Энтони Уильямс - Параллельное программирование на С++ в действии. Практика разработки многопоточных программ
Здесь есть возможность читать онлайн «Энтони Уильямс - Параллельное программирование на С++ в действии. Практика разработки многопоточных программ» весь текст электронной книги совершенно бесплатно (целиком полную версию без сокращений). В некоторых случаях можно слушать аудио, скачать через торрент в формате fb2 и присутствует краткое содержание. Город: Москва, Год выпуска: 2012, ISBN: 2012, Издательство: ДМК Пресс, Жанр: Программирование, на русском языке. Описание произведения, (предисловие) а так же отзывы посетителей доступны на портале библиотеки ЛибКат.

- Название:Параллельное программирование на С++ в действии. Практика разработки многопоточных программ
- Автор:
- Издательство:ДМК Пресс
- Жанр:
- Год:2012
- Город:Москва
- ISBN:978-5-94074-448-1
- Рейтинг книги:4 / 5. Голосов: 1
-
Избранное:Добавить в избранное
- Отзывы:
-
Ваша оценка:
Параллельное программирование на С++ в действии. Практика разработки многопоточных программ: краткое содержание, описание и аннотация
Предлагаем к чтению аннотацию, описание, краткое содержание или предисловие (зависит от того, что написал сам автор книги «Параллельное программирование на С++ в действии. Практика разработки многопоточных программ»). Если вы не нашли необходимую информацию о книге — напишите в комментариях, мы постараемся отыскать её.
Книга «Параллельное программирование на С++ в действии» не предполагает предварительных знаний в этой области. Вдумчиво читая ее, вы научитесь писать надежные и элегантные многопоточные программы на С++11. Вы узнаете о том, что такое потоковая модель памяти, и о том, какие средства поддержки многопоточности, в том числе запуска и синхронизации потоков, имеются в стандартной библиотеке. Попутно вы познакомитесь с различными нетривиальными проблемами программирования в условиях параллелизма.
Параллельное программирование на С++ в действии. Практика разработки многопоточных программ — читать онлайн бесплатно полную книгу (весь текст) целиком
Ниже представлен текст книги, разбитый по страницам. Система сохранения места последней прочитанной страницы, позволяет с удобством читать онлайн бесплатно книгу «Параллельное программирование на С++ в действии. Практика разработки многопоточных программ», без необходимости каждый раз заново искать на чём Вы остановились. Поставьте закладку, и сможете в любой момент перейти на страницу, на которой закончили чтение.
Интервал:
Закладка:
С++ используется для решения разных задач, но одна из основных — системное программирование. Поэтому комитет по стандартизации в числе прочих целей ставил и такую: сделать так, чтобы в языке более низкого уровня, чем С++, не возникало необходимости. С++ должен обладать достаточной гибкостью, чтобы программист мог сделать то, что хочет, без помех со стороны языка, в том числе и работать «на уровне железа». Атомарные типы и операции — шаг именно в этом направлении, поскольку они предоставляют низкоуровневые механизмы синхронизации, которые обычно транслируются в одну-две машинные команды.
В этой главе мы начнем с рассмотрения основ модели памяти, затем перейдем к атомарным типам и операциям и в конце обсудим различные виды синхронизации, реализуемые с помощью операций над атомарными типами. Это довольно сложная тема; если вы не планируете писать код, в котором атомарные операции используются для синхронизации (например, структуры данных без блокировок, рассматриваемые в главе 7), то все эти детали вам ни к чему. Но давайте потихоньку двинемся вперёд и начнем с модели памяти.
5.1. Основы модели памяти
У модели памяти есть две стороны: базовые структурные аспекты, относящиеся к размещению программы в памяти, и аспекты, связанные с параллелизмом. Структурные аспекты важны для параллелизма, особенно если опуститься на низкий уровень атомарных операций, поэтому с них я и начну. В С++ всё вращается вокруг объектов и ячеек памяти.
5.1.1. Объекты и ячейки памяти
Любые данные в программе на С++ состоят из объектов. Это не значит, что можно создать новый класс, производный от int, или что у фундаментальных типов есть функции-члены, или вообще нечто такое, что часто имеют в виду, когда говорят «нет ничего, кроме объектов» при обсуждении таких языков, как Smalltalk или Ruby. Это утверждение просто означает, что в С++ данные строятся из объектов. В стандарте С++ объект определяется как «область памяти», хотя далее речь идет о таких свойствах объектов, как тип и время жизни.
