Дмитрий Красота - Введение в Python
Здесь есть возможность читать онлайн «Дмитрий Красота - Введение в Python» весь текст электронной книги совершенно бесплатно (целиком полную версию без сокращений). В некоторых случаях можно слушать аудио, скачать через торрент в формате fb2 и присутствует краткое содержание. Жанр: Программирование, на русском языке. Описание произведения, (предисловие) а так же отзывы посетителей доступны на портале библиотеки ЛибКат.
- Название:Введение в Python
- Автор:
- Жанр:
- Год:неизвестен
- ISBN:нет данных
- Рейтинг книги:4.21 / 5. Голосов: 14
-
Избранное:Добавить в избранное
- Отзывы:
-
Ваша оценка:
Введение в Python: краткое содержание, описание и аннотация
Предлагаем к чтению аннотацию, описание, краткое содержание или предисловие (зависит от того, что написал сам автор книги «Введение в Python»). Если вы не нашли необходимую информацию о книге — напишите в комментариях, мы постараемся отыскать её.
--------
Файл изготовлен по материалам сайта http://pythonicway.com/
Введение в Python — читать онлайн бесплатно полную книгу (весь текст) целиком
Ниже представлен текст книги, разбитый по страницам. Система сохранения места последней прочитанной страницы, позволяет с удобством читать онлайн бесплатно книгу «Введение в Python», без необходимости каждый раз заново искать на чём Вы остановились. Поставьте закладку, и сможете в любой момент перейти на страницу, на которой закончили чтение.
Интервал:
Закладка:
1 | try:
2 | a =float(input ("Введите число: ")
3 | print (100 / a)
4 | except ValueError:
5 | print ("Это не число")
6 | except ZeroDivisionError:
7 | print ("На ноль делить нельзя")
8 | except:
9 | print ("Неожиданная ошибка.")
10 | else:
11 | print ("Код выполнился без ошибок")
В результате, мы получим следующее.
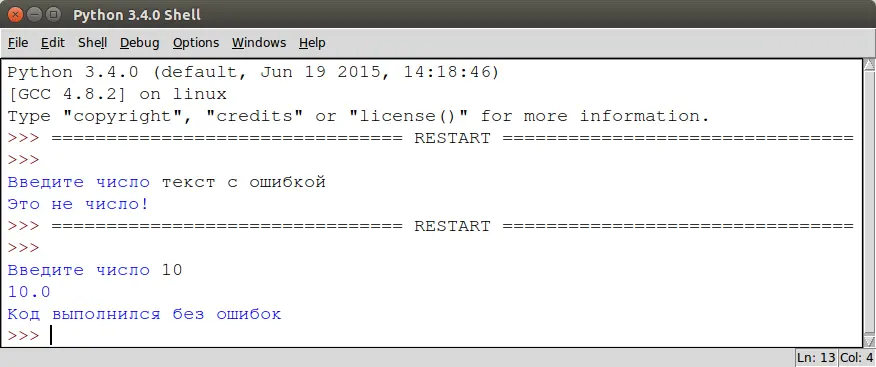
Также у блока except есть еще один необязательный блок finally, который сработает независимо от того, выполнился код с ошибками или без:
1 | try:
2 | a =float(input ("Введите число: ")
3 | print (100 / a)
4 | except ValueError:
5 | print ("Это не число")
6 | except ZeroDivisionError:
7 | print ("На ноль делить нельзя")
8 | except:
9 | print ("Неожиданная ошибка.")
10 | else:
11 | print ("Код выполнился без ошибок")
12 | finally:
13 | print ("Я выполняюсь в любом случае!")
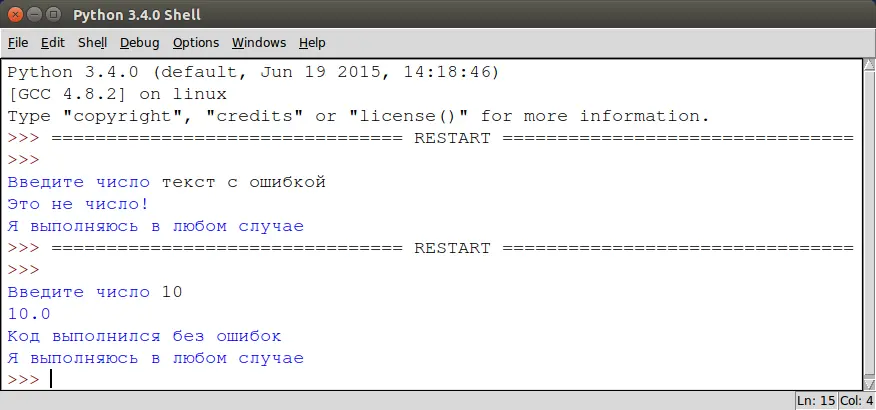
Таким образом, используя обработку исключительных ситуаций, вы можете защитить программу от взлома, непредвиденного поведения и в будущем получить детальную информацию по логическим ошибкам, содержащимся в ней.
