Алексей Молчанов - Системное программное обеспечение. Лабораторный практикум
Здесь есть возможность читать онлайн «Алексей Молчанов - Системное программное обеспечение. Лабораторный практикум» — ознакомительный отрывок электронной книги совершенно бесплатно, а после прочтения отрывка купить полную версию. В некоторых случаях можно слушать аудио, скачать через торрент в формате fb2 и присутствует краткое содержание. Город: Санкт-Петербург, Год выпуска: 2005, ISBN: 2005, Издательство: Array Издательство «Питер», Жанр: Программирование, на русском языке. Описание произведения, (предисловие) а так же отзывы посетителей доступны на портале библиотеки ЛибКат.

- Название:Системное программное обеспечение. Лабораторный практикум
- Автор:
- Издательство:Array Издательство «Питер»
- Жанр:
- Год:2005
- Город:Санкт-Петербург
- ISBN:978-5-469-00391-4
- Рейтинг книги:4 / 5. Голосов: 2
-
Избранное:Добавить в избранное
- Отзывы:
-
Ваша оценка:
Системное программное обеспечение. Лабораторный практикум: краткое содержание, описание и аннотация
Предлагаем к чтению аннотацию, описание, краткое содержание или предисловие (зависит от того, что написал сам автор книги «Системное программное обеспечение. Лабораторный практикум»). Если вы не нашли необходимую информацию о книге — напишите в комментариях, мы постараемся отыскать её.
Книга ориентирована на студентов, обучающихся в технических вузах по специальностям, связанным с вычислительной техникой. Но она будет также полезна всем, чья деятельность так или иначе касается разработки программного обеспечения.
Системное программное обеспечение. Лабораторный практикум — читать онлайн ознакомительный отрывок
Ниже представлен текст книги, разбитый по страницам. Система сохранения места последней прочитанной страницы, позволяет с удобством читать онлайн бесплатно книгу «Системное программное обеспечение. Лабораторный практикум», без необходимости каждый раз заново искать на чём Вы остановились. Поставьте закладку, и сможете в любой момент перейти на страницу, на которой закончили чтение.
Интервал:
Закладка:
Описание конечного автомата для распознавания лексем входного языка
Задача лексического анализатора для описанного выше языка заключается в том, чтобы распознавать и выделять в исходном тексте программы все лексемы этого языка. Лексемами данного языка являются:
• шесть ключевых слов языка (if, then, else, or, xor и and);
• разделители: открывающая и закрывающая круглые скобки, точка с запятой;
• знак операции присваивания;
• идентификаторы;
• целые десятичные константы без знака.
Кроме перечисленных лексем распознаватель должен уметь определять и исключать из входного текста комментарии, принцип построения которых описан выше. Для выделения комментариев ключевыми символами должны быть открывающая и закрывающая фигурные скобки.
Для перечисленных типов лексем и комментария можно построить регулярную грамматику, а затем на ее основе создать КА. Однако построенная таким образом грамматика, с одной стороны, будет элементарно простой, с другой стороны – громоздкой и малоинформативной. Поэтому можно пойти путем построения КА непосредственно по описанию лексем. Для этого не хватает только описания идентификаторов и целых десятичных констант без знака:
• идентификатор – это произвольная последовательность малых и прописных букв латинского алфавита (от А до Z и от а до z), цифр (от 0 до 9) и знака подчеркивания (_), начинающаяся с буквы или со знака подчеркивания;
• целое десятичное число без знака – это произвольная последовательность цифр (от 0 до 9), начинающаяся с любой цифры.
Границами лексем для данного распознавателя будут служить пробел, знак табуляции, знаки перевода строки и возврата каретки, а также круглые скобки, открывающая фигурная скобка, точка с запятой и знак двоеточия. При этом следует помнить, что круглые скобки и точка с запятой сами по себе являются лексемами, открывающая фигурная скобка начинает комментарий, а знак двоеточия, являясь границей лексемы, в то же время является и началом другой лексемы – операции присваивания.
В данном языке лексический анализатор всегда может однозначно определить границы лексемы, поэтому нет необходимости в его взаимодействии с синтаксическим анализатором и другими элементами компилятора.
