Энтони Уильямс - Параллельное программирование на С++ в действии. Практика разработки многопоточных программ
Здесь есть возможность читать онлайн «Энтони Уильямс - Параллельное программирование на С++ в действии. Практика разработки многопоточных программ» весь текст электронной книги совершенно бесплатно (целиком полную версию без сокращений). В некоторых случаях можно слушать аудио, скачать через торрент в формате fb2 и присутствует краткое содержание. Город: Москва, Год выпуска: 2012, ISBN: 2012, Издательство: ДМК Пресс, Жанр: Программирование, на русском языке. Описание произведения, (предисловие) а так же отзывы посетителей доступны на портале библиотеки ЛибКат.

- Название:Параллельное программирование на С++ в действии. Практика разработки многопоточных программ
- Автор:
- Издательство:ДМК Пресс
- Жанр:
- Год:2012
- Город:Москва
- ISBN:978-5-94074-448-1
- Рейтинг книги:4 / 5. Голосов: 1
-
Избранное:Добавить в избранное
- Отзывы:
-
Ваша оценка:
Параллельное программирование на С++ в действии. Практика разработки многопоточных программ: краткое содержание, описание и аннотация
Предлагаем к чтению аннотацию, описание, краткое содержание или предисловие (зависит от того, что написал сам автор книги «Параллельное программирование на С++ в действии. Практика разработки многопоточных программ»). Если вы не нашли необходимую информацию о книге — напишите в комментариях, мы постараемся отыскать её.
Книга «Параллельное программирование на С++ в действии» не предполагает предварительных знаний в этой области. Вдумчиво читая ее, вы научитесь писать надежные и элегантные многопоточные программы на С++11. Вы узнаете о том, что такое потоковая модель памяти, и о том, какие средства поддержки многопоточности, в том числе запуска и синхронизации потоков, имеются в стандартной библиотеке. Попутно вы познакомитесь с различными нетривиальными проблемами программирования в условиях параллелизма.
Параллельное программирование на С++ в действии. Практика разработки многопоточных программ — читать онлайн бесплатно полную книгу (весь текст) целиком
Ниже представлен текст книги, разбитый по страницам. Система сохранения места последней прочитанной страницы, позволяет с удобством читать онлайн бесплатно книгу «Параллельное программирование на С++ в действии. Практика разработки многопоточных программ», без необходимости каждый раз заново искать на чём Вы остановились. Поставьте закладку, и сможете в любой момент перейти на страницу, на которой закончили чтение.
Интервал:
Закладка:
if (data_queue.empty())
return false;
value = std::move(*data_queue.front()); ← (2)
data_queue.pop();
return true;
}
std::shared_ptr wait_and_pop() {
std::unique_lock lk(mut);
data_cond.wait(lk, [this]{return !data_queue.empty();});
std::shared_ptr res = data_queue.front(); ← (3)
data_queue.pop();
return res;
}
std::shared_ptr try_pop() {
std::lock_guard lk(mut);
if (data_queue.empty())
return std::shared_ptr();
std::shared_ptr res = data_queue.front(); ← (4)
data_queue.pop();
return res;
}
void push(T new_value) {
std::shared_ptr data(
std::make_shared(std::move(new_value))); ← (5)
std::lock_guard lk(mut);
data_queue.push(data);
data_cond.notify_one();
}
bool empty() const {
std::lock_guard lk(mut);
return data_queue.empty();
}
};
Последствия хранения данных, обернутых в std::shared_ptr<>, понятны: функции pop, которые получают значение из очереди в виде ссылки на переменную, теперь должны разыменовывать указатель (1), (2), а функции pop, которые возвращают std::shared_ptr<>, теперь могут напрямую извлекать его из очереди (3), (4)без дальнейших манипуляций.
У хранения данных в виде std::shared_ptr<>есть и еще одно преимущество: выделение памяти для нового объекта можно производить не под защитой блокировки в push() (5), тогда как в листинге 6.2 это приходилось делать в защищенном участке кода внутри pop(). Поскольку выделение памяти, вообще говоря, дорогая операция, это изменение весьма благотворно скажется на общей производительности очереди, так как уменьшается время удержания мьютекса, а, значит, у остальных потоков остается больше времени на полезную работу.
Как и в примере стека, применение мьютекса для защиты всей структуры данных ограничивает возможности распараллеливания работы с очередью; хотя ожидать доступа к очереди могут несколько потоков, выполняющих разные функции, в каждый момент лишь один совершает какие-то действия. Однако это ограничение отчасти проистекает из того, что мы пользуемся классом std::queue<>, — стандартный контейнер составляет единый элемент данных, который либо защищен, либо нет. Полностью взяв на себя управление деталями реализации структуры данных, мы сможем обеспечить мелкогранулярные блокировки и повысить уровень параллелизма.
6.2.3. Потокобезопасная очередь с мелкогранулярными блокировками и условными переменными
В листингах 6.2 и 6.3 имеется только один защищаемый элемент данных ( data_queue) и, следовательно, только один мьютекс. Чтобы воспользоваться мелкогранулярными блокировками, мы должны заглянуть внутрь очереди и связать мьютекс с каждым хранящимся в ней элементом данных.
Проще всего реализовать очередь в виде односвязного списка, как показано на рис. 6.1. Указатель head направлен на первый элемент списка, и каждый элемент указывает на следующий. Когда данные извлекаются из очереди, в head записывается указатель на следующий элемент, после чего возвращается элемент, который до этого был в начале.
Добавление данных производится с другого конца. Для этого нам необходим указатель tail , направленный на последний элемент списка. Чтобы добавить узел, мы записываем в поле next в последнем элементе указатель на новый узел, после чего изменяем указатель tail , так чтобы он адресовал новый элемент. Если список пуст, то оба указателя head и tail равны NULL.
В следующем листинге показана простая реализация такой очереди с урезанным по сравнению с листингом 6.2 интерфейсом; мы оставили только функцию try_pop()и убрали функцию wait_and_pop(), потому что эта очередь поддерживает только однопоточную работу.
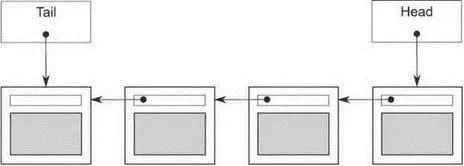
Рис. 6.1.Очередь, представленная в виде односвязного списка
Листинг 6.4.Простая реализация однопоточной очереди
template
class queue {
private:
struct node {
T data;
std::unique_ptr next;
node(T data_):
data(std::move(data_)) {}
};
std::unique_ptr head;← (1)
node* tail; ← (2)
public:
queue() {}
queue(const queue& other) = delete;
queue& operator=(const queue& other) = delete;
std::shared_ptr try_pop() {
if (!head) {
return std::shared_ptr();
}
std::shared_ptr const res(
std::make_shared(std::move(head->data)));
Интервал:
Закладка:
Похожие книги на «Параллельное программирование на С++ в действии. Практика разработки многопоточных программ»
Представляем Вашему вниманию похожие книги на «Параллельное программирование на С++ в действии. Практика разработки многопоточных программ» списком для выбора. Мы отобрали схожую по названию и смыслу литературу в надежде предоставить читателям больше вариантов отыскать новые, интересные, ещё непрочитанные произведения.











Обсуждение, отзывы о книге «Параллельное программирование на С++ в действии. Практика разработки многопоточных программ» и просто собственные мнения читателей. Оставьте ваши комментарии, напишите, что Вы думаете о произведении, его смысле или главных героях. Укажите что конкретно понравилось, а что нет, и почему Вы так считаете.