Энтони Уильямс - Параллельное программирование на С++ в действии. Практика разработки многопоточных программ
Здесь есть возможность читать онлайн «Энтони Уильямс - Параллельное программирование на С++ в действии. Практика разработки многопоточных программ» весь текст электронной книги совершенно бесплатно (целиком полную версию без сокращений). В некоторых случаях можно слушать аудио, скачать через торрент в формате fb2 и присутствует краткое содержание. Город: Москва, Год выпуска: 2012, ISBN: 2012, Издательство: ДМК Пресс, Жанр: Программирование, на русском языке. Описание произведения, (предисловие) а так же отзывы посетителей доступны на портале библиотеки ЛибКат.

- Название:Параллельное программирование на С++ в действии. Практика разработки многопоточных программ
- Автор:
- Издательство:ДМК Пресс
- Жанр:
- Год:2012
- Город:Москва
- ISBN:978-5-94074-448-1
- Рейтинг книги:4 / 5. Голосов: 1
-
Избранное:Добавить в избранное
- Отзывы:
-
Ваша оценка:
Параллельное программирование на С++ в действии. Практика разработки многопоточных программ: краткое содержание, описание и аннотация
Предлагаем к чтению аннотацию, описание, краткое содержание или предисловие (зависит от того, что написал сам автор книги «Параллельное программирование на С++ в действии. Практика разработки многопоточных программ»). Если вы не нашли необходимую информацию о книге — напишите в комментариях, мы постараемся отыскать её.
Книга «Параллельное программирование на С++ в действии» не предполагает предварительных знаний в этой области. Вдумчиво читая ее, вы научитесь писать надежные и элегантные многопоточные программы на С++11. Вы узнаете о том, что такое потоковая модель памяти, и о том, какие средства поддержки многопоточности, в том числе запуска и синхронизации потоков, имеются в стандартной библиотеке. Попутно вы познакомитесь с различными нетривиальными проблемами программирования в условиях параллелизма.
Параллельное программирование на С++ в действии. Практика разработки многопоточных программ — читать онлайн бесплатно полную книгу (весь текст) целиком
Ниже представлен текст книги, разбитый по страницам. Система сохранения места последней прочитанной страницы, позволяет с удобством читать онлайн бесплатно книгу «Параллельное программирование на С++ в действии. Практика разработки многопоточных программ», без необходимости каждый раз заново искать на чём Вы остановились. Поставьте закладку, и сможете в любой момент перейти на страницу, на которой закончили чтение.
Интервал:
Закладка:
Есть и другой путь — нанять бригаду узких специалистов: каменщика, плотника, электрика, водопроводчика и других. Специалисты делают то, что лучше всего умеют, так что если прокладывать трубы не надо, то водопроводчик попивает чаёк. Работа все равно продвигается быстрее, так как занято больше людей, — водопроводчик может заниматься туалетом, пока электрик делает проводку на кухне, но зато когда для конкретного специалиста работы нет, он простаивает. Впрочем, несмотря на простои, специалисты, скорее всего, справятся быстрее, чем бригада мастеров на все руки. Им не нужно менять инструменты, да и свое дело они по идее должны делать быстрее, чем универсалы. Так ли это на самом деле, зависит от разных обстоятельств — нет другого пути, как взять и попробовать.
Но и специалистов можно нанять много или мало. Наверное, имеет смысл нанимать больше каменщиков, чем электриков. Кроме того, состав бригады и ее общая эффективность могут измениться, если предстоит построить несколько домов. Если в одном доме у водопроводчика мало работы, то на строительстве нескольких его можно занять полностью. Наконец, если вы не обязаны платить специалистам за простой, то можно позволить себе нанять больше людей, пусть даже в каждый момент времени работать будет столько же, сколько раньше.
