Марейн Хавербеке - Выразительный JavaScript
Здесь есть возможность читать онлайн «Марейн Хавербеке - Выразительный JavaScript» весь текст электронной книги совершенно бесплатно (целиком полную версию без сокращений). В некоторых случаях можно слушать аудио, скачать через торрент в формате fb2 и присутствует краткое содержание. ISBN: , Жанр: Программирование, на русском языке. Описание произведения, (предисловие) а так же отзывы посетителей доступны на портале библиотеки ЛибКат.

- Название:Выразительный JavaScript
- Автор:
- Жанр:
- Год:неизвестен
- ISBN:978-1593275846
- Рейтинг книги:5 / 5. Голосов: 1
-
Избранное:Добавить в избранное
- Отзывы:
-
Ваша оценка:
Выразительный JavaScript: краткое содержание, описание и аннотация
Предлагаем к чтению аннотацию, описание, краткое содержание или предисловие (зависит от того, что написал сам автор книги «Выразительный JavaScript»). Если вы не нашли необходимую информацию о книге — напишите в комментариях, мы постараемся отыскать её.
Выразительный JavaScript — читать онлайн бесплатно полную книгу (весь текст) целиком
Ниже представлен текст книги, разбитый по страницам. Система сохранения места последней прочитанной страницы, позволяет с удобством читать онлайн бесплатно книгу «Выразительный JavaScript», без необходимости каждый раз заново искать на чём Вы остановились. Поставьте закладку, и сможете в любой момент перейти на страницу, на которой закончили чтение.
Интервал:
Закладка:
Если нам надо принудить совпадение взять всю строку целиком, мы используем метки ^и $. ^совпадает с началом строки, а $– с концом. Поэтому /^\d+$/совпадает со строкой, состоящей только из одной или нескольких цифр, /^!/совпадает со строкой, начинающейся с восклицательного знака, а /x^/не совпадает ни с какой строчкой (перед началом строки не может быть x).
Если, с другой стороны, нам просто надо убедиться, что дата начинается и заканчивается на границе слова, мы используем метку \b. Границей слова может быть начало или конец строки, или любое место строки, где с одной стороны стоит алфавитно-цифровой символ \w, а с другой – не алфавитно-цифровой.
console.log(/cat/.test("concatenate"));
// → true
console.log(/\bcat\b/.test("concatenate"));
// → false
Отметим, что метка границы не представляет из себя символ. Это просто ограничение, обозначающее, что совпадение происходит только если выполняется определённое условие.
Шаблоны с выбором
Допустим, надо выяснить, содержит ли текст не просто номер, а номер, за которым следует pig, cow, или chicken в единственном или множественном числе.
Можно было бы написать три регулярки и проверить их по очереди, но есть способ лучше. Символ |обозначает выбор между шаблонами слева и справа от него. И можно сказать следующее:
var animalCount = /\b\d+ (pig|cow|chicken)s?\b/;
console.log(animalCount.test("15 pigs"));
// → true
console.log(animalCount.test("15 pigchickens"));
// → false
Скобки ограничивают часть шаблона, к которой применяется |, и можно поставить много таких операторов друг за другом, чтобы обозначить выбор из более чем двух вариантов.
Механизм поиска
Регулярные выражения можно рассматривать как блок-схемы. Следующая диаграмма описывает последний животноводческий пример.
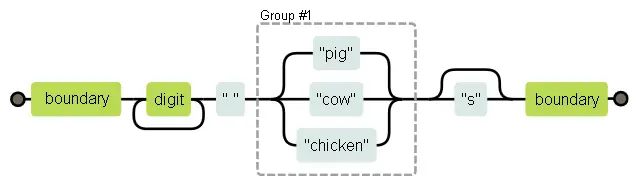
Выражение совпадает со строкой, если можно найти путь с левой части диаграммы в правую. Мы запоминаем текущее положение в строке, и каждый раз, проходя прямоугольник, проверяем, что часть строки сразу за нашим положением в ней совпадает с содержимым прямоугольника.
