Марейн Хавербеке - Выразительный JavaScript
Здесь есть возможность читать онлайн «Марейн Хавербеке - Выразительный JavaScript» весь текст электронной книги совершенно бесплатно (целиком полную версию без сокращений). В некоторых случаях можно слушать аудио, скачать через торрент в формате fb2 и присутствует краткое содержание. ISBN: , Жанр: Программирование, на русском языке. Описание произведения, (предисловие) а так же отзывы посетителей доступны на портале библиотеки ЛибКат.

- Название:Выразительный JavaScript
- Автор:
- Жанр:
- Год:неизвестен
- ISBN:978-1593275846
- Рейтинг книги:5 / 5. Голосов: 1
-
Избранное:Добавить в избранное
- Отзывы:
-
Ваша оценка:
Выразительный JavaScript: краткое содержание, описание и аннотация
Предлагаем к чтению аннотацию, описание, краткое содержание или предисловие (зависит от того, что написал сам автор книги «Выразительный JavaScript»). Если вы не нашли необходимую информацию о книге — напишите в комментариях, мы постараемся отыскать её.
Выразительный JavaScript — читать онлайн бесплатно полную книгу (весь текст) целиком
Ниже представлен текст книги, разбитый по страницам. Система сохранения места последней прочитанной страницы, позволяет с удобством читать онлайн бесплатно книгу «Выразительный JavaScript», без необходимости каждый раз заново искать на чём Вы остановились. Поставьте закладку, и сможете в любой момент перейти на страницу, на которой закончили чтение.
Интервал:
Закладка:
Структура документа
Можно представить HTML как набор вложенных коробок. Теги вроде
и включают в себя другие теги, которые в свою очередь включают теги, или текст. Вот вам пример документа из предыдущей главы:Моя домашняя страничка
Привет, я Марейн и это моя домашняя страничка.
А ещё я книжку написал! Читайте её
здесь.
У этой страницы следующая структура:

Структура данных, использующаяся браузером для представления документа, отражает его форму. Для каждой коробки есть объект, с которым мы можем взаимодействовать и узнавать про него разные данные – какой тег он представляет, какие коробки и текст содержит. Это представление называется Document Object Model (объектная модель документа), или сокращённо DOM.
Мы можем получить доступ к этим объектам через глобальную переменную document. Её свойство documentElementссылается на объект, представляющий тег . Он также предоставляет свойства headи body, в которых содержатся объекты для соответствующих элементов.
Деревья
Вспомните синтаксические деревья из главы 11. Их структура удивительно похожа на структуру документа браузера. Каждый узел может ссылаться на другие узлы, у каждого из ответвлений может быть своё ответвление. Эта структура – типичный пример вложенных структур, где элементы содержат подэлементы, похожие на них самих.
Мы зовём структуру данных деревом, когда она разветвляется, не имеет циклов (узел не может содержать сам себя), и имеет единственный ярко выраженный «корень». В случае DOM в качестве корня выступает document.documentElement.
Деревья часто встречаются в вычислительной науке. В дополнение к представлению рекурсивных структур вроде документа HTML или программ, они часто используются для работы с сортированными наборами данных, потому что элементы обычно проще найти или вставлять в отсортированное дерево, чем в отсортированный одномерный массив.
У типичного дерева есть разные узлы. У синтаксического дерева языка Egg были переменные, значения и приложения. У приложений всегда были дочерние ветви, а переменные и значения были «листьями», то есть узлами без дочерних ответвлений.
То же и у DOM. Узлы для обычных элементов, представляющих теги HTML, определяют структуру документа. У них могут быть дочерние узлы. Пример такого узла — document.body. Некоторые из этих дочерних узлов могут оказаться листьями – например, текст или комментарии (в HTML комментарии записываются между символами ).
У каждого узлового объекта DOM есть свойство nodeType, содержащее цифровой код, определяющий тип узла. У обычных элементов он равен 1, что также определено в виде свойства-константы document.ELEMENT_NODE. У текстовых узлов, представляющих отрывки текста, он равен 3 ( document.TEXT_NODE). У комментариев — 8 ( document.COMMENT_NODE).
То есть, вот ещё один способ графически представить дерево документа:
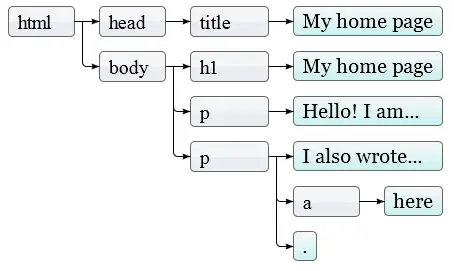
Листья – текстовые узлы, а стрелки показывают взаимоотношения отец-ребёнок между узлами.
Стандарт
Использовать загадочные цифры для представления типа узла – это подход не в стиле JavaScript. Позже мы встретимся с другими частями интерфейса DOM, которые тоже кажутся чуждыми и нескладными. Причина в том, что DOM разрабатывался не только для JavaScript. Он пытается определить интерфейс, не зависящий от языка, который можно использовать и в других системах – не только в HTML, но и в XML, который представляет из себя формат данных общего назначения с синтаксисом, напоминающим HTML.
Получается неудобно. Хотя стандарты – и весьма полезная штука, в нашем случае преимущество независимости от языка не такое уж и полезное. Лучше иметь интерфейс, хорошо приспособленный к языку, который вы используете, чем интерфейс, который будет знаком при использовании разных языков.
Чтобы показать неудобную интеграцию с языком, рассмотрим свойство childNodes, которое есть у узлов DOM. В нём содержится объект, похожий на массив, со свойством length, и пронумерованные свойства для доступа к дочерним узлам. Но это – экземпляр типа NodeList, не настоящий массив, поэтому у него нет методов вроде forEach.
Есть также проблемы, связанные с плохой продуманностью системы. К примеру, нельзя создать новый узел и сразу добавить к нему свойства или дочерние узлы. Сначала нужно его создать, затем добавить дочерние по одному, и в конце назначить свойства по одному, с использованием побочных эффектов. Код, плотно работающий с DOM, получается длинным, некрасивым и со множеством повторов.
Читать дальшеИнтервал:
Закладка:
Похожие книги на «Выразительный JavaScript»
Представляем Вашему вниманию похожие книги на «Выразительный JavaScript» списком для выбора. Мы отобрали схожую по названию и смыслу литературу в надежде предоставить читателям больше вариантов отыскать новые, интересные, ещё непрочитанные произведения.










Обсуждение, отзывы о книге «Выразительный JavaScript» и просто собственные мнения читателей. Оставьте ваши комментарии, напишите, что Вы думаете о произведении, его смысле или главных героях. Укажите что конкретно понравилось, а что нет, и почему Вы так считаете.