Роберт Мартин - Чистый код. Создание, анализ и рефакторинг
Здесь есть возможность читать онлайн «Роберт Мартин - Чистый код. Создание, анализ и рефакторинг» — ознакомительный отрывок электронной книги совершенно бесплатно, а после прочтения отрывка купить полную версию. В некоторых случаях можно слушать аудио, скачать через торрент в формате fb2 и присутствует краткое содержание. Город: СПб., Год выпуска: 2019, ISBN: 2019, Издательство: Питер, Жанр: Программирование, на русском языке. Описание произведения, (предисловие) а так же отзывы посетителей доступны на портале библиотеки ЛибКат.

- Название:Чистый код. Создание, анализ и рефакторинг
- Автор:
- Издательство:Питер
- Жанр:
- Год:2019
- Город:СПб.
- ISBN:978-5-4461-0960-9
- Рейтинг книги:3.73 / 5. Голосов: 22
-
Избранное:Добавить в избранное
- Отзывы:
-
Ваша оценка:
Чистый код. Создание, анализ и рефакторинг: краткое содержание, описание и аннотация
Предлагаем к чтению аннотацию, описание, краткое содержание или предисловие (зависит от того, что написал сам автор книги «Чистый код. Создание, анализ и рефакторинг»). Если вы не нашли необходимую информацию о книге — напишите в комментариях, мы постараемся отыскать её.
Эта книга посвящена хорошему программированию. Она полна реальных примеров кода. Мы будем рассматривать код с различных направлений: сверху вниз, снизу вверх и даже изнутри. Прочитав книгу, вы узнаете много нового о коде. Более того, вы научитесь отличать хороший код от плохого. Вы узнаете, как писать хороший код и как преобразовать плохой код в хороший.
Книга состоит из трех частей. В первой части излагаются принципы, паттерны и приемы написания чистого кода; приводится большой объем примеров кода. Вторая часть состоит из практических сценариев нарастающей сложности. Каждый сценарий представляет собой упражнение по чистке кода или преобразованию проблемного кода в код с меньшим количеством проблем. Третья часть книги – концентрированное выражение ее сути. Она состоит из одной главы с перечнем эвристических правил и «запахов кода», собранных во время анализа. Эта часть представляет собой базу знаний, описывающую наш путь мышления в процессе чтения, написания и чистки кода.
Примечание верстальщика:
Чистый код. Создание, анализ и рефакторинг — читать онлайн ознакомительный отрывок
Ниже представлен текст книги, разбитый по страницам. Система сохранения места последней прочитанной страницы, позволяет с удобством читать онлайн бесплатно книгу «Чистый код. Создание, анализ и рефакторинг», без необходимости каждый раз заново искать на чём Вы остановились. Поставьте закладку, и сможете в любой момент перейти на страницу, на которой закончили чтение.
Интервал:
Закладка:
Вертикальное форматирование
Начнем с вертикальных размеров. Насколько большим должен быть исходный файл? В Java размер файла тесно связан с размером класса. Мы поговорим о размерах классов, когда речь пойдет о классах, а пока давайте займемся размером файлов.
Насколько большими должны быть исходные файлы Java? Оказывается, существует широчайший диапазон размеров и весьма заметные различия в стиле. Некоторые из этих различий показаны на рис. 5.1.
На рисунке изображены семь разных проектов: Junit, FitNesse, TestNG, Time and Money (Tam), JDepend, Ant и Tomcat. Отрезки, проходящие через прямоугольники, показывают минимальную и максимальную длину файла в каждом проекте. Прямоугольник изображает приблизительно одну треть (стандартное отклонение [22] Прямоугольник представляет диапазон «сигма/2» выше и ниже среднего значения. Да, я знаю, что распределение длин файлов не является нормальным, поэтому стандартное отклонение не может считаться математически точным. Но я и не стремлюсь к точности. Я хочу лишь дать представление о происходящем.
) от диапазона длин файлов. Середина прямоугольника соответствует среднему арифметическому. Таким образом, средний размер файла в проекте FitNesse составляет около 65 строк, а около трети файлов имеет размер от 40 до 100+ строк. Наибольший файл FitNesse занимает около 400 строк, а наименьший — всего 6 строк. Обратите внимание: на графике используется логарифмическая шкала, поэтому незначительные изменения в вертикальной координате подразумевают очень большие изменения в абсолютном размере.