Но хватит уже о строительстве, какое отношение всё это имеет к потокам? Да просто к ним применимы те же соображения. Нужно решить, сколько использовать потоков и какие задачи поручить каждому Должны ли потоки быть «универсалами», берущимися за любую подвернувшуюся работу или «специалистами», которые умеют хорошо делать одно дело? Или, быть может, нужно сочетание того и другого? Эти решения необходимо принимать вне зависимости от причин распараллеливания программы и от того, насколько они будут удачны, существенно зависит производительность и ясность кода. Поэтому так важно понимать, какие имеются варианты; тогда решения о структуре приложения будут опираться на знания, а не браться с потолка. В этом разделе мы рассмотрим несколько методов распределения задач и начнем с распределения данных между потоками.
8.1.1. Распределение данных между потоками до начала обработки
Легче всего распараллеливаются такие простые алгоритмы, как std::for_each, которые производят некоторую операцию над каждым элементом набора данных. Чтобы распараллелить такой алгоритм, можно назначить каждому элементу один из обрабатывающих потоков. Каким образом распределить элементы для достижения оптимальной производительности, зависит от деталей структуры данных, как мы убедимся ниже в этой главе.
Простейший способ распределения данных заключается в том, чтобы назначить первые N элементов одному потоку, следующие N — другому и так далее, как показано на рис. 8.1, хотя это и не единственное решение. Как бы ни были распределены данные, каждый поток обрабатывает только назначенные ему элементы, никак не взаимодействуя с другими потоками до тех пор, пока не завершит обработку.
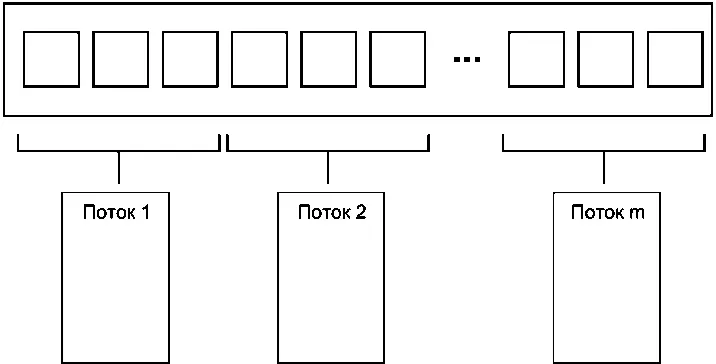
Рис. 8.1.Распределение последовательных блоков данных между потоками
Такая организация программы знакома каждому, кто программировал в системах Message Passing Interface (МРI) [17] http://www.mpi-forum.org/
или OpenMP [18] http://www.openmp.org/
: задача разбивается на множество параллельных подзадач, рабочие потоки выполняют их параллельно, а затем результаты объединяются на стадии редукции . Этот подход применён в примере функции accumulateиз раздела 2.4; в данном случае и параллельные задачи, и финальный шаг редукции представляют собой аккумулирование. Для простого алгоритма for_eachфинальный шаг отсутствует, так как нечего редуцировать.
Понимание того, что последний шаг является редукцией, важно; в наивной реализации, представленной в листинге 2.8, финальная редукция выполняется как последовательная операция. Однако часто и ее можно распараллелить; операция accumulateпо сути дела сама является редукцией, поэтому функцию из листинга 2.8 можно модифицировать таким образом, чтобы она вызывала себя рекурсивно, если, например, число потоков больше минимального количества элементов, обрабатываемых одним потоком. Или запрограммировать рабочие потоки так, чтобы по завершении задачи они выполняли некоторые шаги редукции, а не запускать каждый раз новые потоки.
Интервал:
Закладка:
Похожие книги на «Параллельное программирование на С++ в действии. Практика разработки многопоточных программ»
Представляем Вашему вниманию похожие книги на «Параллельное программирование на С++ в действии. Практика разработки многопоточных программ» списком для выбора. Мы отобрали схожую по названию и смыслу литературу в надежде предоставить читателям больше вариантов отыскать новые, интересные, ещё непрочитанные произведения.











Обсуждение, отзывы о книге «Параллельное программирование на С++ в действии. Практика разработки многопоточных программ» и просто собственные мнения читателей. Оставьте ваши комментарии, напишите, что Вы думаете о произведении, его смысле или главных героях. Укажите что конкретно понравилось, а что нет, и почему Вы так считаете.