Алексей Молчанов - Системное программное обеспечение. Лабораторный практикум
Здесь есть возможность читать онлайн «Алексей Молчанов - Системное программное обеспечение. Лабораторный практикум» — ознакомительный отрывок электронной книги совершенно бесплатно, а после прочтения отрывка купить полную версию. В некоторых случаях можно слушать аудио, скачать через торрент в формате fb2 и присутствует краткое содержание. Город: Санкт-Петербург, Год выпуска: 2005, ISBN: 2005, Издательство: Array Издательство «Питер», Жанр: Программирование, на русском языке. Описание произведения, (предисловие) а так же отзывы посетителей доступны на портале библиотеки ЛибКат.

- Название:Системное программное обеспечение. Лабораторный практикум
- Автор:
- Издательство:Array Издательство «Питер»
- Жанр:
- Год:2005
- Город:Санкт-Петербург
- ISBN:978-5-469-00391-4
- Рейтинг книги:4 / 5. Голосов: 2
-
Избранное:Добавить в избранное
- Отзывы:
-
Ваша оценка:
Системное программное обеспечение. Лабораторный практикум: краткое содержание, описание и аннотация
Предлагаем к чтению аннотацию, описание, краткое содержание или предисловие (зависит от того, что написал сам автор книги «Системное программное обеспечение. Лабораторный практикум»). Если вы не нашли необходимую информацию о книге — напишите в комментариях, мы постараемся отыскать её.
Книга ориентирована на студентов, обучающихся в технических вузах по специальностям, связанным с вычислительной техникой. Но она будет также полезна всем, чья деятельность так или иначе касается разработки программного обеспечения.
Системное программное обеспечение. Лабораторный практикум — читать онлайн ознакомительный отрывок
Ниже представлен текст книги, разбитый по страницам. Система сохранения места последней прочитанной страницы, позволяет с удобством читать онлайн бесплатно книгу «Системное программное обеспечение. Лабораторный практикум», без необходимости каждый раз заново искать на чём Вы остановились. Поставьте закладку, и сможете в любой момент перейти на страницу, на которой закончили чтение.
Интервал:
Закладка:
На основании отношений предшествования строят матрицу предшествования грамматики. Строки матрицы предшествования помечаются первыми (левыми) символами, столбцы – вторыми (правыми) символами отношений предшествования. В клетки матрицы на пересечении соответствующих столбца и строки помещаются знаки отношений. При этом пустые клетки матрицы говорят о том, что между данными символами нет ни одного отношения предшествования.
Существует несколько видов грамматик предшествования. Они различаются по тому, какие отношения предшествования в них определены и между какими типами символов (терминальными или нетерминальными) могут быть установлены эти отношения. Кроме того, возможны незначительные модификации функционирования самого алгоритма «сдвиг-свертка» в распознавателях для таких грамматик (в основном на этапе выбора правила для выполнения свертки, когда возможны неоднозначности) [1].
Выделяют следующие виды грамматик предшествования:
• простого предшествования;
• расширенного предшествования;
• слабого предшествования;
• смешанной стратегии предшествования;
• операторного предшествования.
Далее будут рассмотрены ограничения на структуру правил и алгоритмы разбора для грамматик операторного предшествования.
Матрицу операторного предшествования КС-грамматики можно построить, опираясь непосредственно на определения отношений предшествования [1, 3, 7], но проще и удобнее воспользоваться двумя дополнительными типами множеств – множествами крайних левых и крайних правых символов, а также множествами крайних левых терминальных и крайних правых терминальных символов для всех нетерминальных символов грамматики.
Если имеется КС-грамматика
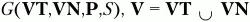
то множества крайних левых и крайних правых символов определяются следующим образом:
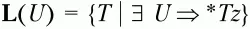
– множество крайних левых символов относительно нетерминального символа U;
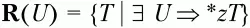
– множество крайних правых символов относительно нетерминального символа U,
где U – заданный нетерминальный символ
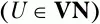
T – любой символ грамматики
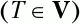
а z – произвольная цепочка символов (
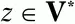
цепочка z может быть и пустой цепочкой).
Множества крайних левых и крайних правых терминальных символов определяются следующим образом:
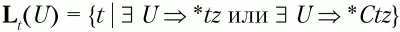
– множество крайних левых терминальных символов относительно нетерминального символа U;
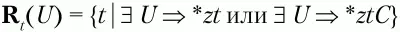
– множество крайних правых терминальных символов относительно нетерминального символа U,
где t – терминальный символ
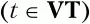
U и С – нетерминальные символы (U,

а z – произвольная цепочка символов (
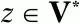
цепочка z может быть и пустой цепочкой).
Множества L(U) и R(U) могут быть построены для каждого нетерминального символа
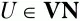
по очень простому алгоритму:
1. Для каждого нетерминального символа U ищем все правила, содержащие U в левой части. Во множество L(U) включаем самый левый символ из правой части правил, а во множество R(U) – самый правый символ из правой части (то есть во множество L(U) записываем все символы, с которых начинаются правила для символа U, а во множество R(U) – символы, которыми эти правила заканчиваются). Если в правой части правила для символа U имеется только один символ, то он должен быть записан в оба множества – L(U) и R(U).
2. Для каждого нетерминального символа U выполняем следующее преобразование: если множество L(U) содержит нетерминальные символы грамматики [U', U', …, то его надо дополнить символами, входящими в соответствующие множества L(U'), L(U')… и не входящими в L(U). Ту же операцию надо выполнить для R(U). Фактически, если какой-то символ U' входит в одно из множеств для символа U, то надо объединить множества для U' и U, а результат записать во множество для символа U.
Читать дальшеИнтервал:
Закладка:
Похожие книги на «Системное программное обеспечение. Лабораторный практикум»
Представляем Вашему вниманию похожие книги на «Системное программное обеспечение. Лабораторный практикум» списком для выбора. Мы отобрали схожую по названию и смыслу литературу в надежде предоставить читателям больше вариантов отыскать новые, интересные, ещё непрочитанные произведения.









Обсуждение, отзывы о книге «Системное программное обеспечение. Лабораторный практикум» и просто собственные мнения читателей. Оставьте ваши комментарии, напишите, что Вы думаете о произведении, его смысле или главных героях. Укажите что конкретно понравилось, а что нет, и почему Вы так считаете.