Значит, проверка совпадения нашей регулярки в строке "the 3 pigs"при прохождении по блок-схеме выглядит так:
• на позиции 4 есть граница слова, и проходим первый прямоугольник
• начиная с 4 позиции находим цифру, и проходим второй прямоугольник
• на позиции 5 один путь замыкается назад перед вторым прямоугольником, а второй проходит далее к прямоугольнику с пробелом. У нас пробел, а не цифра, и мы выбираем второй путь.
• теперь мы на позиции 6, начало “pigs”, и на тройном разветвлении путей. В строке нет “cow” или “chicken”, зато есть “pig”, поэтому мы выбираем этот путь.
• на позиции 9 после тройного разветвления, один путь обходит “s” и направляется к последнему прямоугольнику с границей слова, а второй проходит через “s”. У нас есть “s”, поэтому мы идём туда.
• на позиции 10 мы в конце строки, и совпасть может только граница слова. Конец строки считается границей, и мы проходим через последний прямоугольник. И вот мы успешно нашли наш шаблон.
В принципе, работают регулярные выражения следующим образом: алгоритм начинает в начале строки и пытается найти совпадение там. В нашем случае там есть граница слова, поэтому он проходит первый прямоугольник – но там нет цифры, поэтому на втором прямоугольнике он спотыкается. Потом он двигается ко второму символу в строке, и пытается найти совпадение там… И так далее, пока он не находит совпадение или не доходит до конца строки, в таком случае совпадение не найдено.
Откаты
Регулярка /\b([01]+b|\d+|[\da-f]h)\b/совпадает либо с двоичным числом, за которым следует b, либо с десятичным числом без суффикса, либо шестнадцатеричным (цифры от 0 до 9 или символы от a до f), за которым идёт h. Соответствующая диаграмма:
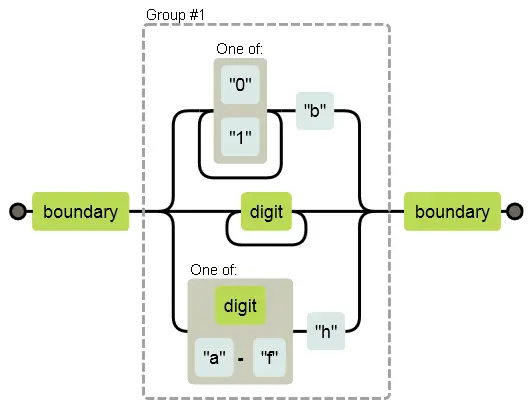
В поисках совпадения может случиться, что алгоритм пошёл по верхнему пути (двоичное число), даже если в строке нет такого числа. Если там есть строка “103”, например, понятно, что только достигнув цифры 3 алгоритм поймёт, что он на неправильном пути. Вообще строка совпадает с регуляркой, просто не в этой ветке.
Тогда алгоритм совершает откат. На развилке он запоминает текущее положение (в нашем случае, это начало строки, сразу после границы слова), чтобы можно было вернуться назад и попробовать другой путь, если выбранный не срабатывает. Для строки “103”после встречи с тройкой он вернётся и попытается пройти путь для десятичных чисел. Это сработает, поэтому совпадение будет найдено.
Интервал:
Закладка:
Похожие книги на «Выразительный JavaScript»
Представляем Вашему вниманию похожие книги на «Выразительный JavaScript» списком для выбора. Мы отобрали схожую по названию и смыслу литературу в надежде предоставить читателям больше вариантов отыскать новые, интересные, ещё непрочитанные произведения.










Обсуждение, отзывы о книге «Выразительный JavaScript» и просто собственные мнения читателей. Оставьте ваши комментарии, напишите, что Вы думаете о произведении, его смысле или главных героях. Укажите что конкретно понравилось, а что нет, и почему Вы так считаете.