже мала: після коми в цьому числі аж 31 нуль. Не слід дивуватись, якщо нам не вдасться отримати такий ідеальний збіг: очікувати можна лише певного обсягу конвергентної еволюції та збігу. Але нас мало би стурбувати, якби серед різних дерев не було виявлено значної міри збігу. Фактично всі п’ять дерев виявилися не зовсім ідентичними, але дуже схожими. Усі п’ять молекул збігаються в тому, що розміщують людину, шимпанзе та макака-резуса поблизу одне одного, а от щодо того, яка тварина є наступною найближчою до цієї групи, існують деякі розбіжності: гемоглобін B стверджує, що це собака; фібринопептид B — що щур; фібринопептид А наполягає на тому, що це група «щур + кролик»; а гемоглобін А — що це група «щур, кролик і собака».
Читать дальшеИнтервал:
Закладка:
Похожие книги на «Сліпий годинникар: як еволюція доводить відсутність задуму у Всесвіті»
Представляем Вашему вниманию похожие книги на «Сліпий годинникар: як еволюція доводить відсутність задуму у Всесвіті» списком для выбора. Мы отобрали схожую по названию и смыслу литературу в надежде предоставить читателям больше вариантов отыскать новые, интересные, ещё непрочитанные произведения.








![Ричард Докинз - Река, выходящая из Эдема [Жизнь с точки зрения дарвиниста]](/books/393180/richard-dokinz-reka-vyhodyachaya-iz-edema-zhizn-s-to-thumb.webp)


Обсуждение, отзывы о книге «Сліпий годинникар: як еволюція доводить відсутність задуму у Всесвіті» и просто собственные мнения читателей. Оставьте ваши комментарии, напишите, что Вы думаете о произведении, его смысле или главных героях. Укажите что конкретно понравилось, а что нет, и почему Вы так считаете.