Алексей Молчанов - Системное программное обеспечение. Лабораторный практикум
Здесь есть возможность читать онлайн «Алексей Молчанов - Системное программное обеспечение. Лабораторный практикум» — ознакомительный отрывок электронной книги совершенно бесплатно, а после прочтения отрывка купить полную версию. В некоторых случаях можно слушать аудио, скачать через торрент в формате fb2 и присутствует краткое содержание. Город: Санкт-Петербург, Год выпуска: 2005, ISBN: 2005, Издательство: Array Издательство «Питер», Жанр: Программирование, на русском языке. Описание произведения, (предисловие) а так же отзывы посетителей доступны на портале библиотеки ЛибКат.

- Название:Системное программное обеспечение. Лабораторный практикум
- Автор:
- Издательство:Array Издательство «Питер»
- Жанр:
- Год:2005
- Город:Санкт-Петербург
- ISBN:978-5-469-00391-4
- Рейтинг книги:4 / 5. Голосов: 2
-
Избранное:Добавить в избранное
- Отзывы:
-
Ваша оценка:
Системное программное обеспечение. Лабораторный практикум: краткое содержание, описание и аннотация
Предлагаем к чтению аннотацию, описание, краткое содержание или предисловие (зависит от того, что написал сам автор книги «Системное программное обеспечение. Лабораторный практикум»). Если вы не нашли необходимую информацию о книге — напишите в комментариях, мы постараемся отыскать её.
Книга ориентирована на студентов, обучающихся в технических вузах по специальностям, связанным с вычислительной техникой. Но она будет также полезна всем, чья деятельность так или иначе касается разработки программного обеспечения.
Системное программное обеспечение. Лабораторный практикум — читать онлайн ознакомительный отрывок
Ниже представлен текст книги, разбитый по страницам. Система сохранения места последней прочитанной страницы, позволяет с удобством читать онлайн бесплатно книгу «Системное программное обеспечение. Лабораторный практикум», без необходимости каждый раз заново искать на чём Вы остановились. Поставьте закладку, и сможете в любой момент перейти на страницу, на которой закончили чтение.
Интервал:
Закладка:
• Пример выполнения разбора простейшего предложения входного языка.
• Текст программы (оформляется после выполнения программы на ЭВМ).
Основные контрольные вопросы
• Какую роль выполняет синтаксический анализ в процессе компиляции?
• Какие проблемы возникают при построении синтаксического анализатора и как они могут быть решены?
• Какие типы грамматик существуют? Что такое КС-грамматики? Расскажите об их использовании в компиляторе.
• Какие типы распознавателей для КС-грамматик существуют? Расскажите о недостатках и преимуществах различных типов распознавателей.
• Поясните правила построения дерева вывода грамматики.
• Что такое грамматики простого предшествования?
• Как вычисляются отношения предшествования для грамматик простого предшествования?
• Что такое грамматика операторного предшествования?
• Как вычисляются отношения для грамматик операторного предшествования?
• Расскажите о задаче разбора. Что такое распознаватель языка?
• Расскажите об общих принципах работы распознавателя языка.
• Что такое перенос, свертка? Для чего необходим алгоритм «перенос-свертка»?
• Расскажите, как работает алгоритм «перенос-свертка» в общем случае (с возвратами).
• Как работает алгоритм «перенос-свертка» без возвратов (объясните на своем примере)?
Варианты заданий
Варианты исходных грамматик
Далее приведены варианты грамматик. Во всех вариантах символ S является начальным символом грамматики; S, F, T и Е обозначают нетерминальные символы.
Терминальные символы выделены жирным шрифтом. Вместо символа а должны подставляться лексемы.
1. S → a:= F;
F → F+T |Т
Т → Т·Е | TIE | Е
Е → (F) | – (F) | а
2. S → a:= F;
F → F or Т | F хог T | T
T → Т and E | Е
Е → (F) | not (F) | a
3. S → F;
F → if E then T else F| if E then F| a:= a
T → if E then T else T | a:= a
E → aa | a=a
4. S → F;
F → for (T) do F | a:= a
T → F;E;F |;E;F | F;E; |;E;
E → a
a I a=aИсходные грамматики и типы допустимых лексем
Ниже в табл. 3.1 приведены номера заданий. Для каждого задания указана соответствующая ему грамматика и типы допустимых лексем.