HTML парсер на Python
Published: 08 April 2015
Учитывая современное развитие Интернета, было бы кощунством не написать приложение, взаимодействующее со всемирной паутиной. Сегодня мы напишем простенький html-парсер на Python. Наше приложение будет читать код указанной страницы сайта и сохранять все ссылки в ней в отдельный файл. Это приложение может помочь SEO-аналитикам и веб-разработчикам.
Писать будем на Python 3, в котором есть встроенный класс для html-парсера из модуля html.parser
| from html.parser import HTMLParser
Так же нам понадобится функция urlopen из модуля urllib
| from urllib.request import urlopen
Именно функция urlopen будет получать исходный код указанной странички.
Наша задача таким образом перегрузить функционал существующего класса HTMLParser, чтобы он соответствовал нашей задаче.
| class MyHTMLParser(HTMLParser):
| def __init__(self, site_name, * args, * * kwargs):
| # список ссылок
| self.links = []
| # имя сайта
| self.site_name = site_name
| # вызываем __init__ родителя
| super().__init__( * args, * * kwargs)
| # при инициализации "скармливаем" парсеру содержимое страницы
| self.feed(self.read_site_content())
| # записываем список ссылок в файл
self.write_to_file()
Базовый класс HTMLParser имеет несколько методов, нас в данном случае интересуют метод handle_start_tag. Этот метод вызывается каждый раз, когда наш парсер встречает в тексте октрывающий html-тэг.
| def handle_starttag(self, tag, attrs):
| # проверяем является ли тэг тэгом ссылки
| if tag == 'a':
| # находим аттрибут адреса ссылки
| for attr in attrs:
| if attr[0] = = 'href':
| # проверяем эту ссылку методом validate() (мы его еще напишем)
| if not self.validate(attr[0]):
| # вставляем адрес в список ссылок
self.links.append(attr[1])
Напишем вспомогательный метод validate:
| def validate(self, link):
| """ Функция проверяет стоит ли добавлять ссылку в список адресов.
| В список адресов стоит добавлять если ссылка:
| 1) Еще не в списке ссылок
| 2) Не вызывает javascript-код
| 3) Не ведет к какой-либо метке. (Не содержит #)
| """
return link in self.links or'#'inlink or'javascript:' inlink
Создадим метод, который будет открывать указанную страницу и выдавать ее содержимое.
def read_site_content(self):
return str(urlopen(self.site_name).read())
Осталось добавить возможность записи списка ссылок на диск в читабельном формате:
| def write_to_file(self):
| # открываем файл
| f =open('links.txt', 'w')
| # записываем отсортированный список ссылок, каждая с новой строки
| f.write('\n'.join(sorted(self.links)))
| # закрываем файл
f.close()
Все готово, можем запускать парсер.
| parser = MyHTMLParser("http://python.org")
После того как вы запустите данный скрипт в директории, где находится ваш файл появится текстовый документ links.txt, содержащий ссылки.
Конечно, данный пример достаточно примитивен, но на его основе вы можете попробовать написать, к примеру, веб-crawler, который будет анализировать весь сайт целиком, а не одну его страницу.
Читать дальшеИнтервал:
Закладка:
Похожие книги на «Введение в Python»
Представляем Вашему вниманию похожие книги на «Введение в Python» списком для выбора. Мы отобрали схожую по названию и смыслу литературу в надежде предоставить читателям больше вариантов отыскать новые, интересные, ещё непрочитанные произведения.











Обсуждение, отзывы о книге «Введение в Python» и просто собственные мнения читателей. Оставьте ваши комментарии, напишите, что Вы думаете о произведении, его смысле или главных героях. Укажите что конкретно понравилось, а что нет, и почему Вы так считаете.