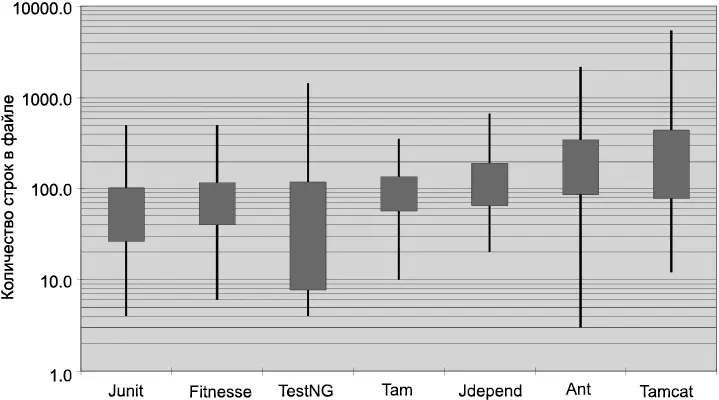
Рис. 5.1.Распределение длин файлов по логарифмической шкале (высота прямоугольника = сигма)
Junit, FitNesse и Time and Money состоят из относительно небольших файлов. Ни один размер файла не превышает 500 строк, а большинство файлов не превышает 200 строк. Напротив, в Tomcat и Ant встречаются файлы из нескольких тысяч строк, а около половины имеет длину более 200 строк.
Что это означает для нас? То, что достаточно серьезную систему (объем FitNesse приближается к 50 000 строк) можно построить из файлов, типичная длина которых составляет 200 строк, с верхним пределом в 500 строк. Хотя это не должно считаться раз и навсегда установленным правилом, такие показатели весьма желательны. Маленькие файлы обычно более понятны, чем большие.
Газетная метафора
Представьте себе хорошо написанную газетную статью. Естественно, статья читается по вертикали. В самом начале обычно располагается заголовок с общей темой статьи; он помогает вам решить, представляет ли статья интерес для вас. В первом абзаце приводится краткое изложение сюжета на уровне общих концепций, без приведения каких-либо подробностей. По мере продвижения к концу статьи объем детализации непрерывно растет, пока вы не узнаете все даты, имена, цитаты и т.д.
Исходный файл должен выглядеть как газетная статья. Имя файла должно быть простым, но содержательным. Одного имени должно быть достаточно для того, чтобы читатель понял, открыл ли он нужный модуль или нет. Начальные блоки исходного файла описывают высокоуровневые концепции и алгоритмы. Степень детализации увеличивается при перемещении к концу файла, а в самом конце собираются все функции и подробности низшего уровня в исходном файле.
Газета состоит из множества статей, в большинстве своем очень коротких. Другие статьи чуть длиннее. И лишь немногие статьи занимают всю газетную страницу. Собственно, именно этим газеты так удобны. Если бы они состояли из одной длинной статьи с неупорядоченной подборкой фактов, дат и имен, то мы бы просто не смогли их читать.
Вертикальное разделение концепций
Практически весь код читается слева направо и сверху вниз. Каждая строка представляет выражение или условие, а каждая группа строк представляет законченную мысль. Эти мысли следует отделять друг от друга пустыми строками.
Для примера возьмем листинг 5.1. Объявление пакета, директива(-ы) импорта и все функции разделяются пустыми строками. Это чрезвычайно простое правило оказывает глубокое воздействие на визуальную структуру кода. Каждая пустая строка становится зрительной подсказкой, указывающей на начало новой самостоятельной концепции. В ходе просмотра листинга ваш взгляд привлекает первая строка, следующая за пустой строкой.
package fitnesse.wikitext.widgets;
Интервал:
Закладка:
Похожие книги на «Чистый код. Создание, анализ и рефакторинг»
Представляем Вашему вниманию похожие книги на «Чистый код. Создание, анализ и рефакторинг» списком для выбора. Мы отобрали схожую по названию и смыслу литературу в надежде предоставить читателям больше вариантов отыскать новые, интересные, ещё непрочитанные произведения.












Обсуждение, отзывы о книге «Чистый код. Создание, анализ и рефакторинг» и просто собственные мнения читателей. Оставьте ваши комментарии, напишите, что Вы думаете о произведении, его смысле или главных героях. Укажите что конкретно понравилось, а что нет, и почему Вы так считаете.