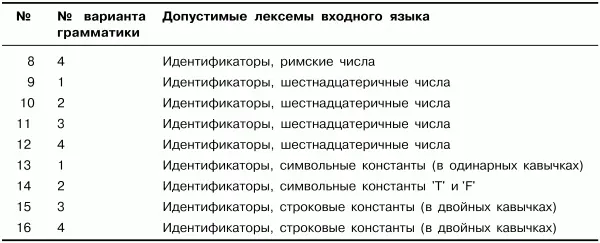
Примечание.
• Римскими числами считать последовательности больших латинских букв X, V и I.
• Шестнадцатеричными числами считать последовательность цифр и символов «а», «Ь», «с», «d», «е» и «f», начинающуюся с цифры (например: 89, 45ас9, 0abc4).
• Для выполнения работы рекомендуется использовать лексический анализатор, построенный в ходе выполнения лабораторной работы № 2.
Пример выполнения работы
Задание для примера
Для выполнения лабораторной работы возьмем тот же самый язык, который был использован для выполнения лабораторной работы № 2.
Этот язык может быть задан, например, с помощью следующей КС-грамматики
G({if,then,else,a,=,or,xor,and,(,),},{ S,F,E,D,C },P, S ) с правилами P:
S → F ;
F → if E then T else F | if E then F | a:= E
T → if E then T else T | a:= E
E → E or D | E xor D | D
D → D and C | C
C → a | ( E )
Жирным шрифтом в грамматике и в правилах выделены терминальные символы.
Как было уже сказано ранее, выбранный в качестве примера язык не совпадает ни с одним из предложенных выше вариантов и, кроме этого, служит хорошей иллюстрацией основных особенностей построения синтаксического распознавателя, присущих различным вариантам.
Построение матрицы операторного предшествования
Построение множеств крайних левых и крайних правых символов выполним согласно описанному ранее алгоритму.
На первом шаге возьмем все крайние левые и крайние правые символы из правил грамматики G. Получим множества, представленные в табл. 3.2.
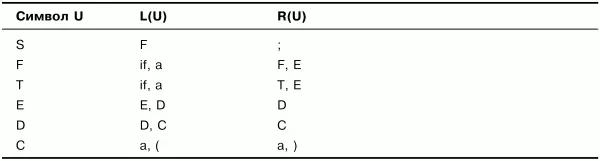
Из табл. 3.2 видно, что множества L(U) для символов S, Е, D, а также множества R(U) для символов F, Т, Е, D содержат другие нетерминальные символы, а потому должны быть дополнены. Например, L(S) должно быть дополнено L(F), так как символ F входит в L(S): F е L(S), а R(F) должно быть дополнено R(E), так как символ Е входит в R(F): Е е R(F).
Читать дальшеИнтервал:
Закладка:
Похожие книги на «Системное программное обеспечение. Лабораторный практикум»
Представляем Вашему вниманию похожие книги на «Системное программное обеспечение. Лабораторный практикум» списком для выбора. Мы отобрали схожую по названию и смыслу литературу в надежде предоставить читателям больше вариантов отыскать новые, интересные, ещё непрочитанные произведения.









Обсуждение, отзывы о книге «Системное программное обеспечение. Лабораторный практикум» и просто собственные мнения читателей. Оставьте ваши комментарии, напишите, что Вы думаете о произведении, его смысле или главных героях. Укажите что конкретно понравилось, а что нет, и почему Вы так считаете.