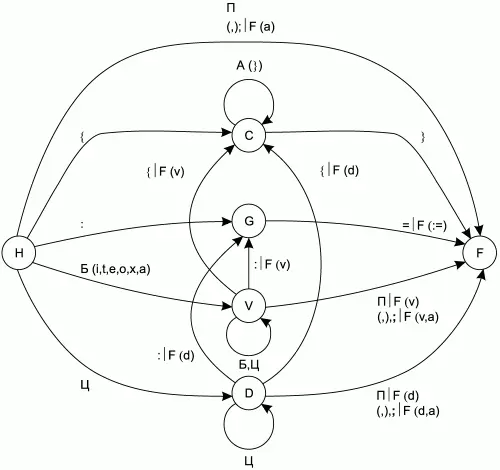
Рис. 2.1. Фрагмент графа переходов КА для распознавания всех лексем, кроме ключевых слов.
Полный граф переходов КА будет очень громоздким и неудобным для просмотра, поэтому проиллюстрируем его несколькими фрагментами. На рис. 2.1 изображен фрагмент графа переходов КА, отвечающий за распознавание разделителей, комментариев, знака присваивания, переменных и констант (всех лексем входного языка, кроме ключевых слов).
На рис. 2.2 изображен фрагмент графа переходов КА, отвечающий за распознавание ключевых слов if и then (этот фрагмент имеет ссылки на состояния, изображенные на рис. 2.1). Аналогичные фрагменты можно построить и для других ключевых слов.
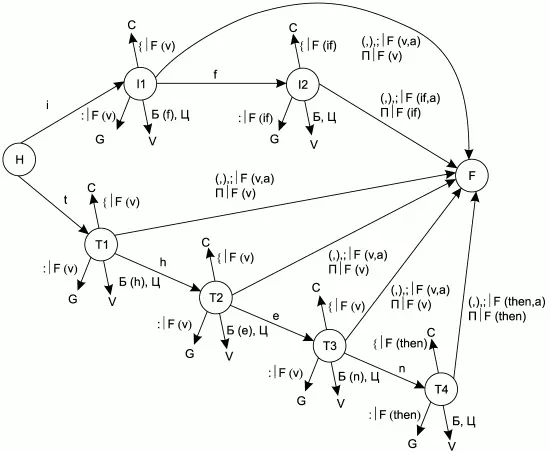
Рис. 2.2. Фрагмент графа переходов КА для ключевых слов if и then.
На фрагментах графа переходов КА, изображенных на рис. 2.1 и 2.2, приняты следующие обозначения:
• А– любой алфавитно-цифровой символ;
• А(*) – любой алфавитно-цифровой символ, кроме перечисленных в скобках;
• П– любой незначащий символ (пробел, знак табуляции, перевод строки, возврат каретки);
• Б– любая буква английского алфавита (прописная или строчная) или символ подчеркивания (_);
• Б(*) – любая буква английского алфавита (прописная или строчная) или символ подчеркивания (_), кроме перечисленных в скобках;
• Ц– любая цифра от 0 до 9;
• F – функция обработки таблицы лексем, вызываемая при переходе КА из одного состояния в другое. Обозначения ее аргументов:
– v – переменная, запомненная при работе КА;
– d – константа, запомненная при работе КА;
– a – текущий входной символ КА.
С учетом этих обозначений, полностью КА можно описать следующим образом:
M(Q,Σ,δ,q 0,F):
Q = {H, C, G, V, D, I1, I2, T1, T2, T3, T4, E1, E2, E3, E4, O1, O2, X1, X2, X3, A1, A2, A3, F}
Σ = А (все допустимые алфавитно-цифровые символы);
q 0= H;
F = {F}.
Функция переходов (δ) для этого КА приведена в приложении 2.
Из начального состояния КА литеры «i», «t», «e», «o», «x» и «a» ведут в начало цепочек состояний, каждая из которых соответствует ключевому слову:
Читать дальшеИнтервал:
Закладка:
Похожие книги на «Системное программное обеспечение. Лабораторный практикум»
Представляем Вашему вниманию похожие книги на «Системное программное обеспечение. Лабораторный практикум» списком для выбора. Мы отобрали схожую по названию и смыслу литературу в надежде предоставить читателям больше вариантов отыскать новые, интересные, ещё непрочитанные произведения.









Обсуждение, отзывы о книге «Системное программное обеспечение. Лабораторный практикум» и просто собственные мнения читателей. Оставьте ваши комментарии, напишите, что Вы думаете о произведении, его смысле или главных героях. Укажите что конкретно понравилось, а что нет, и почему Вы так считаете.