W Cat - Описание языка PascalABC.NET
Здесь есть возможность читать онлайн «W Cat - Описание языка PascalABC.NET» весь текст электронной книги совершенно бесплатно (целиком полную версию без сокращений). В некоторых случаях можно слушать аудио, скачать через торрент в формате fb2 и присутствует краткое содержание. Жанр: Программирование, Детская образовательная литература, на русском языке. Описание произведения, (предисловие) а так же отзывы посетителей доступны на портале библиотеки ЛибКат.
- Название:Описание языка PascalABC.NET
- Автор:
- Жанр:
- Год:неизвестен
- ISBN:нет данных
- Рейтинг книги:5 / 5. Голосов: 1
-
Избранное:Добавить в избранное
- Отзывы:
-
Ваша оценка:
Описание языка PascalABC.NET: краткое содержание, описание и аннотация
Предлагаем к чтению аннотацию, описание, краткое содержание или предисловие (зависит от того, что написал сам автор книги «Описание языка PascalABC.NET»). Если вы не нашли необходимую информацию о книге — напишите в комментариях, мы постараемся отыскать её.
PascalABC.NET является мультипарадигменным языком: на нем можно программировать в структурном, объектно-ориентированном и функциональном стилях.
PascalABC.NET — это также простая и мощная интегрированная среда разработки, поддерживающая технологию IntelliSense, содержащая средства автоформатирования, встроенный отладчик и встроенный дизайнер форм.
Описание языка PascalABC.NET — читать онлайн бесплатно полную книгу (весь текст) целиком
Ниже представлен текст книги, разбитый по страницам. Система сохранения места последней прочитанной страницы, позволяет с удобством читать онлайн бесплатно книгу «Описание языка PascalABC.NET», без необходимости каждый раз заново искать на чём Вы остановились. Поставьте закладку, и сможете в любой момент перейти на страницу, на которой закончили чтение.
Интервал:
Закладка:
Приведем окно задачника, которое появится на экране при запуске программы-заготовки для данного задания (в данном окне скрыт раздел с формулировкой; в результате оказались скрытыми и кнопки, отвечающие за интеллектуальную" прокрутку, поскольку в окне полностью отображается содержимое оставшихся разделов):
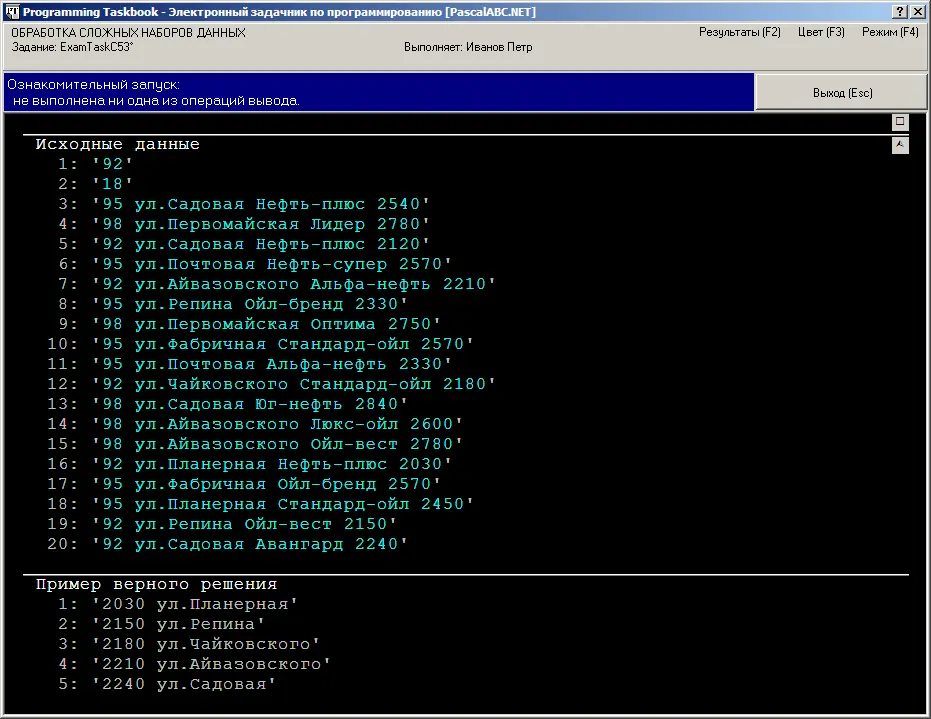
Выясним, какая структура является наиболее подходящей для хранения информации, необходимой для решения задачи. Нам требуется информация, связанная с различными улицами, которых по условию не более 30, причем для каждой улицы надо хранить сведения двух видов: ее название и максимальную цену бензина марки M . Поэтому мы можем либо завести массив из 30 элементов-записей с двумя полями, либо два массива: один содержащий названия улиц, а другой -- максимальные цены. Учитывая, что в конце программы нам потребуется выполнять сортировку полученных данных, целесообразнее использовать массив записей, поскольку это позволит записать алгоритм сортировки в более компактной форме.