Некоторые объекты являются простыми значениями таких фундаментальных типов, как intили float, другие — экземплярами определенных пользователем классов. У некоторых объектов (например, массивов, экземпляров производных классов и экземпляров классов с нестатическими данными-членами) есть подобъекты, у других — нет.
Вне зависимости от типа объект хранится в одной или нескольких ячейках памяти . Каждая такая ячейка — это либо объект (или подобъект) скалярного типа, например unsigned shortили my_class*, либо последовательность соседних битовых полей. Если вы пользуетесь битовыми полями, то имейте в виду один важный момент: хотя соседние битовые поля является различными объектами, они тем не менее считаются одной ячейкой памяти. На рис. 5.1 показано, как структура structпредставлена в виде совокупности объектов и ячеек памяти.
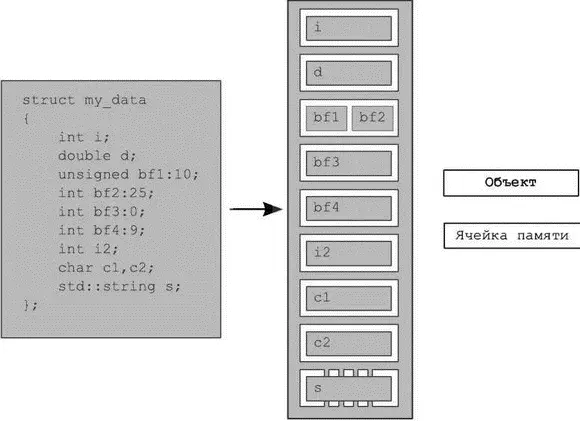
Рис. 5.1.Разбиение structна объекты и ячейки памяти
Во-первых, вся структура — это один объект, который состоит из нескольких подобъектом, по одному для каждого члена данных. Битовые поля bf1и bf2занимают одну ячейку памяти, объект sтипа std::stringзанимает несколько ячеек памяти, а для каждого из остальных членов отведена своя ячейка. Обратите внимание, что битовое поле нулевой длины bf3заставляет отвести для bf4отдельную ячейку.
Отсюда можно сделать несколько важных выводов:
• каждая переменная — объект, в том числе и переменные, являющиеся членами других объектов;
• каждый объект занимает по меньшей мере одну ячейку памяти;
• переменные фундаментальных типов, например intили char, занимают в точности одну ячейку памяти вне зависимости от размера, даже если являются соседними или элементами массива;
• соседние битовые поля размещаются в одной ячейке памяти.
Уверен, что вы недоумеваете, какое отношение всё это имеет к параллелизму. Давайте разберемся.
5.1.2. Объекты, ячейки памяти и параллелизм
Для многопоточных приложений на С++ понятие ячейки памяти критически важно. Если два потока обращаются к разным ячейкам памяти, то никаких проблем не возникает и всё работает, как надо. Но если потоки обращаются к одной и той же ячейке, то необходима осторожность. Если ни один поток не обновляет ячейку памяти, то всё хорошо — доступ к данным для чтения не нуждается ни в защите, ни в синхронизации. Если же какой-то поток модифицирует данные, то возможно состояние гонки, описанное в главе 3.
Читать дальшеИнтервал:
Закладка:
Похожие книги на «Параллельное программирование на С++ в действии. Практика разработки многопоточных программ»
Представляем Вашему вниманию похожие книги на «Параллельное программирование на С++ в действии. Практика разработки многопоточных программ» списком для выбора. Мы отобрали схожую по названию и смыслу литературу в надежде предоставить читателям больше вариантов отыскать новые, интересные, ещё непрочитанные произведения.











Обсуждение, отзывы о книге «Параллельное программирование на С++ в действии. Практика разработки многопоточных программ» и просто собственные мнения читателей. Оставьте ваши комментарии, напишите, что Вы думаете о произведении, его смысле или главных героях. Укажите что конкретно понравилось, а что нет, и почему Вы так считаете.