Определим запись Street с двумя полями name и max и опишем массив s из 30 элементов типа Street. Следует также завести переменную ns, в которой будет храниться количество заполненных элементов массива s.
При обработке каждой строки с исходными данными нам будут нужны прежде всего сведения о марке бензина. Если марка бензина не равна M, то оставшуюся часть строки обрабатывать не требуется, и можно сразу перейти к разбору следующей строки. Если марка бензина равна M, то необходимо узнать название улицы s0 и цену бензина p. Заметим, что название компании для решения задачи не требуется, однако его необходимо прочесть, чтобы определить следующий элемент данных -- цену бензина.
Если улица с названием s0 еще не была включена в массив s, то ее необходимо включить в массив, присвоив полю max значение p. Если же улица уже присутствует в массиве, то необходимо сравнить поле max для данной улицы и значение p, изменив при необходимости поле max (здесь мы используем базовый алгоритм нахождения максимального значения).
Для ввода названий улиц и компаний в нашем случае удобно организовать посимвольное чтение строковых данных; признаком завершения такого чтения будет обнаружение пробельного символа.
После обработки набора исходных данных необходимо проверить, найдена ли хотя бы одна улица с АЗС, предлагающей марку бензина M (для этого достаточно сравнить значение ns с нулем). Если ни одна улица не найдена, то надо вывести строку Нет"; в противном случае требуется выполнить сортировку массива s по указанному набору ключей и вывести полученные данные в требуемом порядке. Поскольку размер массива невелик, для его сортировки вполне допустимо использовать один из простых алгоритмов, например, алгоритм пузырьковой сортировки .
Приведем один из вариантов правильного решения задачи:
usesPT4Exam;
type
Street = record
name: string;
max: integer;
end;
var
m, n, ns, i, j, k, p: integer;
s: array[1..30] of Street;
s0: string;
x: Street;
c: char;
begin
Task('ExamTaskC53');
readln(m); { m - марка бензина }
readln(n);
ns := 0;
fori := 1 ton do
begin
read(k);
ifk <> m then
readln { пропускаем оставшуюся часть строки }
else
begin
s0 := '';
read(c); { пропускаем пробел после первого числа }
read(c); { читаем первый символ названия улицы }
whilec <> ' ' do
begin
s0 := s0 + c;
read(c);
end;
read(c); { читаем первый символ названия компании }
whilec <> ' ' do
read(c); { название компании не сохраняем }
readln(p); { читаем цену бензина и переходим на новую строку }
{ Обработка прочитанной информации }
k := 0;
forj := 1 tons do
ifs[j].name = s0 then { улица уже содержится в массиве s }
begin
k := 1;
ifs[j].max < p then
s[j].max := p;
break;
end;
ifk = 0 then { улица еще не содержится в массиве s }
Интервал:
Закладка:
Похожие книги на «Описание языка PascalABC.NET»
Представляем Вашему вниманию похожие книги на «Описание языка PascalABC.NET» списком для выбора. Мы отобрали схожую по названию и смыслу литературу в надежде предоставить читателям больше вариантов отыскать новые, интересные, ещё непрочитанные произведения.







![Сэмюэль Тьюк - ОПИСАНИЕ РЕТРИТА, заведения близ Йорка для умалишенных из Общества Друзей [Содержит отчет о его возникновении и развитии, способах лечения, а также описание историй болезни]](/books/423708/semyuel-tyuk-opisanie-retrita-zavedeniya-bliz-jork-thumb.webp)




Обсуждение, отзывы о книге «Описание языка PascalABC.NET» и просто собственные мнения читателей. Оставьте ваши комментарии, напишите, что Вы думаете о произведении, его смысле или главных героях. Укажите что конкретно понравилось, а что нет, и почему Вы так считаете.